







文章目录
一、贝叶斯决策论
1.概率和统计
(1)概率(probability):已知一个模型和对应参数,预测该模型产生的结果及特性(如均值,方差,协方差等),即数据;
(2)统计(statistics):根据已有数据预测出模型及对应参数;
可知概率和统计要研究的目的是相反的;
2.概率函数和似然函数
对于函数
P
(
x
∣
θ
)
P\left( x|\theta \right)
P(x∣θ),有两个输入,
x
x
x表示某一个具体的数据,
θ
\theta
θ表示模型参数;那么有以下两种情况:
(1)
x
x
x变化,
θ
\theta
θ固定的情况下,相当于模型及参数固定,给出不同的样本
x
x
x,那么求出的是该
x
x
x出现的概率是多少,此为概率函数;
(2)
x
x
x固定,
θ
\theta
θ变化的情况下,求出的是对于不同的模型参数
θ
\theta
θ,出现x这个样本点的概率是多少,此为似然(likelihood)函数(可能性)。
3.贝叶斯公式
P
(
A
∣
B
)
=
P
(
A
)
P
(
B
∣
A
)
P
(
B
)
P\left( A|B \right) =\frac{P\left( A \right)P\left( B|A \right) }{P\left( B \right)}
P(A∣B)=P(B)P(A)P(B∣A)
贝叶斯公式中存在着一种事件发生的因果关系,若A是因,B是果,即A是导致B发生的原因之一; 那么:
- P ( A ∣ B ) P\left( A|B \right) P(A∣B)称为后验概率,是一种果因概率,即事件B已经发生后,是由A引起B发生的可能性有多大,可以理解为有多大把握能相信一件证据(或者说有多大的把握能确定是由A导致B发生的);
- P ( A ) P(A) P(A)称为先验(prior)概率,即能直接根据以往经验和分析得到的概率,如投一枚正常硬币,我们可以根据经验先验地知道正面朝上的概率是0.5;
- P ( B ∣ A ) P\left( B|A \right) P(B∣A)称为类条件概率(class-conditional probality),可以理解为如果 A A A发生,那么接下来 B B B发生的可能性有多大,如 A A A=‘今天是五一’, B B B=‘今天放假’,则 P ( B ∣ A ) = 1 P(B|A)=1 P(B∣A)=1;或者称为似然。
-
P
(
B
)
P(B)
P(B)是用于归一化的“证据”因子,即导致
B
B
B发生的所有可能性的集合,如
B
B
B=‘今天放假’,那么
P
(
B
)
P(B)
P(B)就是所有可能导致今天放假的可能性的集合,如今天是周末或者是五一等,对于某一个事件
B
B
B,通常P(B)是一个确定的值。
概率论与数理统计中关于全概率公式和贝叶斯公式中的解释:

- 从两个角度理解贝叶斯公式
(1)贝叶斯公式可化为:
P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ∣ A ) P ( A ) + P ( B ∣ ∼ A ) P ( ∼ A ) P\left( A|B \right) =\frac{P\left( A \right) P\left( B|A \right)}{P\left( B|A \right) P\left( A \right) +P\left( B|\sim A \right) P\left( \sim A \right)} P(A∣B)=P(B∣A)P(A)+P(B∣∼A)P(∼A)P(A)P(B∣A)
如果我们想说“今天放假,那么今天是五一”这个命题为真该怎么做呢,可以想到,只要令上述贝叶斯公式分母中的 P ( B ∣ ∼ A ) P ( ∼ A ) P\left( B|\sim A \right) P\left( \sim A \right) P(B∣∼A)P(∼A)为0即可,即排除掉引起放假的除五一外的其他可能因素;但是很明显,该命题为假,因为引起放假的因素不止五一节一种;
所以我们可以得出结论:做判断的时候,要考虑所有的因素。如今天放假,但是今天不一定是五一,更有可能是周末;
(2)从 P ( A ) P(A) P(A)的角度考虑:我们假设 A A A与 B B B密切相关,取极端情况令 P ( B ∣ A ) = 1 P(B|A)=1 P(B∣A)=1,即若 A A A发生,那么 B B B一定发生;可是即使是这种情况,若 P ( A ) P(A) P(A)太小,那么综合起来 P ( A ∣ B ) P(A|B) P(A∣B)也会很小;如对于那些百万彩票,一旦有人中了那么他当时必定就成为了百万富翁;但是实际上所有百万富翁中只有非常少的人中过百万彩票;所以我们可以知道,就算某个因素和结果强烈相关,但是当这个因素发生的概率很低时,我们就要慎重考虑,要想想是不是其他因素造成的。
4.贝叶斯决策论
贝叶斯决策论(Bayesian decision theory)是概率框架下实施决策的基本方法,考虑基于已知的相关概率和误判损失来选择最优的类别标记。
假设有N种可能的类别标记,即
y
=
{
c
1
,
c
2
,
.
.
.
,
c
N
}
y=\left\{ c_1,c_2,...,c_N \right\}
y={c1,c2,...,cN},
λ
i
j
\lambda _{ij}
λij是将一个真实标记为
c
j
{c_j}
cj的样本
x
x
x误分类为
c
i
c_i
ci所产生的期望损失(条件风险(conditional risk))
R
(
c
i
∣
x
)
=
∑
j
=
1
N
λ
i
j
P
(
c
j
∣
x
)
R\left( c_i|x \right) =\sum_{j=1}^N{\lambda _{ij}P\left( c_j|x \right)}
R(ci∣x)=j=1∑NλijP(cj∣x)
我们的目的是最小化条件风险,当
λ
i
j
=
{
0
,
i
f
i
=
j
1
,
o
t
h
e
r
w
i
s
e
\lambda _{ij}=\begin{cases} 0, if\,\,i\,\,=\,\,j\\ 1, otherwise\\ \end{cases}
λij={0,ifi=j1,otherwise
此时条件风险
R
(
c
∣
x
)
=
1
−
P
(
c
∣
x
)
R\left( c|x \right) =1-P\left( c|x \right)
R(c∣x)=1−P(c∣x),最小化分类错误率的贝叶斯最优分类器为
h
∗
(
x
)
=
a
r
g
max
c
∈
y
P
(
c
∣
x
)
h^*\left( x \right) =\underset{c\in y}{arg\max}P\left( c|x \right)
h∗(x)=c∈yargmaxP(c∣x)
即对每个样本
x
x
x,选择能使后验概率
P
(
c
∣
x
)
P(c|x)
P(c∣x)最大的类别标记。方法有极大似然估计和最大后验概率估计。
(该部分来自于西瓜书)
5.极大似然估计(MLE)和最大后验概率估计(MAP)

二、朴素贝叶斯分类器
1. 简介
对于后验概率P(c|x),类条件概率P(x|c)是所有属性上的联合概率,属性间存在影响;为了简化问题,朴素贝叶斯分类器假设所有属性间相互独立,即每个属性独立地对分类结果有影响
2.算法表示

3. 代码实现
离散属性与连续属性的训练要区分对待

连续属性:
import numpy as np#鸢尾花,三个类别,每个类均有50个样本
import random
import math
def data_split(data):#将原数据划分成含有120个样本的训练集,含有30个样本的测试集
data = data[1:]
train_ratio = 0.8
train_size = int(len(data) * train_ratio)
random.shuffle(data)
train_set = data[:train_size]
test_set = data[train_size:]
return train_set, test_set
def class_separate(data_set):#对数据进行处理,分类并统计
separated_data = {}
data_info = {}#表示的是各品种花所对应的数量
for data in data_set:
if data[-1] not in separated_data:#创建新字典索引,data和info两个字典都各自有三个索引,即花的品种
separated_data[data[-1]] = []
data_info[data[-1]] = 0
separated_data[data[-1]].append(data)#将所有花分成三类,每种花都会被添加进对应的花类别中
data_info[data[-1]] += 1
if 'Species' in separated_data:
del separated_data['Species']
if 'Species' in data_info:
del data_info['Species']
return separated_data, data_info
def prior_prob(data, data_info):#计算每个类的先验概率
data_prior_prob = {}
data_sum = len(data)
for cla, num in data_info.items():
data_prior_prob[cla] = num / float(data_sum)
return data_prior_prob
def mean(data):#求均值
data = [float(x) for x in data]#字符串转数字
return sum(data) / len(data)
def var(data):#求方差
data = [float(x) for x in data]
mean_data = mean(data)
var = sum([math.pow((x - mean_data), 2) for x in data]) / float(len(data) - 1)
return var
def prob_dense(x, mean, var):#由于是样本属性是连续值,所以要用概率密度
exponent = math.exp(math.pow((float(x) - mean), 2) / (-2 * var))
p = (1 / math.sqrt(2 * math.pi * var)) * exponent
return p
def attribute_info(data):#分别计算出四个属性的均值和方差
dataset = np.delete(data, -1, axis = 1) #删除标签
result = [(mean(att), var(att)) for att in zip(*dataset)]#zip解开元组,生成四个属性的结果
return result
def summarize_class(data):
data_separated, data_info = class_separate(data)
summarizeClass = {}
for index, x in data_separated.items():#三种类别对应4种属性,共12组,每组包含对应的均值和方差
summarizeClass[index] = attribute_info(x)
return summarizeClass
def cla_prob(test, summarizeClass):#此时summarizeClass就是三个类别的概率密度函数参数,即模型参数,test即测试数据(样本数据)
prob = {}
for cla, summary in summarizeClass.items():#cla类别,summary为该类对应的四个属性的(均值,方差)集合
prob[cla] = 1
for i in range(len(summary)):#属性个数
mean, var = summary[i]
x = test[i]
p = prob_dense(x, mean, var)#计算离散属性值的条件概率
prob[cla] *= p #连乘,最后得到这个类关于所有属性的条件概率
return prob#获得条件概率
def bayesian(input_data, data, data_info):#只需要考虑贝叶斯公式的分子,因为分母都是一样的,即只要考虑先验概率和条件概率
priorProb = prior_prob(data, data_info)
data_summary = summarize_class(data)
classProb = cla_prob(input_data, data_summary)
result = {}
for cla, prob in classProb.items():
# print(type(classProb))
p = prob * priorProb[cla]
result[cla] = p
return max(result, key=result.get)
iris = np.array(np.loadtxt("IrisData.csv", dtype=str, delimiter=",")).tolist()##导入鸢尾花数据,共有150个样本,其中有四个属性,3个类别(0,1,2),每个类别都有50个样本
train_set, test_set = data_split(iris)
train_separated, train_info = class_separate(train_set)#获得分类好的数据和每个类别的样本数
correct = 0
for x in test_set:
input_data = x[:-1]
label = x[-1]
result = bayesian(input_data, train_set, train_info)
if result == label:
correct += 1
print("precision:", correct / len(test_set))
训练结果:
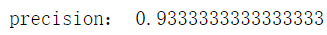















 1367
1367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









