







大家好,我是带我去滑雪!
本期使用R包mlbench的声纳数据Sonar作为案例来进行分析,该数据包含208个观测值与61个变量。其中,响应变量为因子Class,表示声纳回音是来自金属(记为M)还是岩石(记为R),特征变量共计60个,表示在不同角度与频道下,声纳反射信号的能量。研究目的是通过这些特征区分这些声纳信号是来自金属还是岩石。该案例参考陈强编写的《机器学习及R运用》。
1、安装相应数据包并查看数据结构
>install.packages("mlbench")
>library(mlbench)
> data(Sonar)
> str(Sonar)
'data.frame': 208 obs. of 61 variables:
$ V1 : num 0.02 0.0453 0.0262 0.01 0.0762 0.0286 0.0317 0.0519 0.0223 0.0164 ...
$ V2 : num 0.0371 0.0523 0.0582 0.0171 0.0666 0.0453 0.0956 0.0548 0.0375 0.0173 ...
$ V3 : num 0.0428 0.0843 0.1099 0.0623 0.0481 ...
$ V4 : num 0.0207 0.0689 0.1083 0.0205 0.0394 ...
$ V5 : num 0.0954 0.1183 0.0974 0.0205 0.059 ...
$ V6 : num 0.0986 0.2583 0.228 0.0368 0.0649 ...
...
$ V59 : num 0.009 0.0052 0.0095 0.004 0.0107 0.0051 0.0036 0.0048 0.0059 0.0056 ...
$ V60 : num 0.0032 0.0044 0.0078 0.0117 0.0094 0.0062 0.0103 0.0053 0.0022 0.004 ...
$ Class: Factor w/ 2 levels "M","R": 2 2 2 2 2 2 2 2 2 2 ...
> dim(Sonar)
[1] 208 61> table(Sonar$Class)
M R
111 97
在上述代码中,首先安装mlbench包,调入Sonar数据框,并查看了数据结构,单独考察了响应变 量Class的分别。结果显示,在样本中,声纳信号来自金属的次数略多余来自岩石。
2、划分测试集与训练集
>set.seed(1)
>train=sample(205,158)
由于本案例的样本量较少,只有208个,故本文随机抽取158个观测值作为模型的训练集,将剩下的50个观测值作为测试集。
3、使用修枝后的决策树
>install.packages("rpart")
>library(rpart)> set.seed(123)
> fit=rpart(Class~.,data=Sonar,subset=train)
> fit$cptable
CP nsplit rel error xerror xstd
1 0.52112676 0 1.0000000 1.0000000 0.08806471
2 0.08450704 1 0.4788732 0.5633803 0.07698110
3 0.04225352 3 0.3098592 0.5915493 0.07821080
4 0.02816901 4 0.2676056 0.6338028 0.07990217
5 0.01000000 5 0.2394366 0.6197183 0.07935821
> min_cp=0.01
> fit_best=prune(fit,cp=min_cp)
> pred=predict(fit_best,newdata=Sonar[-train,],type="class")
> y.test=Sonar[-train,"Class"]
> (table=table(pred,y.test))
y.test
pred M R
M 17 8
R 7 18> (error_rate=1-sum(diag(table))/sum(table))
[1] 0.3
结果显示,修枝后的最优决策树的预测错误概率为0.3。
4、逻辑回归
> fit=glm(Class~.,data=Sonar,subset=train,family=binomial)
> prob=predict(fit,newdata=Sonar[-train,],type="response")
> pred=prob>=0.5
> y.test=Sonar[-train,"Class"]
> (table=table(pred,y.test))
y.test
pred M R
FALSE 17 11
TRUE 7 15
> (error_rate=1-sum(diag(table))/sum(table))
[1] 0.36
结果显示,逻辑回归的预测错误概率为0.36。
5、随机森林
>install.packages("randomForest")
> library(randomForest)
> set.seed(123)
> fit=randomForest(Class~.,data=Sonar,subset=train,importance=TRUE)
> fitCall:
randomForest(formula = Class ~ ., data = Sonar, importance = TRUE, subset = train)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 7OOB estimate of error rate: 12.66%
Confusion matrix:
M R class.error
M 82 5 0.05747126
R 15 56 0.21126761
结果显示,函数randomForest()默认使用mtry=7个变量作为候选分裂变量,此为袋外误差为12.66%,金属的袋外误差为5.75%,岩石的袋外误差为21.23%。下面使用plot()函数将这三个袋外误差进行可视化:
> plot(fit,main="OOB Errors",col=c(4,1,1))
> legend("topright",colnames(fit$err.rate),lty=1:3,col=c(4,1,1))
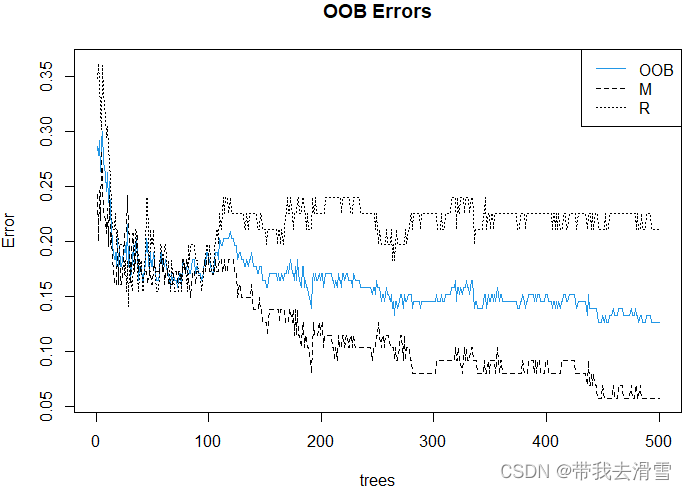
其中legend()的参数“colnames(fit$err.rate)”表示将fit$err.rate(包含上述三个袋外误差)的列名作为图列。蓝色的实线为整个样本的袋外误差,金属(M)的袋外误差下降最快。下面考察随机森林中变量的重要性:
>varImpPlot(fit,main="Variable Importance Plot")
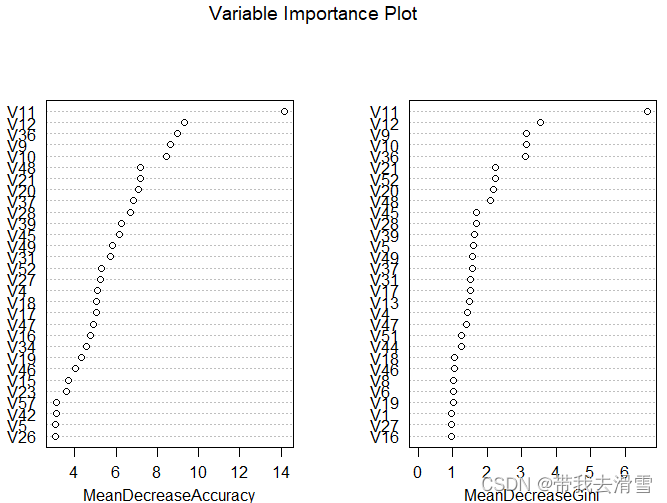
从平均递减精度和平均递减基尼数都可以看出,变量V11对响应变量Class的影响都最大,下面绘制影响最大变量V11的偏依赖图:
> partialPlot(fit,Sonar[train,],x.var = V11)
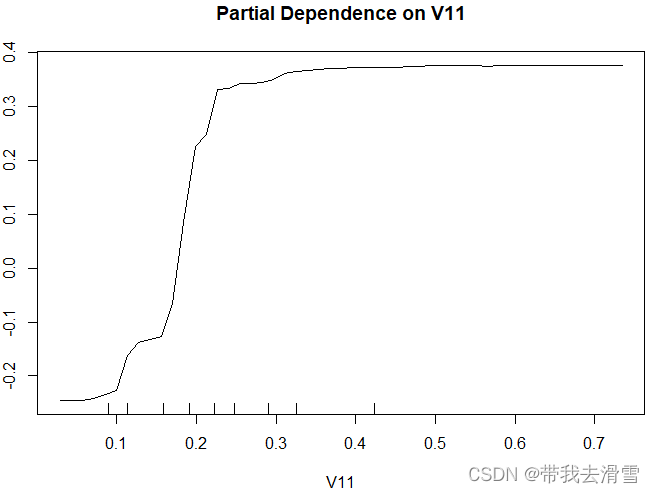
从偏依赖图中可以看出变量V11对响应变量Class的影响为正向,但结果并非完全线性,在V11的部分区域(横坐标0.4-0.7部分),变量V11对响应变量Class的影响几乎微弱(函数几乎变为水平线)。下面在测试集中进行随机森林预测:
> pred=predict(fit,newdata=Sonar[-train,])
> (table=table(pred,y.test))
y.test
pred M R
M 23 7
R 1 19
> (error_rate=1-sum(diag(table))/sum(table))
[1] 0.16
结果显示,随机森林的预测错误概率为0.16。
6、 三种方法预测效果比较
表1三种模型预测效果比较
| 模型 | 决策树 | 逻辑回归 | 随机森林 |
| 预测错误概率 | 0.3 | 0.36 | 0.16 |
通过表1可以看出,对于此案例,随机森林的预测效果要明显优于决策树和逻辑回归。
更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!

















 1801
1801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











