







文章目录
0 前言
0.1 课程链接:
《PyTorch深度学习实践》完结合集
有大佬已经写好了笔记:大佬的笔记
pytorch=0.4
0.2 课件下载地址:
链接:https://pan.baidu.com/s/1_J1f5VSyYl-Jj2qIuc1pXw
提取码:wyhu

本节讲更高级的CNN(不是那种串行的CNN)
复习
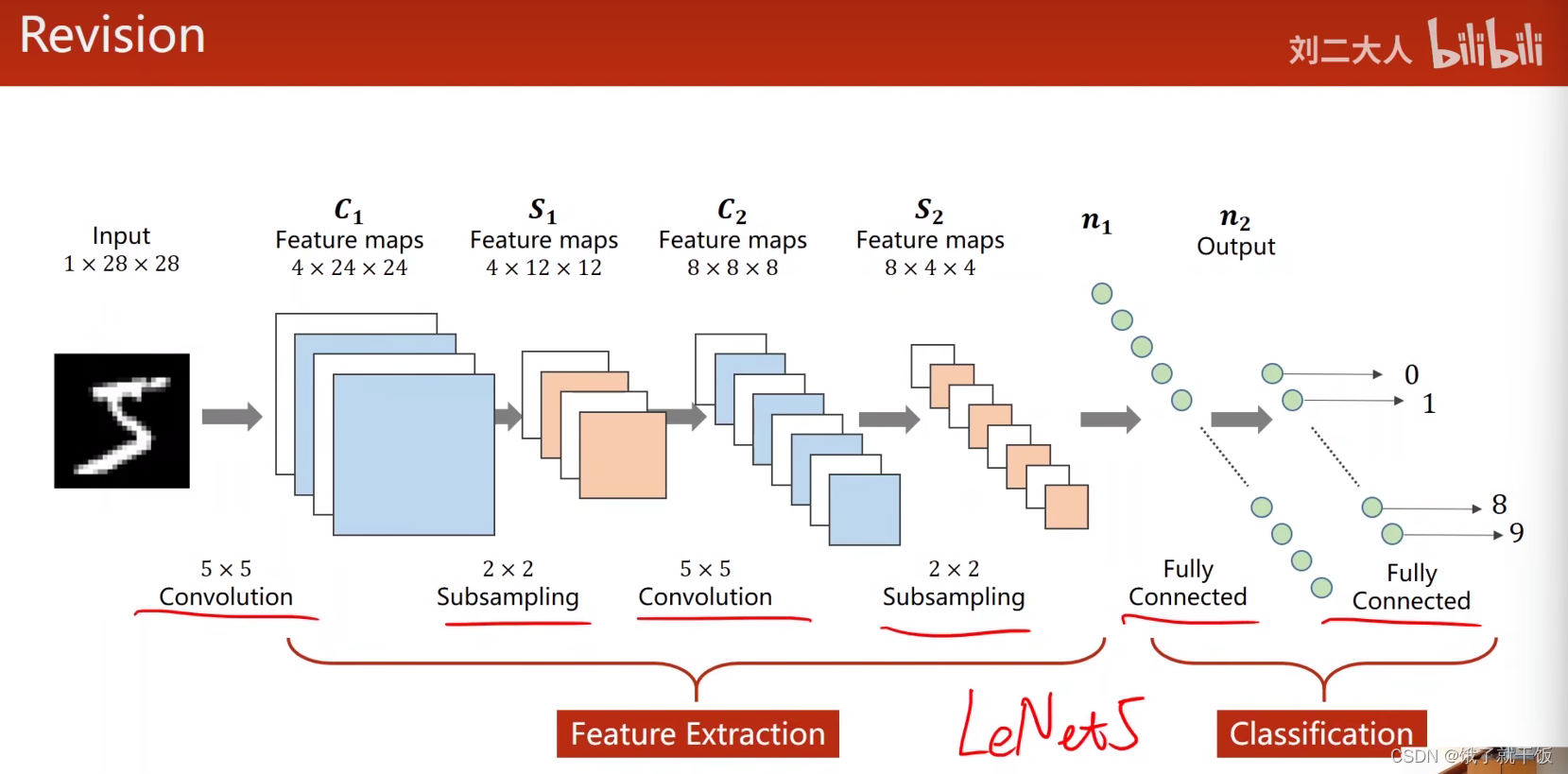
本节课讲两种网络:GoogleNet、
这么复杂的网络,如果是一层一层的定义,那么将会非常麻烦。要减少代码额度冗余,减少代码的重复,有两种方法可以用来减少:过程式的编程里面如C语言,使用函数来定义,在面向对象的编程里面如python,使用类来定义。
在复杂的网络中寻找相同的结构,如下:
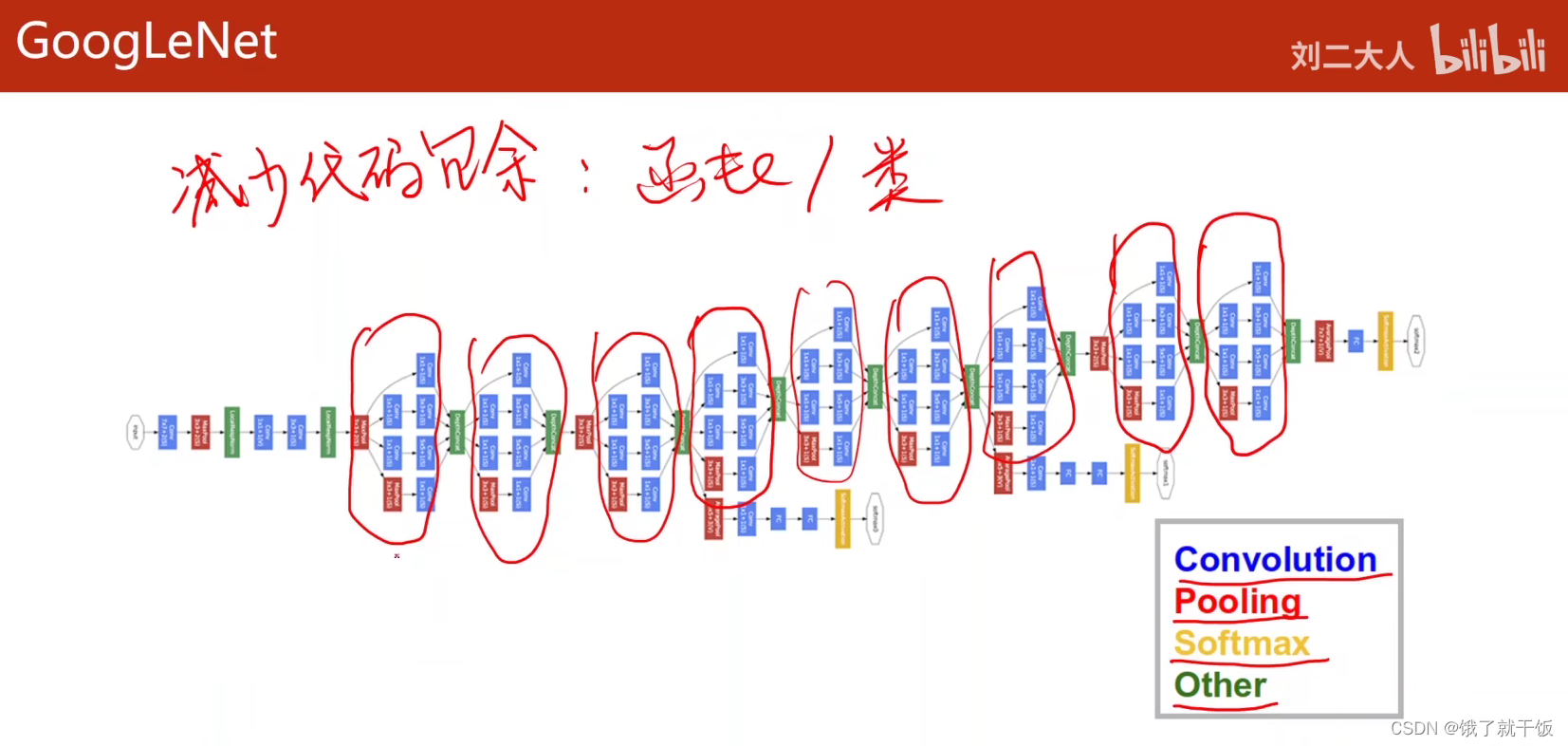
将这些相同的块封装成一个类,然后将这些块串联起来
在GoogLeNet中相同的块称为Inception(中文翻译为(机构、组织等的)开端,创始;),《盗梦空间》的中文翻译为《The Inception》,一个梦的上面套一个。
Inception Module的实现

这个模块是将多种类型的卷积方式都列出来,假如某一种卷积在提取图像的特征时比较重要,必然权重会比较突出。
什么是Concatenate?
把多种卷积的结果拼接起来
Average Pooling操作
通过改变padding和stride来使得输入图像和输出特征图的大小是不变的
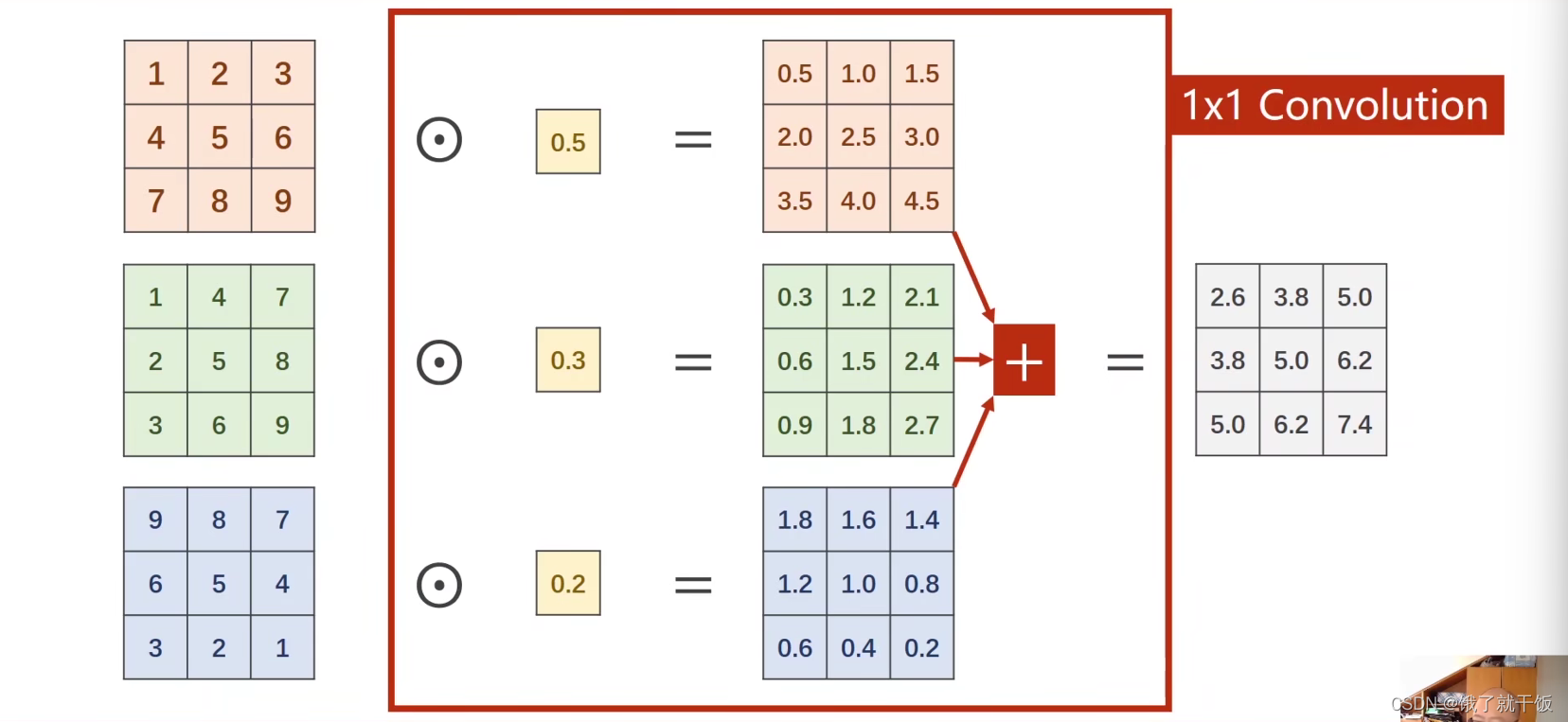
什么是1×1卷积?
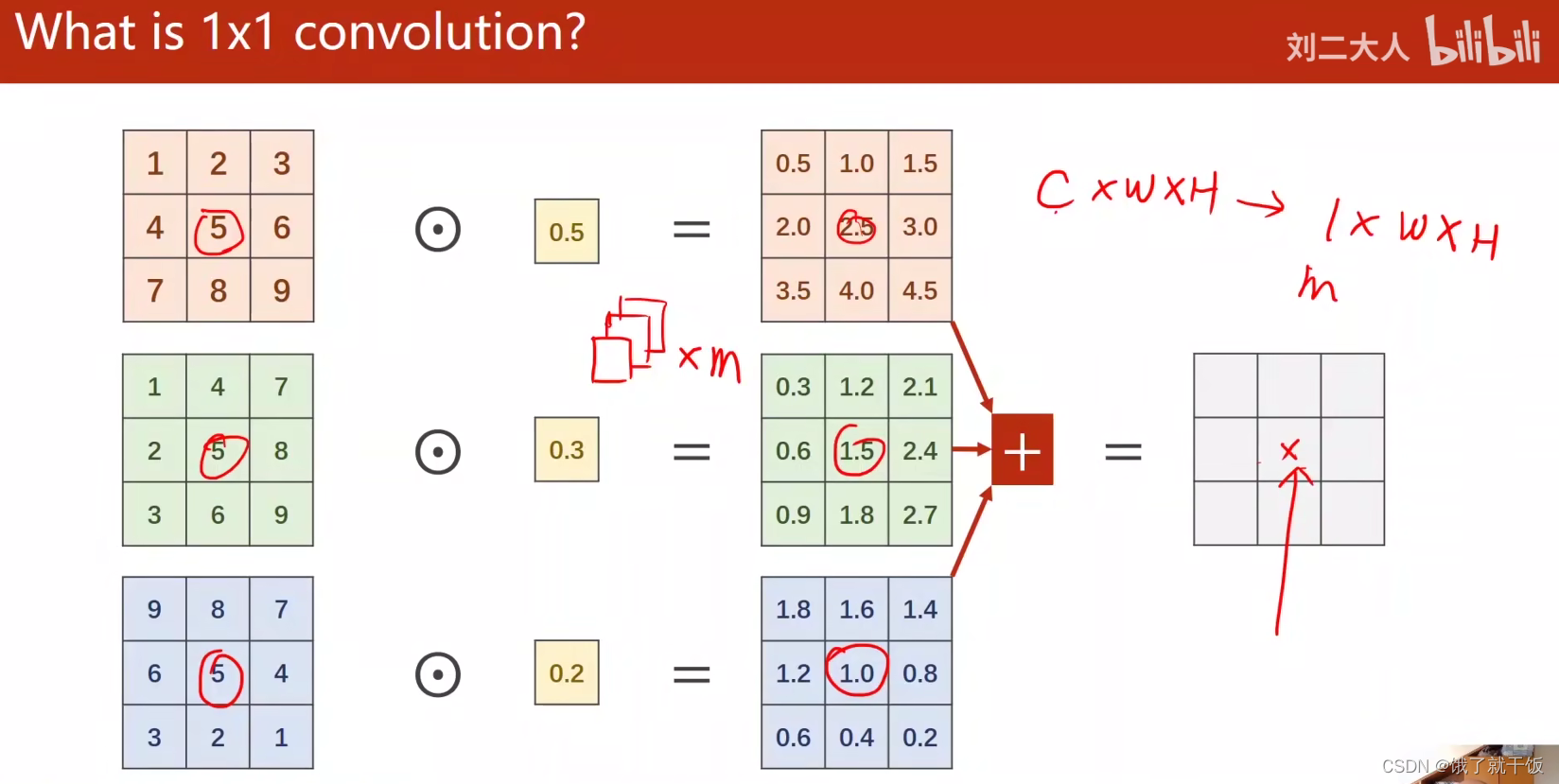
卷积核是1×1的,权重值就1个数,卷积之后的结果是这个权重值乘以图像不同通道的像素值,然后相加。依次这么计算就得到一个右侧的特征图。因此一个C×W×H的特征图经过1×1卷积就得到一个1×W×H的特征图。如果想得到一个m×W×H的特征图,只需要m个1×1的卷积核进行计算即可。
这种的卷积的通道数取决于输入张量的通道。
上图中画×的信息包含了输入特征图不同通道同一位置的信息,称为一个信息融合的过程。
举一个信息融合的例子
如果要比较两个人的学习成绩,如何利用一个人各科成绩所组成的5维空间里面的分数信息,最简单的方法就是每个分数信息都乘以1个权重1,然后相加,得到的总分就也是一个信息融合的结果。
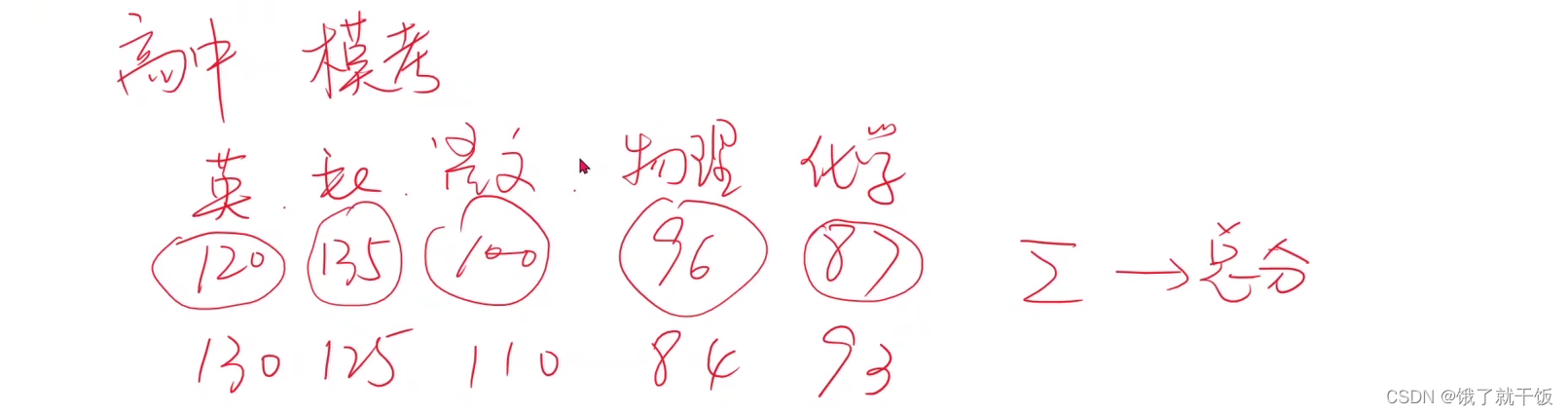
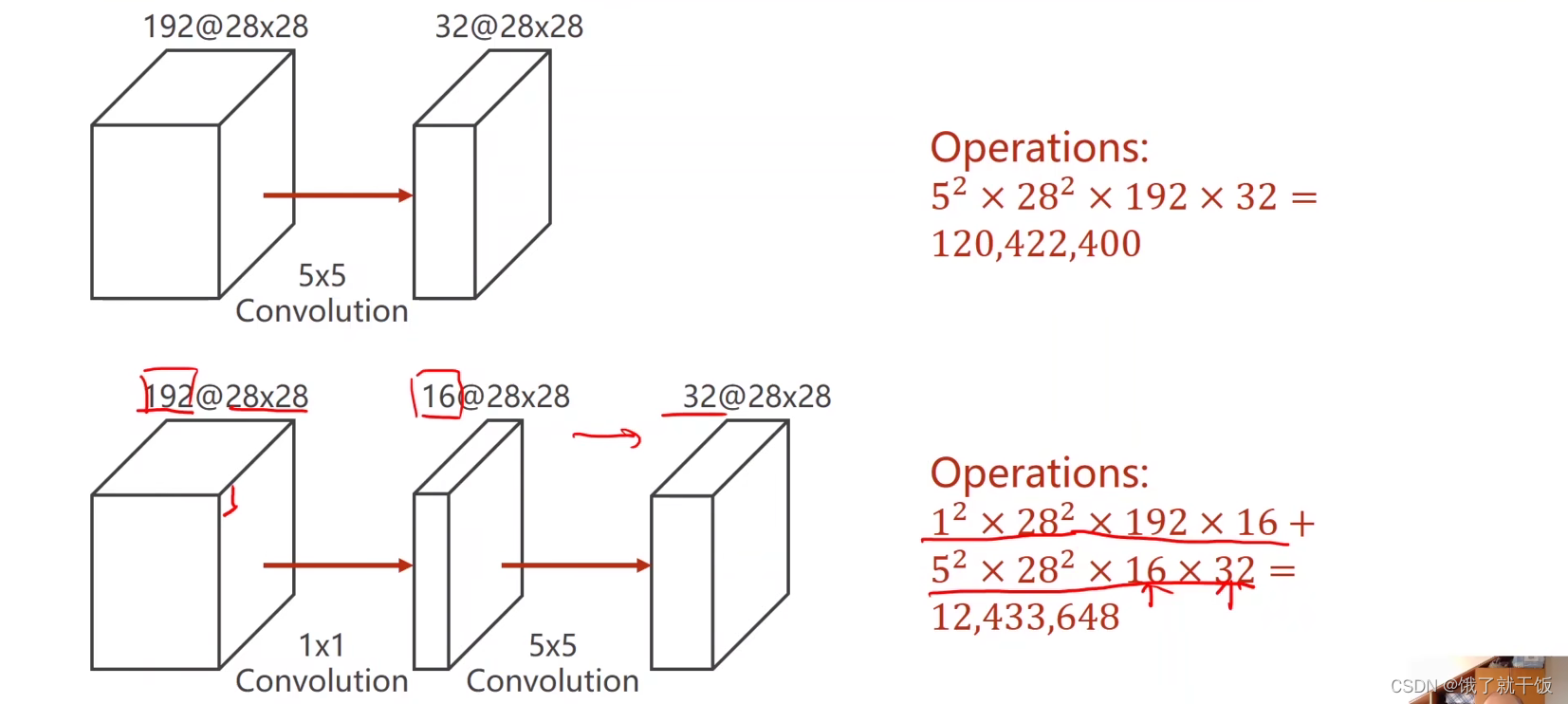
1×1卷积最主要的工作是改变通道的数量,这样可以极大地减少计算量,1×1卷积更详细可看:一文读懂卷积神经网络中的1x1卷积核
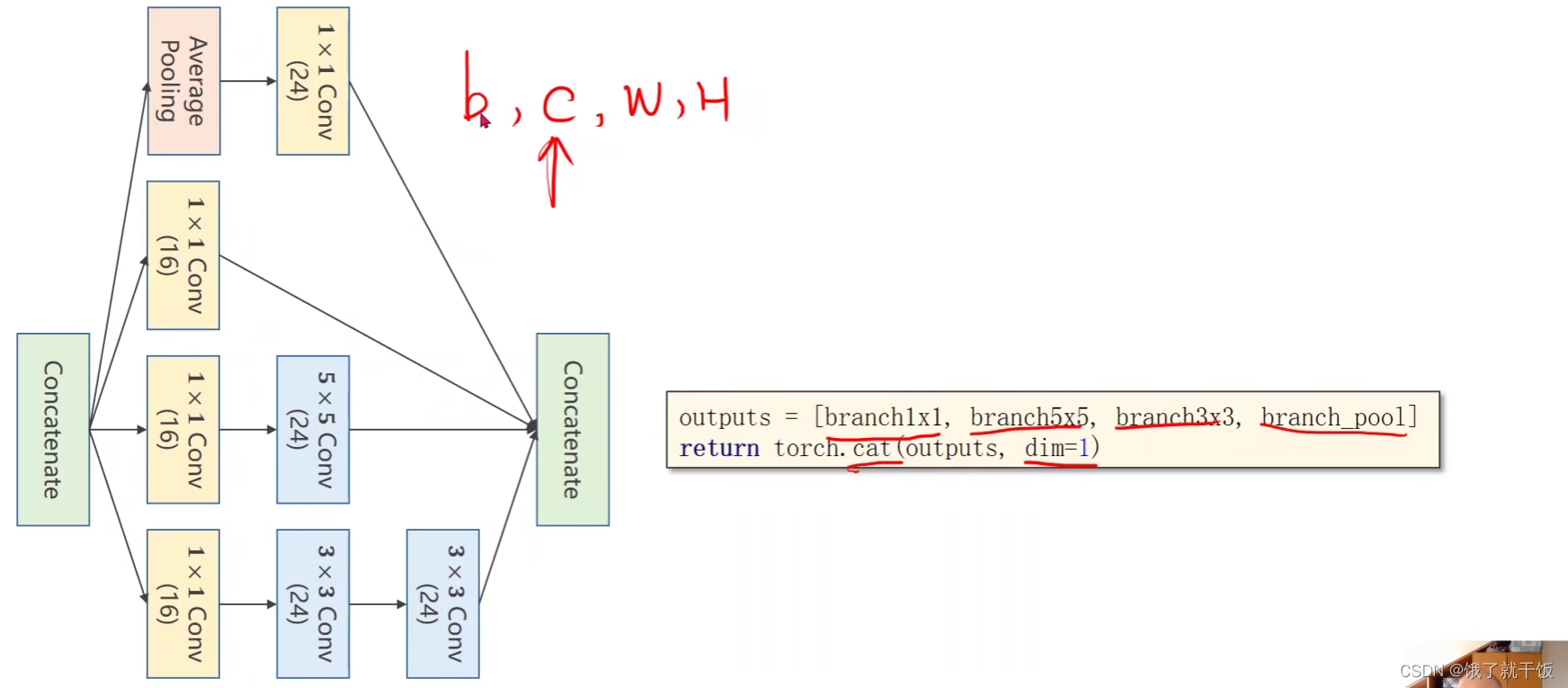
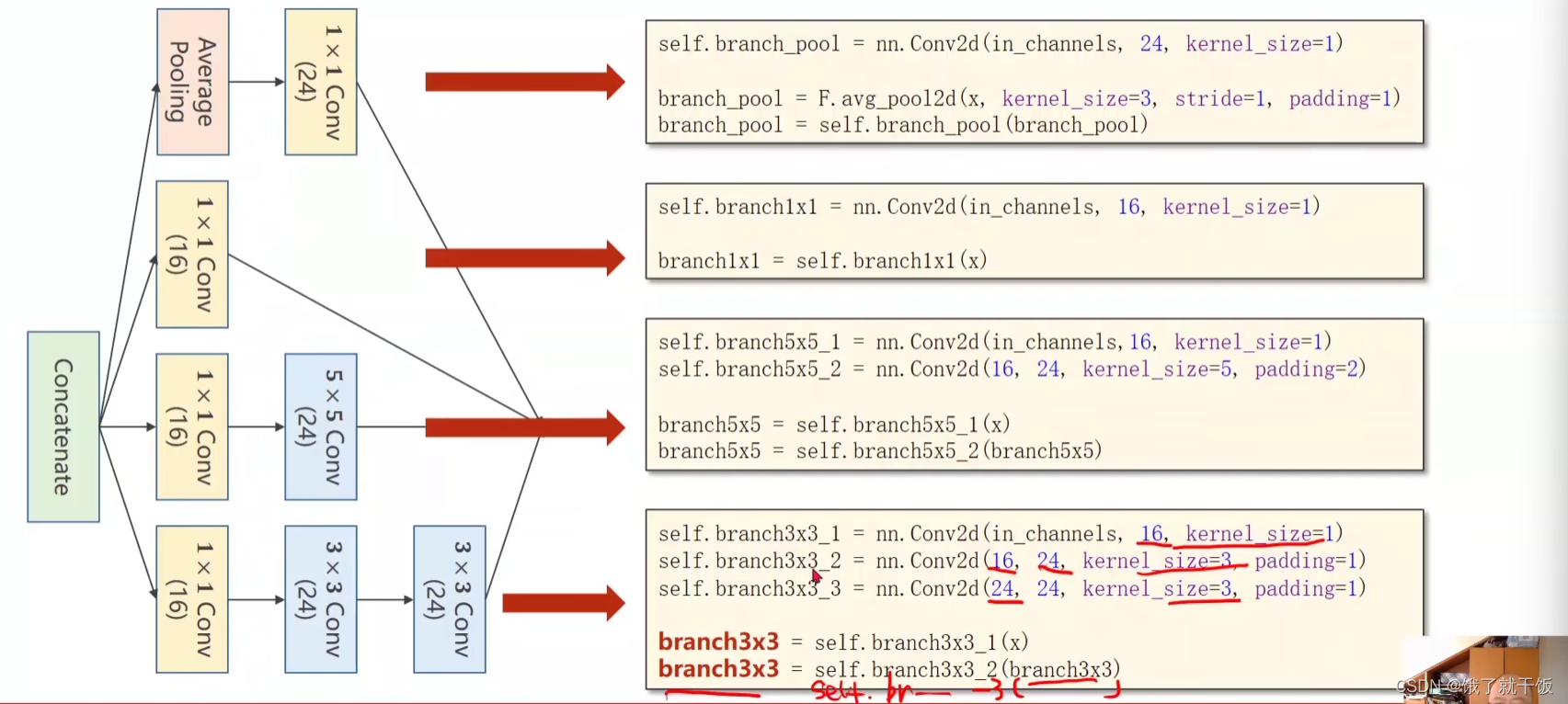
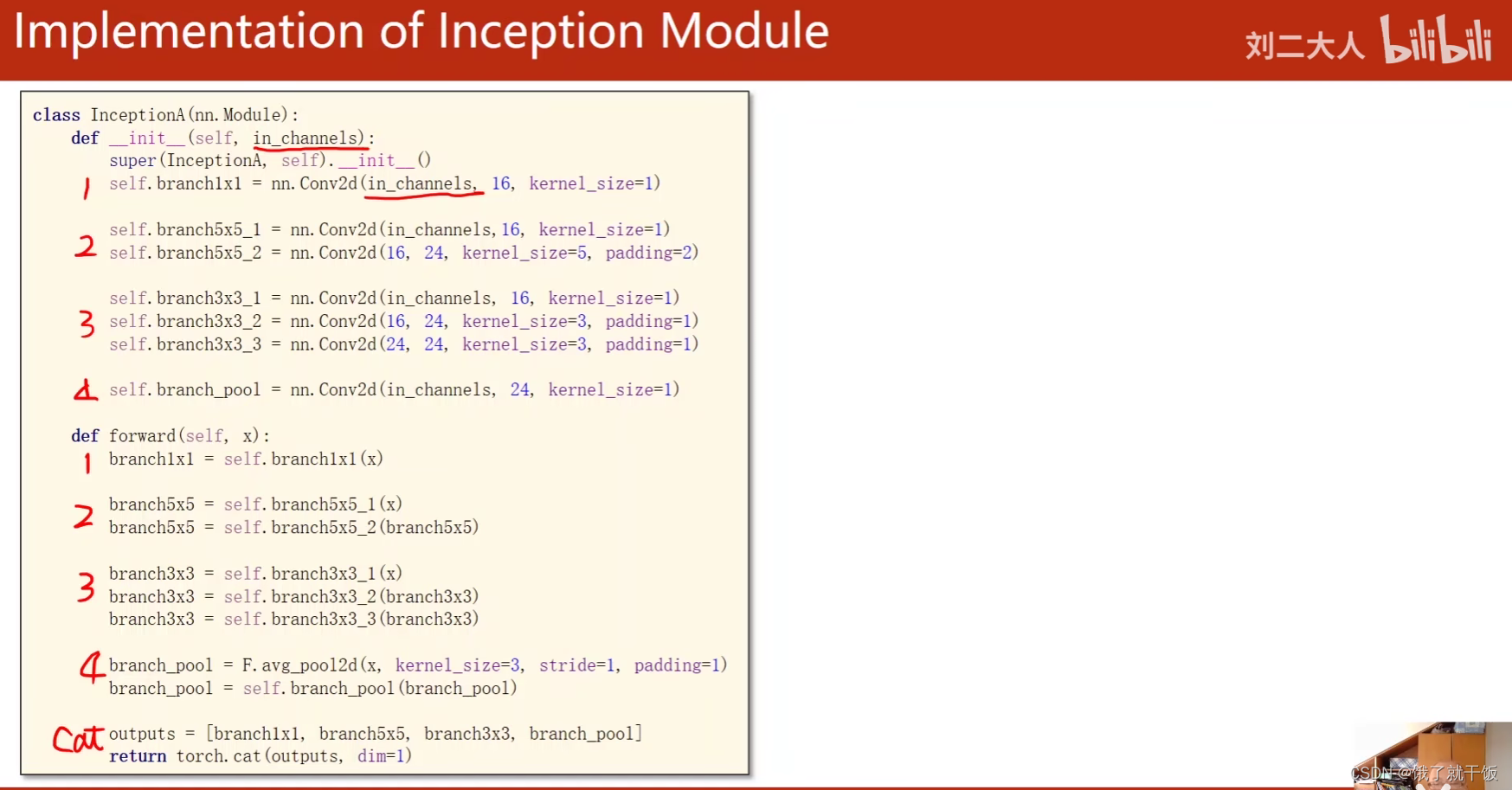
Inception模块分为4个分支:1.池化分支、2.1×1分支、3.5×5分支、4.3×3分支

为什么设置dim=1
因为张量的形状是B×C×W×H,要在通道上进行结合,所以设置dim=1
看代码
看每一个分支是如何实现的
池化分支:
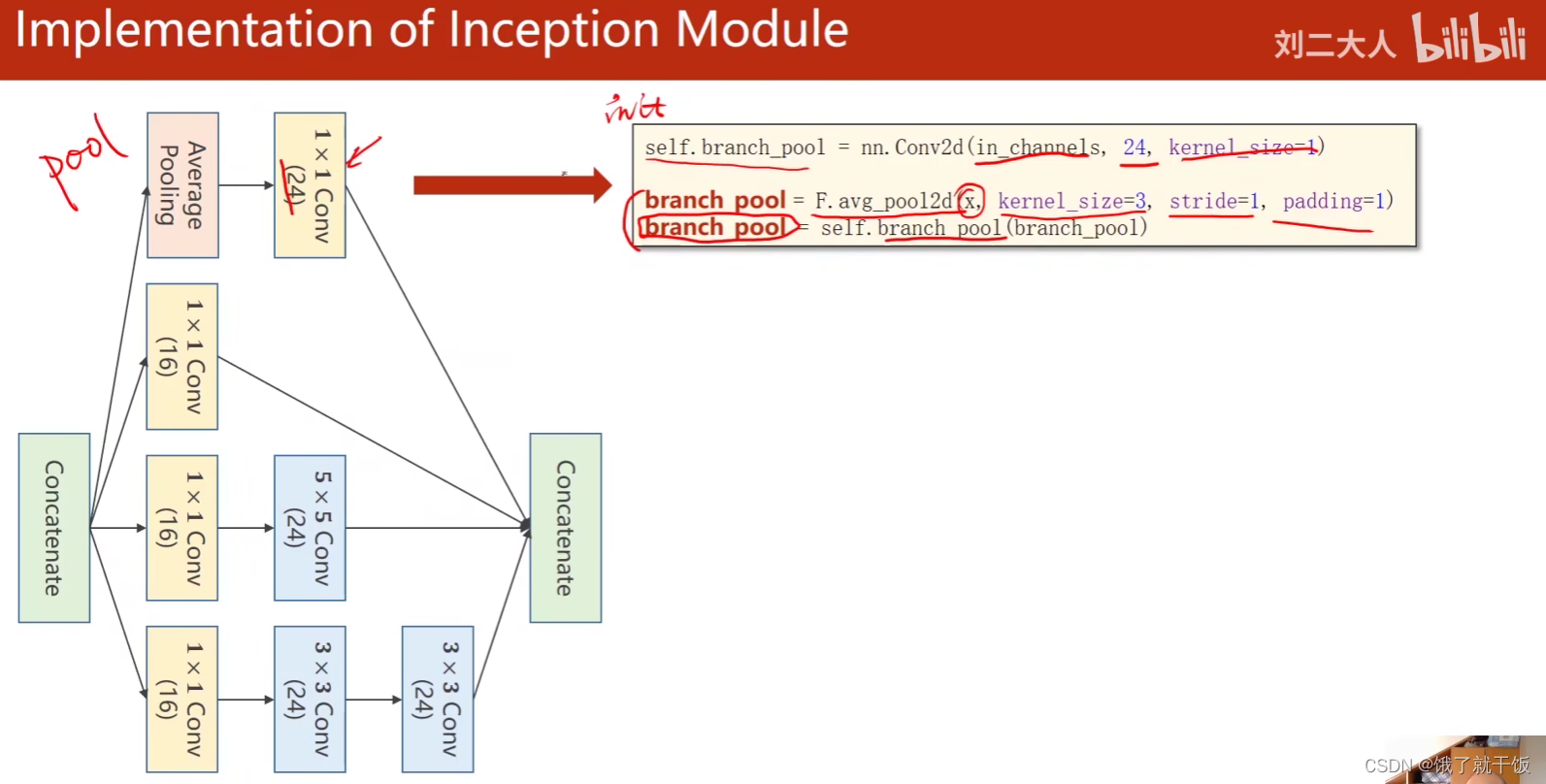
最后拼接
为什么设置dim=1
因为张量的形状是B×C×W×H,要在通道上进行结合,所以设置dim=1
88=24*3+16,即3个分支是24通道,1个分支是16通道
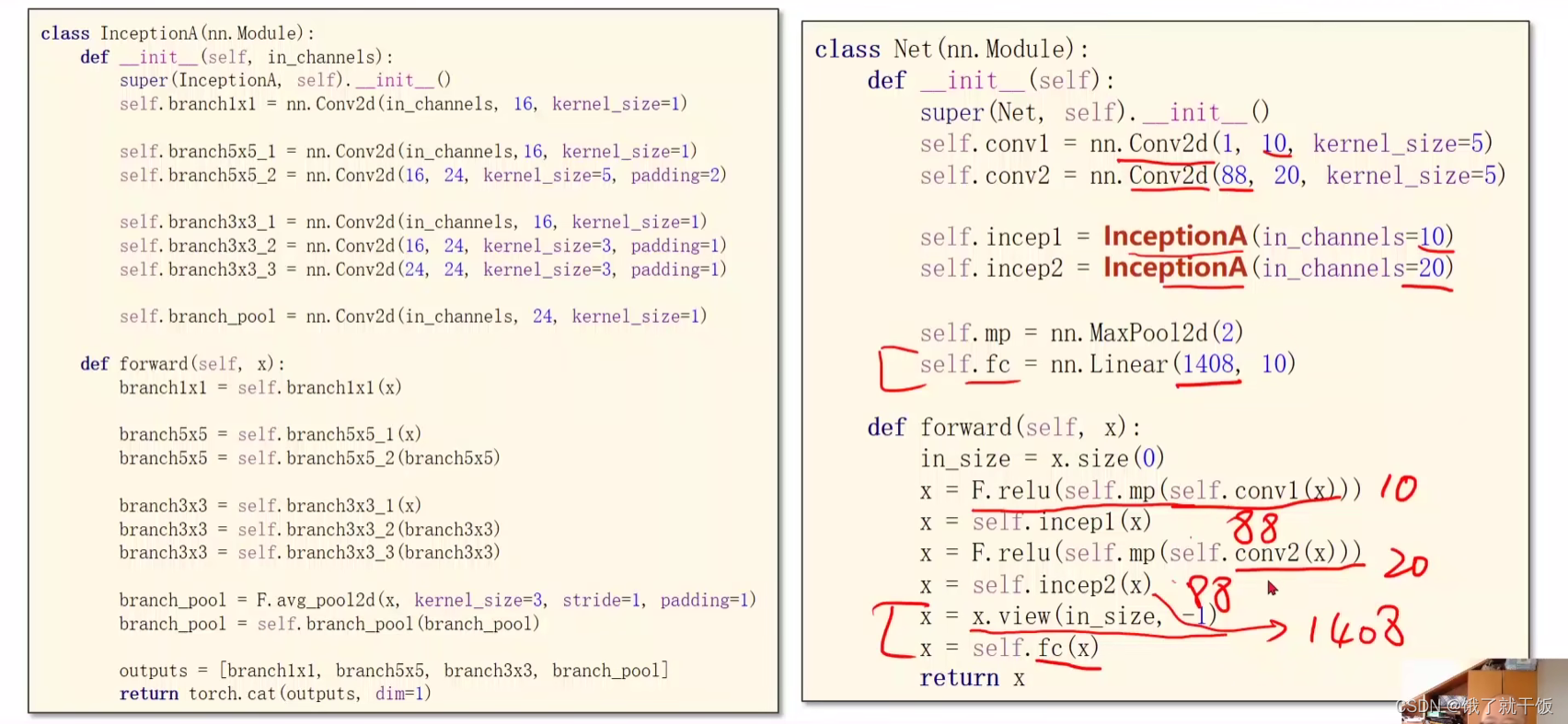
使用上面构建的网络替换上一节中的网络,训练出的结果可以达到98%的正确率
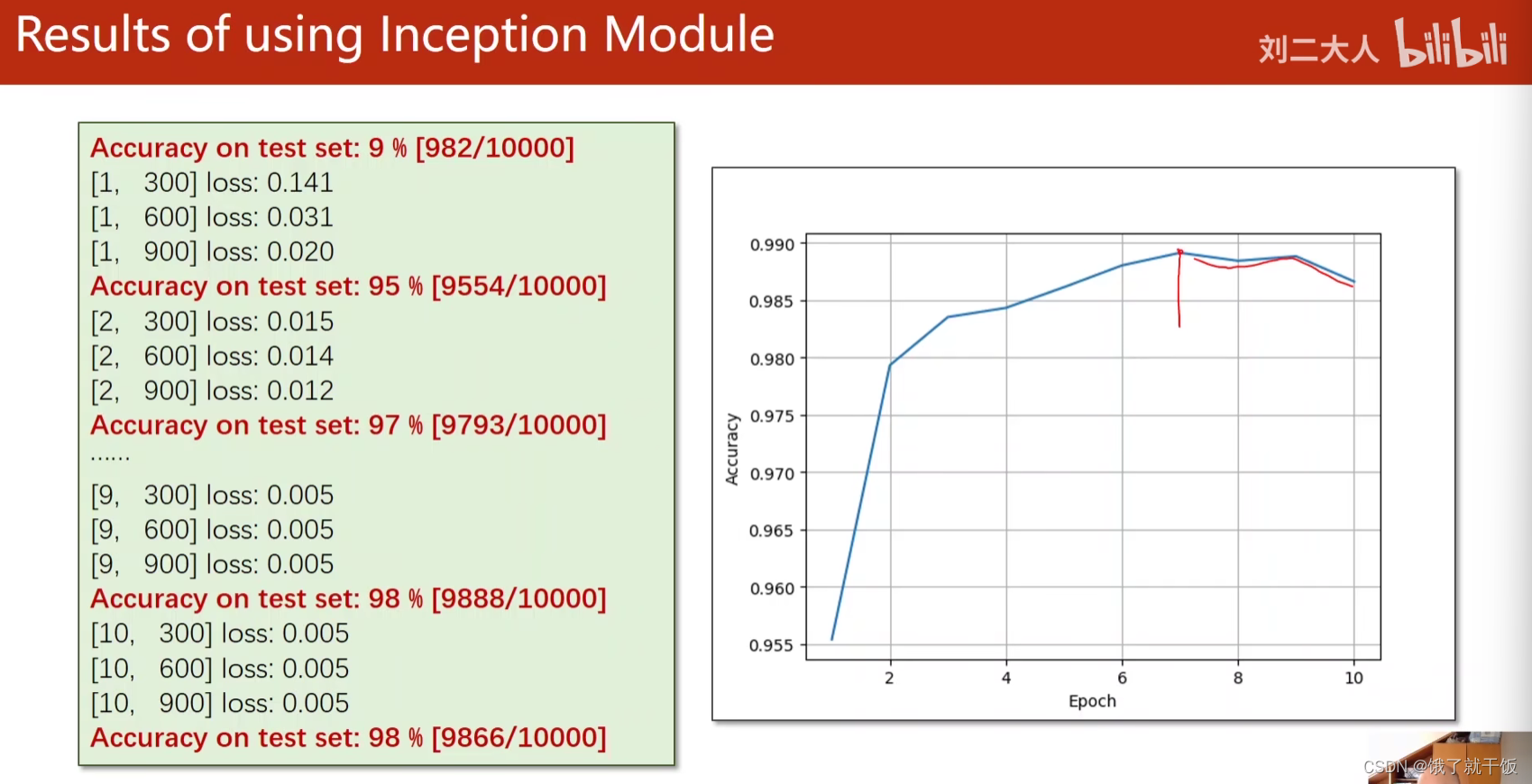
在实际中训练网络时,会将模型在测试集上最好的表现对应的参数做一个备份,即使用上图中右边的图中最高点对应的模型参数作为最终的训练好的模型,该模型的泛化性能最好的网络。
GooleNet中提到的就是要想效果好就要加深网络层数

将3×3的卷积一直堆叠起来并不能提高效果,见下图:

论文中提到效果变差的一种可能原因是出现了梯度消失的现象,梯度趋近于0,则权重就得不到更新,因此离输入比较近的块得不到充分的训练,以前为解决梯度消失问题,曾提出过一些方法:
以分类为例:
输入是784维,做10分类任务,中间有很多隐藏层,可以先针对第1层隐藏层进行训练,现在是只有输入层,第1层隐藏层,1个输出层,输出层在代码中定义时可以设置为512×10的,这样经过充分训练之后,会得到一个比较好的隐藏层
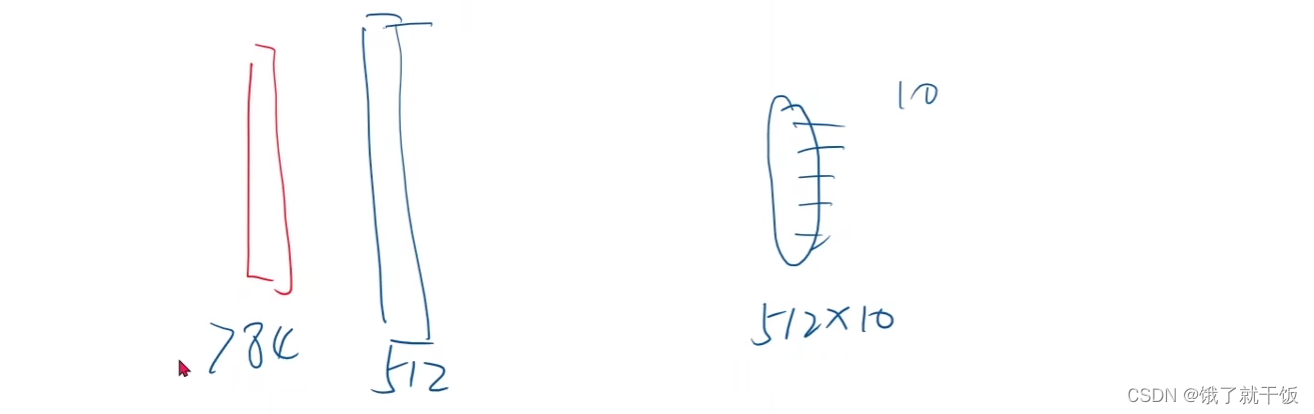
在得到1个隐藏层之后,在这个隐藏层后面再加上第2个隐藏层,此时网络变成了4层:输入层,1个训练好的隐藏层,1个待训练的隐藏层,输出层,接下来的操作是固定之前训练好的隐藏层(下图中使用锁住来表示),输出层在代码中定义时设置为256×10,这样经过充分训练之后,就又会得到一个比较好的隐藏层。

多次训练,可得到1个每个隐藏层都训练的比较充分的模型。这个方法是没有残差连接skip-connection方法之前解决梯度消失的方法。
在深度学习中上面的这个方法实行起来有点难,因为网络层数太多,深度深度,网络深了才叫深度嘛
Residual Net中提供的方法:
plain:朴素的,简单的

z对x的导数中是1与F对x的导数的和,即使F对x的导数很小,依然能保证z对x的导数在1附近,因此多个这样的数相乘也能保证不会接近于0,这样离输入比较近的层可以得到充分的训练。
使用skip-connection需要满足输入和输出的张量的维度都得一样,即W、H、C都一样

虚线的部分是因为用了步长为2的卷积,输入和输出的张量维度不一样了,因此可以选择不做跳链接,当然也可以选择做跳连接,只是需要进行处理,即输入的x直接做一个2×2的最大池化,这样即可保证输入与输出的尺寸变得一样。
一个简单的残差网络的代码实现
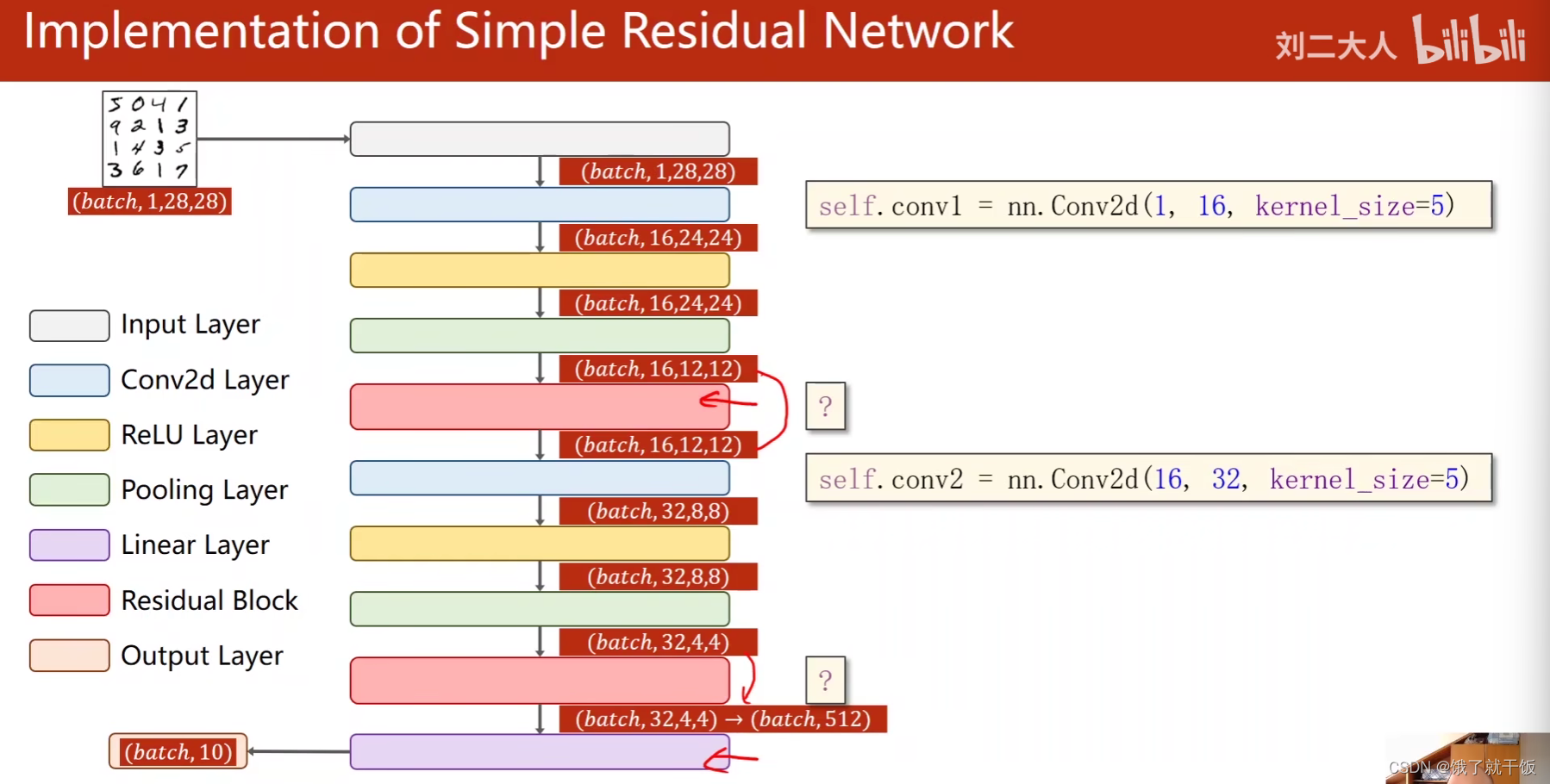

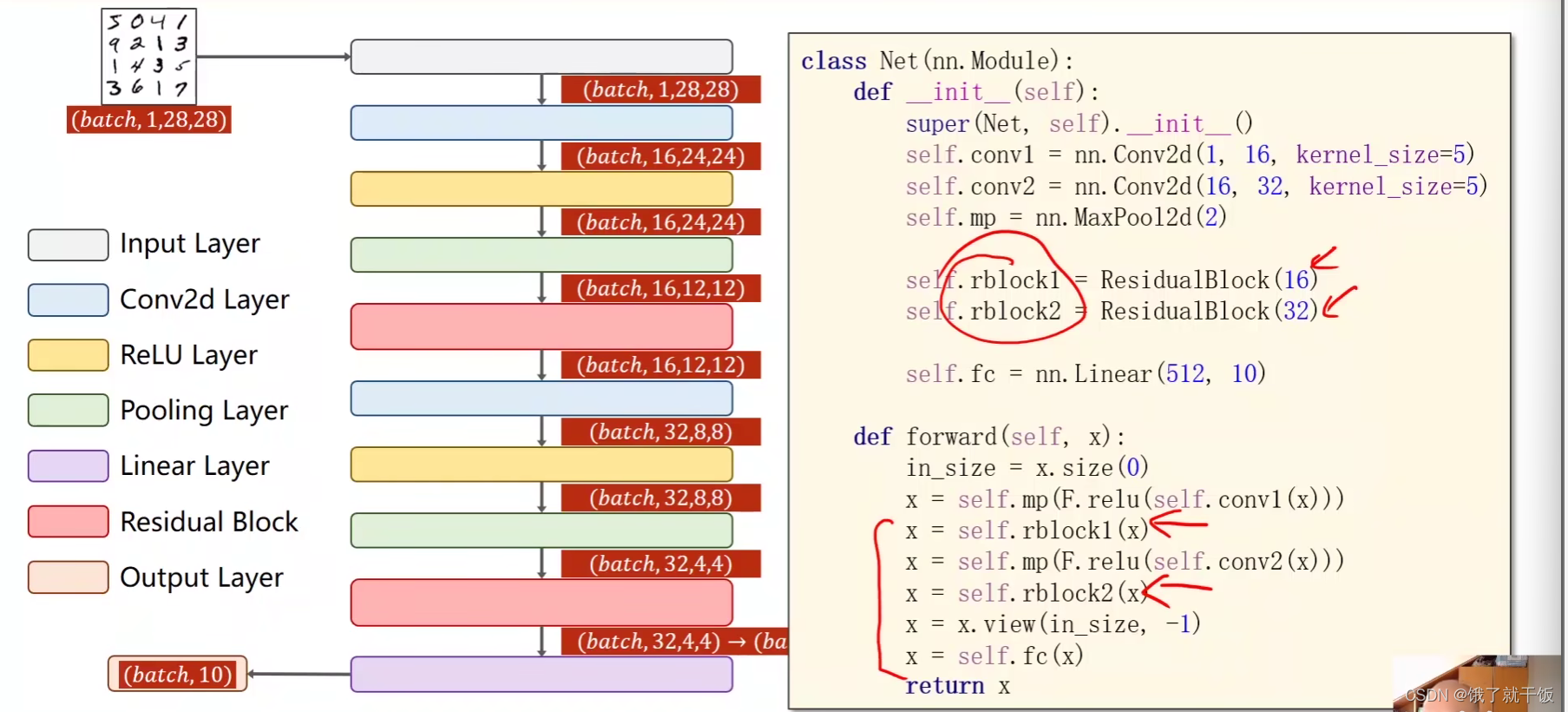
以后遇到多么复杂的网络也不用怕,只需要把每个模块写成一个一个的类,然后最后用一个总的类将这些类封装起来,就可以实现网络的搭建。
另外在写网络时需要不是一下就能把整个网络给写好,需要一步一步验证网络的输出,根据上一步的输出来写下一层网络,要验证每一层网络都是对的。
这种写代码的方式称为增量式的开发方式。
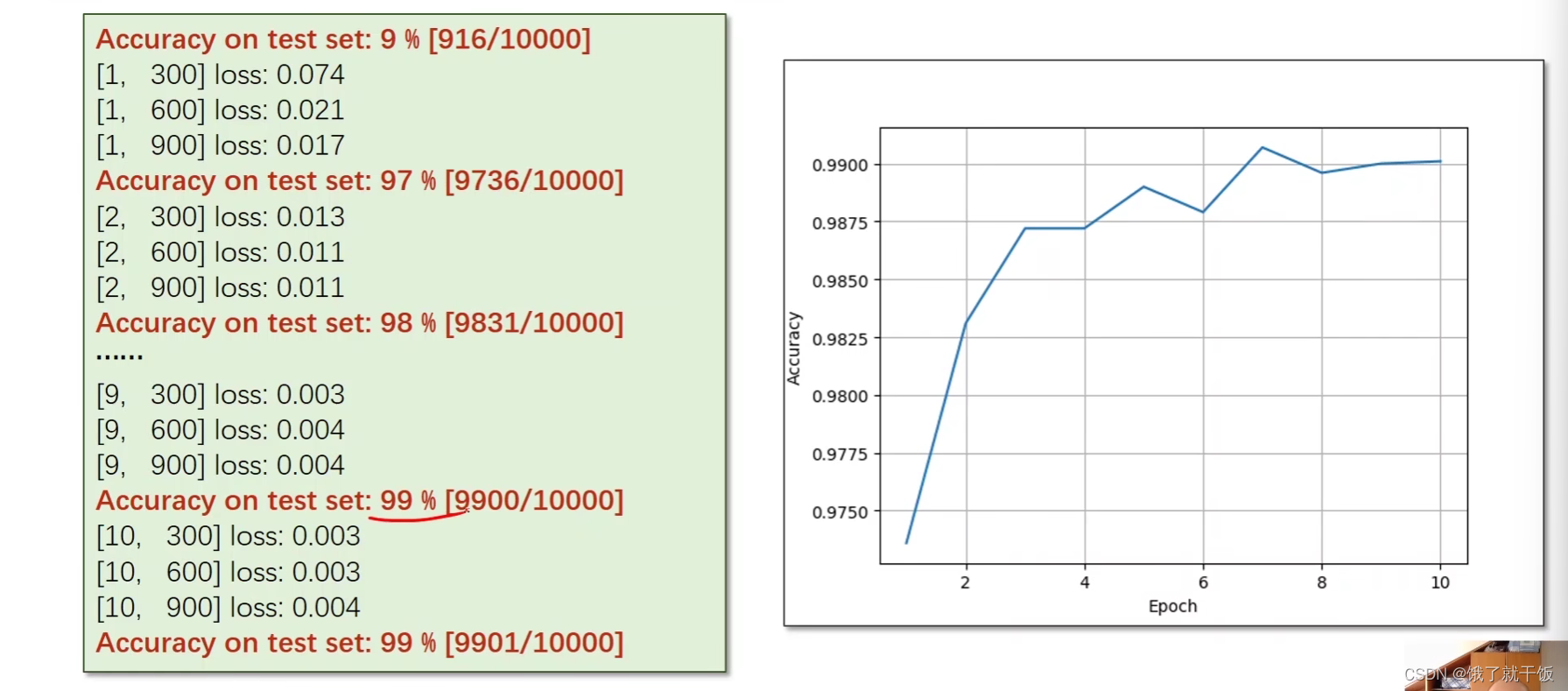
用了residual Net之后,在测试集上的准确率可以达到99%
练习11-1
下面这篇论文中给出了多种的residual block的构造方式,如constant scaling和conv shortcut
He K, Zhang X, Ren S, et al. ldentity Mappings in Deep Residual Networks[C]

练习11-2
Dense Net:Huang G, Liu Z, Laurens V D M, et al. Densely Connected Convolutional Networks[j. 2016:2261-2269.
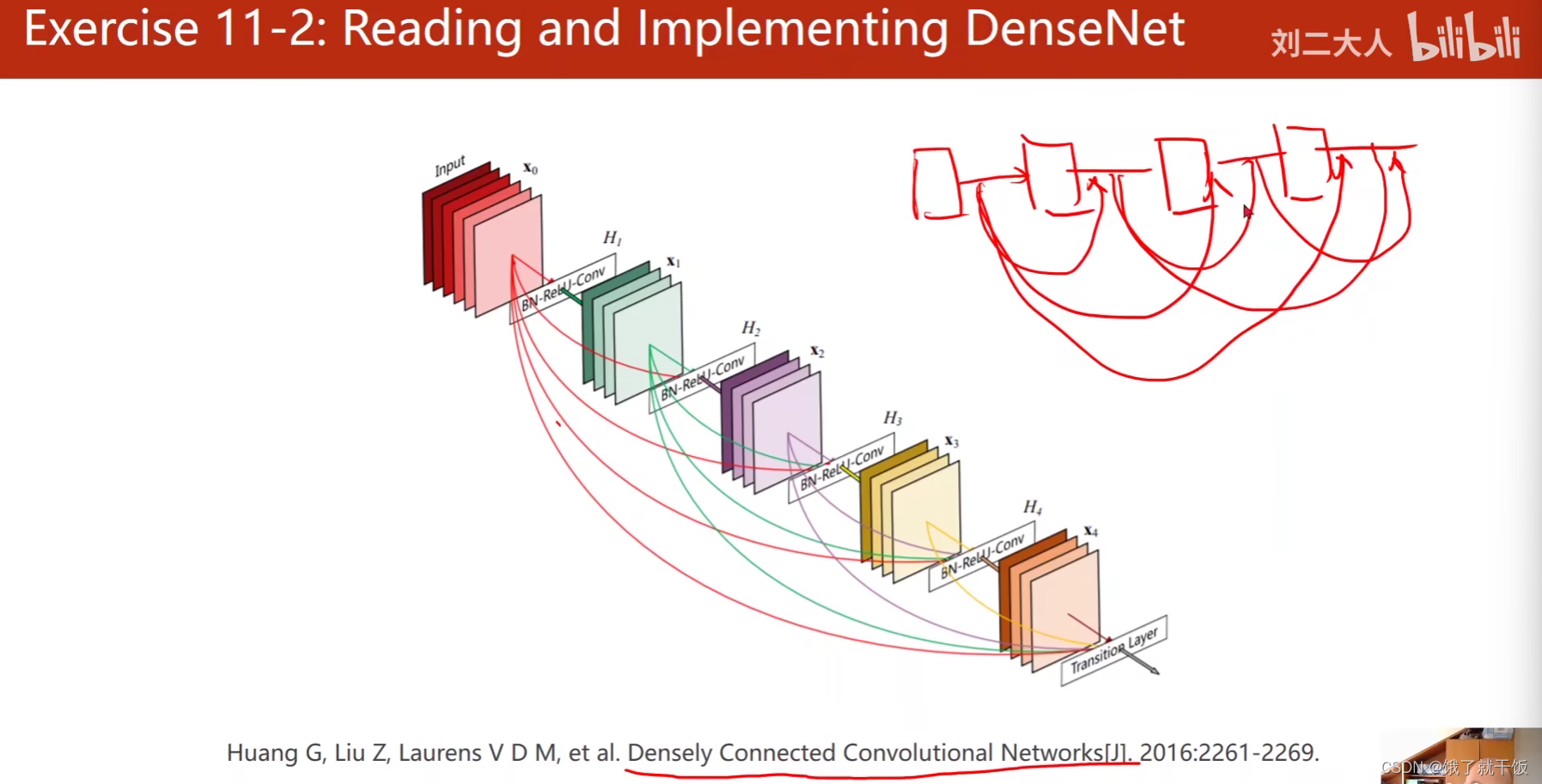
图像之后的路如何走
1、理论(上面的课程比较偏如何实现一个网络)
加深理论深度,深入理解深度学习模型
看书如《花书》
2、阅读pytorch的文档
之后要写复杂的网络,涉及稀奇古怪的运算
建议至少通读一遍
文档结构、支持的运算、都有哪些层
3、复现经典的工作
经典的深度学习的论文,
不能光会跑通代码,能跑通代码只是代表会配置环境了,
选特定领域,读代码、学习代码、尝试写代码
4、扩充视野
这一步指的是将前三步做好,就能看懂各种模块是怎么用代码写出来,慢慢的积累套路积累的越来越多,编程就是套路。套路掌握的越多,写的花样就越多,在扩充视野的过程中就是在不断解决
1、代码上的盲点
2、知识上的盲点

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











