







这里主要是讲述分类问题。多分类问题是能够转化为二分类问题的。因此评价指标主要都是基于二分类来提出的。
1.混淆矩阵
- 优点:能够很好地包含了整体的分类结果信息
- 缺点:不直观,外行看不懂

2.准确度(Accuracy)
所有样本中被分类正确的比例。缺点就是不能衡量分布不均匀的情况。
计算时,分子就是混淆矩阵中对角线上的元素。

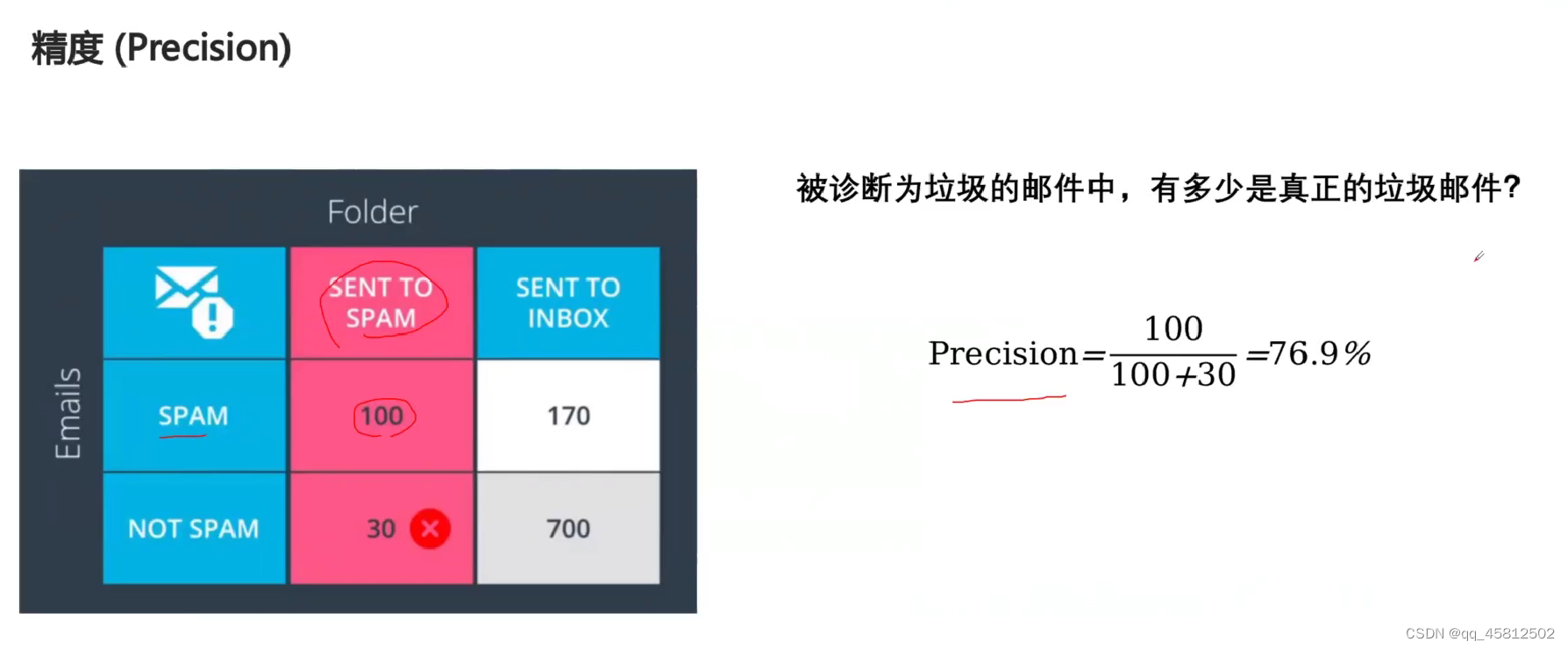
3. 精度(precison)
精确度也叫查准率,模型预测为正例的样本中,有多少位真正的正例。就是看模型对于我们所关注类别(也就是正例)预测的准确性。
计算就是考虑混淆矩阵的左边一列。
4.召回率(Recall)
也叫查全率。就是关注所有的实际正例中,有多少被预测准确的(就是数据集中有多少实际正例,能够被模型给找出来)。
计算是看混淆矩阵的上面一行。

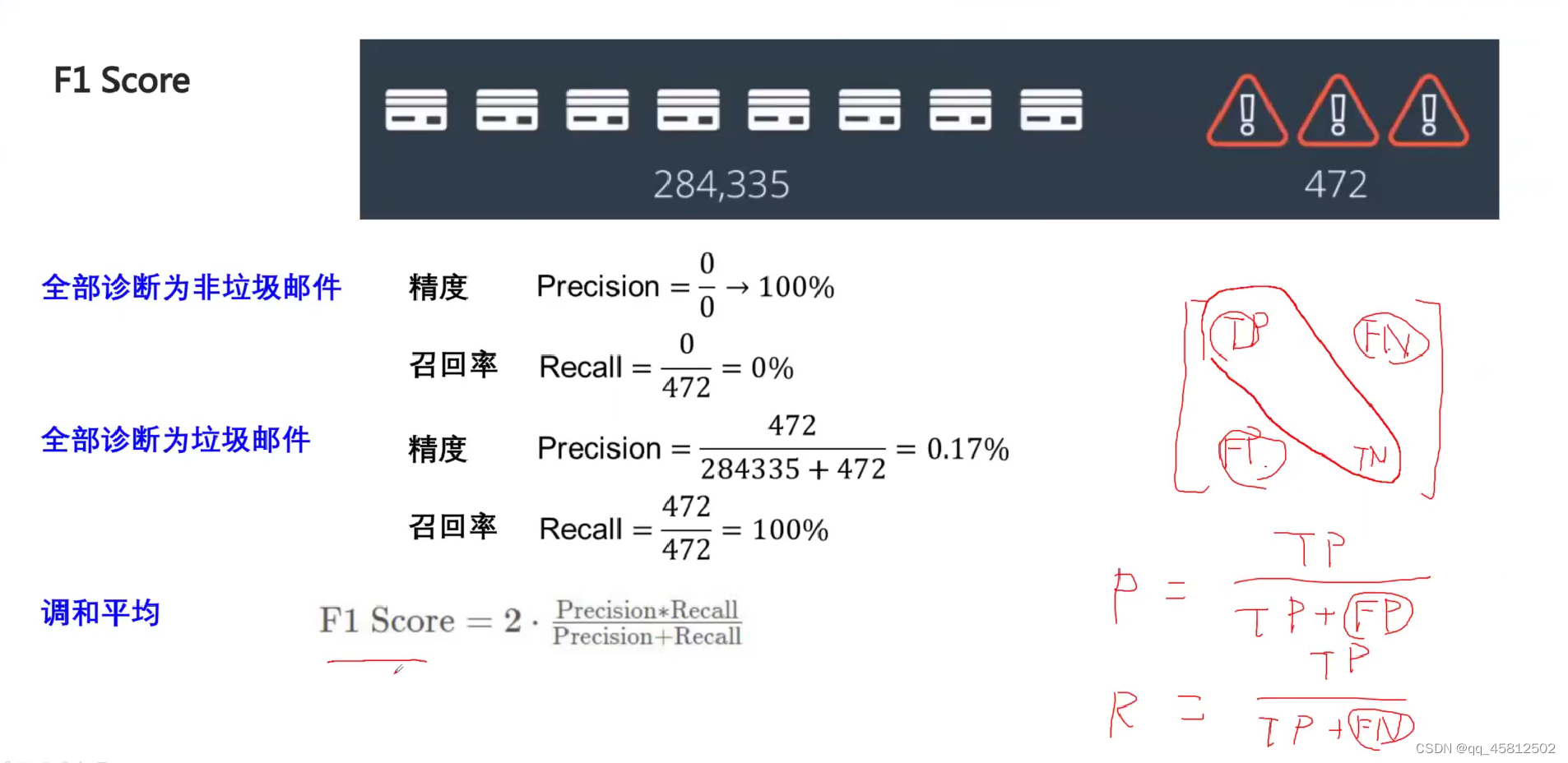
4.F1-score
F1 Score是对精度和召回率的调和平均。好处就是当precision和recall有一项接近于0时,f1的值都会接近于0。 当两者都比较高时,f1值就比较高。
一个好的模型就是要让TP和TN的占比更高(正对角线元素),FP和FN尽可能地少(负对角线)
F-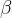 Score 和F2 Score
Score 和F2 Score
的不同取值让模型更具有倾向性。 取0.5时就更倾向于precision,就是让预测出来的尽可能都是正确的; 取2时就更倾向于recall,就是希望模型能够吧所有的实例都找到(可以忽略预测成本);取1就是没有倾向性。

5.多分类评价指标
多分类其实和二分类一样,也可以画出对应的混淆矩阵。例如右图中,正确预测的就是对角线上的。然后圈起来红色的2就是只实际标签为5模型预测出来为4的样本数。
















 5260
5260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









