







目录
5.3、Part Affinity Fields(PAFs)
引言
本周阅读了一篇关于openpose的论文,本文提出了一种使用部分关联场(Part Affinity Fields)的方法,能够高效地检测图像中多个人的二维姿势。该方法通过学习将身体部位与图像中的个体关联起来,实现了全局上下文编码,并通过贪婪自底向上的解析步骤来保持高准确性并实现实时性能,无论图像中有多少人。在此基础上学习了yolov8的网络结构和代码,实现了对人体的检测和姿态估计。
Abstract
This week, I read a paper on openpose, which proposes a method using Part Affinity Fields to efficiently detect two-dimensional poses of multiple individuals in an image. This method associates body parts with individuals in the image through learning, achieving global context encoding, and maintaining high accuracy and real-time performance through greedy bottom-up parsing steps, regardless of how many people are in the image. On this basis, I learned the network structure and code of YOLOv8, and achieved human detection and pose estimation.
文献阅读
1、题目
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
2、引言
我们提出了一种方法来有效地检测图像中的多个人的2D姿态。该方法使用非参数表示,我们称之为部分亲和场(PAF),学习将身体部位与图像中的个体相关联。该架构对全局上下文进行编码,允许贪婪的自下而上的解析步骤,在实现实时性能的同时保持高准确性,而不管图像中的人数。该架构旨在通过同一顺序预测过程的两个分支共同学习零件位置及其关联。并且在性能和效率方面都大大超过了MPII MultiPerson基准测试的最新结果。
3、创新点
- 提出了一种实时方法来检测图像中多个人的2D姿势。所提出的方法使用非参数表示(称为部分亲和场(PAF))来学习将图像中的身体部位与个体相关联
- 仅使用PAF进行优化,而不是同时进行PAF和身体部位定位优化,运行时其性能和准确性均会得到大幅提高。
4、总体流程
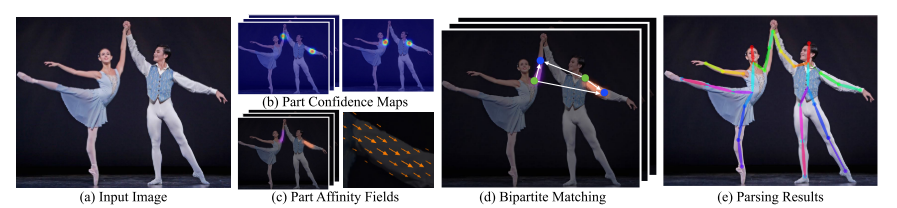
上图展示了整个流程,输入是w×h的彩色图片 (a),输出是二维的带有每个人的人体关键点位置的图像。首先是一个前馈网络,它同时预测出关于身体部分位置的二维置信图S (b)和一组关于部分亲和度的2D向量场L (c),其中二维向量域的集合 L 编码了部分的关联的程度。集合S具有J个置信度图,S =(S1,S2,...SJ),每个部分一个映射即。集合L=(L1,L2,...LC)有C个向量域,每个四肢对应一个向量域。(这里×2可能是因为向量表示起点和终点,起点在一个w×h中,重点在一个w×h中),LC中的每个图像位置编码一个2D矢量。最后,通过贪婪推理 (d)对置信度图和亲和域进行解析,以输出图像中所有人的2D关键点。
5、网络结构
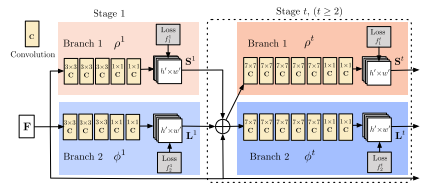
本文的网络结构如上图所示,整个网络是两个分支,多stage的卷积神经网络。其中第一个分支用来预测一个叫做confidence map的东西,可以看作是一个打分的map。而第二个分支用于预测本文提出的PAFs。每一个分支都有着多个stage,每个stage的输入是上一个stage两个branch的输出和最初的图像输入进行融合。
class rtpose_model(nn.Module):
def __init__(self, model_dict):
super(rtpose_model, self).__init__()
self.model0 = model_dict['block0']
self.model1_1 = model_dict['block1_1']
self.model2_1 = model_dict['block2_1']
self.model3_1 = model_dict['block3_1']
self.model4_1 = model_dict['block4_1']
self.model5_1 = model_dict['block5_1']
self.model6_1 = model_dict['block6_1']
self.model1_2 = model_dict['block1_2']
self.model2_2 = model_dict['block2_2']
self.model3_2 = model_dict['block3_2']
self.model4_2 = model_dict['block4_2']
self.model5_2 = model_dict['block5_2']
self.model6_2 = model_dict['block6_2']
model = rtpose_model(models)
return model# model初始化:加载模型
model = get_model(trunk='vgg19') # 可以换网络, elif trunk == 'mobilenet':
model = torch.nn.DataParallel(model).cuda()
# load pretrained
use_vgg(model) # 加载预训练模型。url = 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'最核心的部分:利用标注好的信息anns 来生成热图(heatmaps)和部件关联图(pafs)的真值信息。
vgg-19是3次下采样,假设输入的是368,那么采样后就是368/8=46
多了一个脖子外加一个背景
按照先后顺序来的,x和y来给你个方向,得到38个,[[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], [1, 2], [2, 3], [3, 4], [2, 14], [1, 5], [5, 6], [6, 7], [5, 15], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]
ef get_ground_truth(self, anns):
#vgg-19是3次下采样,假设输入的是368,那么采样后就是368/8=46
grid_y = int(self.input_y / self.stride)
grid_x = int(self.input_x / self.stride)
channels_heat = (self.HEATMAP_COUNT + 1)#19 HEATMAP_COUNT中coco给了17个,但是我们多了一个脖子所以18个,+1是背景所以是19
channels_paf = 2 * len(self.LIMB_IDS)#按照先后顺序来的,x和y来给你个方向,得到38个,[[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], [1, 2], [2, 3], [3, 4], [2, 14], [1, 5], [5, 6], [6, 7], [5, 15], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]
heatmaps = np.zeros((int(grid_y), int(grid_x), channels_heat))
pafs = np.zeros((int(grid_y), int(grid_x), channels_paf))#对于躯干来说,没有躯干的位置,向量为0,有躯干的地方为1
keypoints = []
# anns有多少list,就说明有多少个人,anns里面的num_keypoints表示每个人体部位关键点有被标注的个数,有些可能没标有些可能标了但是被遮挡了(也就是1)
# 第一个注释的"num_keypoints"为0,表示该注释中没有标记的关键点。第二个注释的"num_keypoints"为14,表示该注释中标记了14个关键点,等等等等
for ann in anns:
# 17种部位,3列(x,y,keypoint)
single_keypoints = np.array(ann['keypoints']).reshape(17, 3)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2094
2094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









