






摘要
本周阅读了双多尺度去雾网络论文,Dual Multi-Scale Dehazing Network(DMDN)是一种用于图像去雾的深度学习网络。这个网络旨在处理受雾影响的图像,以提高图像的可见度和清晰度。去雾是计算机视觉领域中的一个重要任务,因为雾霾或大气散射会导致图像变得模糊和低对比度。DMDN 的设计采用了双重多尺度的结构,以更有效地捕捉图像中的各种细节和特征。它通常包含多个卷积神经网络(CNN)层,用于学习图像中的复杂模式和信息。通过在不同尺度上操作,DMDN能够更好地还原由雾霾引起的图像失真。
ABSTRACT
This week, I read the paper on Dual Multi-Scale Dehazing Network (DMDN). Dual Multi-Scale Dehazing Network (DMDN) is a deep learning network used for image dehazing. This network aims to process images affected by haze to improve the visibility and clarity of the image. Dehazing is an important task in the field of computer vision, because haze or atmospheric scattering can cause images to become blurred and low contrast. The design of DMDN adopts a dual multi-scale structure to more effectively capture various details and features in the image. It usually contains multiple Convolutional Neural Network (CNN) layers used to learn complex patterns and information in the image. By operating on different scales, DMDN can better restore image distortion caused by haze.
文献阅读
文献链接:Dual Multi-Scale Dehazing Network
文献摘要
单图像去雾是一个具有挑战性的不适定问题。最近,基于合成数据训练的方法取得了良好的去雾效果。然而,我们注意到这些方法还可以进一步改进。本文提出了一种基于深度学习的新方法,以获得更好的单图像去雾结果。特别地,我们提出了一个双多尺度网络来从综合数据中学习去雾知识。粗略的多尺度网络被设计为捕获多种对象,然后细的多尺度块被设计为捕获每个尺度的少量对象。为了证明所提出方法的有效性,我们在合成数据集和真实模糊图像上进行了实验。大量的实验结果表明,所提出的方法优于最先进的方法。
背景
大气中的混浊介质常常会降低图像质量。在恶劣天气下拍摄的户外图像往往会呈现出朦胧和模糊的外观。大气吸收和散射会导致雾霾,从而降低室外图像的对比度并使颜色褪色。相机从场景物体到达的光沿着视线衰减并与大气光混合。吸收和散射过程通常通过直接衰减和空气光的线性组合来建模 [1]:
I
(
x
)
=
J
(
x
)
t
(
x
)
+
A
(
1
−
t
(
x
)
)
.
.
.
.
.
.
.
.
(
1
)
I (x) = J (x) t (x) + A (1 − t (x))........( 1)
I(x)=J(x)t(x)+A(1−t(x))........(1)
其中
I
I
I是输入的有雾图像,
J
J
J是对应的干净图像,t表示相机接收到多少物体反射的光,A是空气光。单图像去雾旨在尽可能地去除单张输入图像中的雾气,具有广泛的应用,例如自动驾驶、语义分割、图像识别等。由于其广泛的应用,去雾受到了广泛的关注 。去雾过程有两个关键步骤:1)传输图的估计和大气光,2) 计算最终的去雾结果。基于先验的方法已经被提出来基于两个去雾步骤来去除雾霾。由于先验是基于简单的统计规律,实际案例无法满足。例如,暗通道先验(DCP)不能很好地处理白色物体。
受到数据驱动方法成功的启发,许多研究人员提出了用于单图像去雾的端到端 CNN 模型。尽管这些方法已在合成数据集上显示出有效性。然而,由于雾霾造成的大范围任意性,这些方法都存在局限性。此外,雾度的分布取决于深度,需要不同的感受野大小来估计每个像素的深度。为了共同克服这两个问题,作者提出了一种双多尺度去雾网络。雾霾的形成受到温度、海拔、湿度等多种因素的影响,使得雾霾在各个空间位置的分布具有空间差异和非均匀性。为了捕捉雾霾的分布,作者提出了一种双多尺度去雾网络,它具有不同的感知领域并捕捉不同尺寸的物体。作者的方法与传统的和基于学习的方法进行比较,如图1所示。这项工作的主要贡献如下:

- 作者提出了一种双多尺度去雾网络,可以捕获大大小小的各种物体并了解雾霾的分布。雾霾的分布非常大,我们采用粗略的多尺度网络来捕获全球雾霾分布。然后,我们通过精细的多尺度块捕获雾霾的小范围分布。该模型可以很好地捕捉雾霾的全局和局部分布,有效提高去雾性能。
- 作者提出了一种精细的多尺度块,它可以捕获小种类的物体。雾度的分布取决于深度,对于不同的物体来说雾度的分布是不同的。然而,一个物体内的雾度分布往往表现出均匀性。设计一个能够捕获每个尺度的小范围物体大小的网络至关重要,这促使作者设计一个精细的多尺度块。
- 作者进行了广泛的实验,以定量和定性地比较所提出的方法与最先进的单图像去雾方法,并证明所提出模型的有效性。
单图像去雾方法主要可分为两种方法:基于物理模型的恢复方法和基于颜色信息的增强方法。
单图像去雾方法基于物理模型的方法。
假设模糊图像可以通过等式1建模。
(1)它将模糊图像建模为干净图像和大气光的线性。干净的图像是指不受介质粒子影响的场景信息。基于该模型,大多数现有算法侧重于恢复未到达相机传感器的场景,即估计每个模糊图像的传输图
t
(
x
)
t(x)
t(x)。模糊图像可以被视为恒定反照率的区域,我们可以从模糊图像推断场景传输。暗通道先验(DCP)是根据非天空无雾图像的特征推断出来的。 DCP假设至少一个像素包含强度接近于零的通道。扩展了DCP并提出了更通用的边界约束。手工制作的先验是大量图像的统计属性,因此在实际场景中并不总是成立。例如,当场景物体靠近空气光时,暗通道在此类物体附近具有亮值,这意味着暗通道先验不成立,从而导致雾霾层被高估。
为了避免设计统计特征,一些算法采用深度卷积神经网络(CNN)来改善图像去雾。 DehazeNet和MSCNN都使用深度神经网络进行传输估计,然后按照常规方法估计大气光和无雾图像。 AOD-Net 没有单独计算传输图和大气光,而是将传输和空气光合并到一个新变量中,并设计了一种光去雾方法。然而,该方法在去雾结果中往往会保留雾度。 DCPDN[和DDN是将散射模型融入深度网络的两种方法。这些方法需要两个网络首先计算传输图和大气光,然后通过反转模型(1)来恢复最终的去雾图像。提出了一种基于端到端融合的去雾网络来预测权重图,通过选择其中最重要的特征将三个派生输入组合成一个。然而,GFN 还使用传统方法计算三个输入,并且需要计算中间置信图。秦等人。设计一种新颖的像素和通道关注来提高去雾性能。潘等人。设计一个基于物理的用于图像恢复问题的生成网络,它可以结合物理模型来提高去雾性能。董等人。采用增强策略设计多尺度去雾网络。郑等人。基于物理模型研究超高清图像去雾。尽管已经获得了有希望的结果,但模糊图像是干净图像和空气光之和的假设在真实的复杂场景中并不成立,特别是当雾霾很重并且包含噪声时。为了提高自然模糊图像的去雾性能,Shao 等人。提出一种域自适应去雾方法。与这些方法不同,作者的方法将多尺度能力纳入所提出的网络去雾中,并实现了快速去雾性能。
基于现有的去雾方法可以恢复去雾后的清晰结果,但代价是合成图像的定量结果较低。数据驱动的去雾方法可以获得合成图像的高定量结果,但不能完全去除真实有雾图像中的雾气。为了解决基于先验的去雾方法和数据驱动的去雾方法的缺点,提出了基于神经增强的去雾方法。基于神经增强的去雾方法首先估计大气光和传输图,然后使用数据驱动的方法来细化大气光和传输图。去雾结果是通过物理模型和估计的大气光和透射图获得的。
作者提出的方法
所提出的模型是一个双多尺度去雾网络,总体框架如图所示。双多尺度能力来自粗多尺度网络和细多尺度块。我们首先介绍动机,然后介绍双多尺度去雾网络,它从合成图像中学习去雾能力。
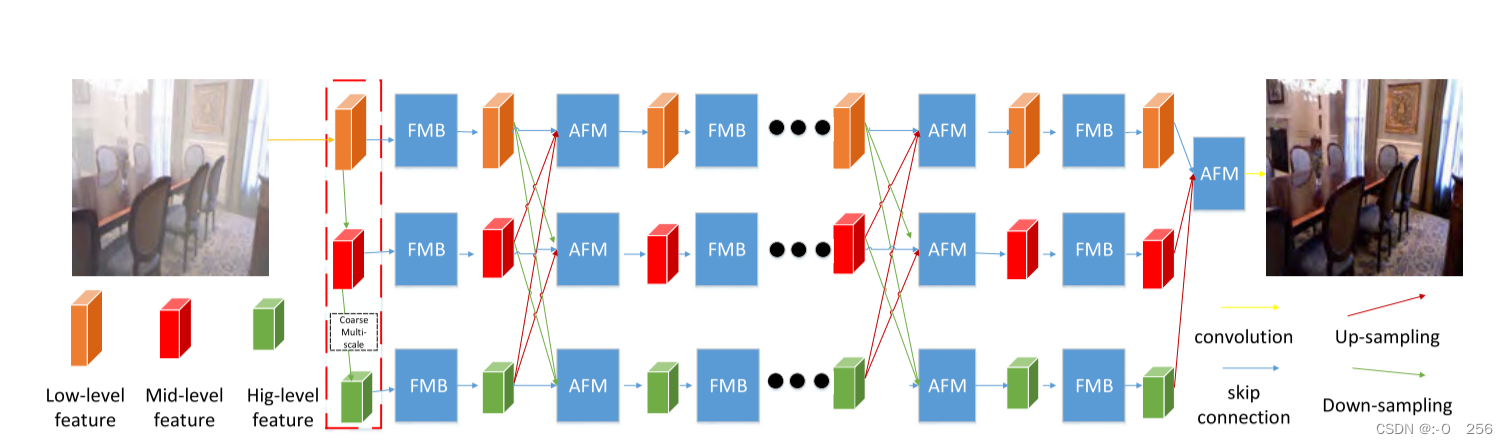
所提出的网络的架构。粗多尺度网络包含三个不同的尺度,用于捕获全局和局部信息。该网络的另一个核心是精细多尺度块,其设计目的是从多尺度特征中选择最重要的特征。自适应融合模块旨在融合来自粗略多尺度网络的多尺度特征。
双多尺度去雾网络
作者提出了一种双多尺度去雾网络(DMSDN),网络细节如图2所示。双多尺度去雾网络由粗多尺度网络和精细的多尺度块。粗略的多尺度网络包含三个尺度。第一个尺度(粗尺度)包含六个精细多尺度块,第二个尺度(中值尺度)包含六个精细多尺度块,第三个尺度包含六个精细多尺度块。为了捕获全局和局部特征,该模型采用三个尺度的信息来探索对去雾有用的特征。
由于学习到的特征图存在冗余信息,这是深度学习模型无法学习有效去雾特征的原因。为了提高学习效率,作者提出了一个精细的多尺度块。精细多尺度块(FMB)包含多尺度信息提取和注意力模块,如图4所示。根据观察,特征图包含冗余信息,对其应用卷积无法学习到尽可能多的信息。将特征拆分为四个子特征,其中包含原始特征的子信息。我们对一个子特征应用卷积,并获得一个新特征
(
O
1
)
(O_1)
(O1)。我们将
(
O
1
)
(O_1)
(O1) 与另一个子特征连接并获得连接特征
(
C
1
)
(C_1)
(C1),然后对
(
C
1
)
(C_1)
(C1) 应用卷积并获得新特征
(
O
1
)
(O_1)
(O1)。我们重复这个过程,得到
(
O
3
)
(O_3)
(O3)和
(
O
4
)
(O_4)
(O4)。我们连接
(
O
1
)
(O_1)
(O1)、
(
O
2
)
(O_2)
(O2)、
(
O
3
)
(O_3)
(O3) 和
(
O
4
)
(O_4)
(O4),然后对连接的特征应用通道注意力并获得用于去雾的活动特征。所提出的模块减少了计算时间和模型复杂性。

所提出的精细多尺度块(FMB)的架构。该块包含一个密集扩张块和一个通道注意块。密集扩张块被设计为提取多尺度信息,然后通道注意块从多尺度信息中选择最重要的信息。
为了进一步改善信息流,作者提出了一种自适应融合模块(AFM),它自适应地融合粗多尺度网络每个尺度的特征。如图所示,首先连接高层,中、低层特征,然后应用1×1核的卷积运算,得到融合特征。

所提出的自适应融合模块的架构。首先连接多尺度特征,然后使用卷积运算提取有效特征以进行去雾。
训练损失
令
F
F
F表示网络学习的映射函数, 表示网络的参数令
I
i
,
i
=
1
,
2
,
⋅
⋅
⋅
,
N
和
J
i
,
i
=
1
,
2
,
⋅
⋅
⋅
,
N
{I_i, i = 1, 2, ···, N}和{J_i, i = 1, 2,···, N}
Ii,i=1,2,⋅⋅⋅,N和Ji,i=1,2,⋅⋅⋅,N分别表示有雾的输入图像和相应的干净图像。人们普遍认为
L
2
L_2
L2损失往往会产生模糊的去雾结果 。为了有效地解决这个问题,我们引入了一种新颖的边缘保留损失,它由两个不同的部分组成:
L
1
L_1
L1损失和感知损失。
L
1
L_1
L1定义如下:
表示网络的参数令
I
i
,
i
=
1
,
2
,
⋅
⋅
⋅
,
N
和
J
i
,
i
=
1
,
2
,
⋅
⋅
⋅
,
N
{I_i, i = 1, 2, ···, N}和{J_i, i = 1, 2,···, N}
Ii,i=1,2,⋅⋅⋅,N和Ji,i=1,2,⋅⋅⋅,N分别表示有雾的输入图像和相应的干净图像。人们普遍认为
L
2
L_2
L2损失往往会产生模糊的去雾结果 。为了有效地解决这个问题,我们引入了一种新颖的边缘保留损失,它由两个不同的部分组成:
L
1
L_1
L1损失和感知损失。
L
1
L_1
L1定义如下:
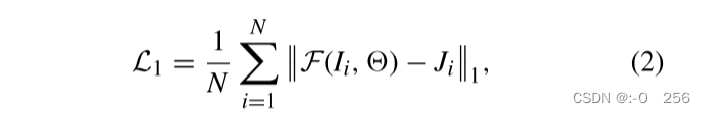
其中 N 是训练对数据的数量。为了消除去雾图像的视觉伪影,作者采用感知损失来训练模型。感知损失包括特征重建损失和风格重建损失。特征重建损失不是鼓励去雾图像 J 的像素与地面真实图像的像素完全匹配,而是鼓励它们具有相似的特征表示。知觉损失可以定义如下:
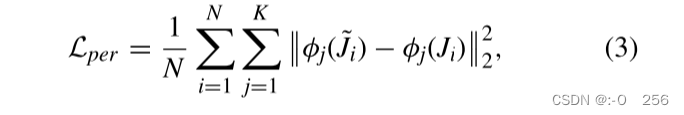
其中 φ 表示 VGG-19 网络,在 ImageNet 上训练,N 表示训练样本的数量,j 表示层数。我们选择 VGG19 网络中的层“conv1-2”、“conv2-2”、“conv3-2”、“conv4-2”和“conv5-2”来计算特征重建损失。我们的总体损失函数是:

其中
λ
2
λ_2
λ2 控制感知损失的贡献。
实验过程
在提出的模型中,作者将 3 × 3 设置为除 AFM 中的卷积层之外的所有卷积层的内核大小。在实验中,将尺度数设置为 3。对于每个尺度感知注意模块,将扩张率设置为 1、2、4 和 8。所有扩张层都使用身份初始化器进行初始化 。在所有实验中我们设置 λ 1 = 0.01 和 λ 2 = 0.01 λ_1=0.01和λ_2=0.01 λ1=0.01和λ2=0.01。使用泄漏整流线性单元(LReLU)作为我们的激活函数。使用 Adam 优化器( β 1 = 0.9 和 β 2 = 0.9999 β_1 = 0.9 和 β_2 = 0.9999 β1=0.9和β2=0.9999)来训练网络。批量大小和学习率分别为 1 和 0.0005。在训练过程中,每 30 个 epoch 将学习率降低一半。该网络使用 Nvidia GTX 2018Ti GPU 通过 Pytorch 进行了总共 100 个 epoch 的训练。在 RESIDE 的 SOTS 数据集上训练所提出的网络作为最先进的去雾方法 。
实验结果
实验中比较了几种最先进的方法,包括暗通道先验(DCP)、非局部去雾(NLD)、MSCNN 、AOD-Net 、门控融合网络( GFN) 、EPDN 、GridDehazeNet 、PhysicsGan 、FFA-Net 、MSBDN 、AirNet 和 Dehamer 在有雾图像上。
















 7089
7089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









