







目录
一、快速理解
1、有四个牧师要去郊区布道,一开始牧师们不知道每个居民家的位置,然后就随机选取了几个布道点,并且把这几个布道点的位置情况告诉了郊区所有的居民,于是每个居民都到离自己家最近的布道点去听课;
2、然而听课之后,大家都觉得自己家离布道点太远了,那怎么办呢?于是每个牧师都统计了自己自己课上所有居民的位置,选择了所有位置的中心点作为自己新的布道点;
3、那么又有问题来了,牧师的每一次移动不可能离所有的人都更近,有的居民发现A牧师移动以后自己还不如去B牧师处听课更近,于是每位居民又去了离自己最近的布道点……就这样,牧师每隔一段时间就更新自己的新位置,居民根据自己的情况选择布道点,最终慢慢的牧师的位置就稳定了下来。
二、k-means算法的步骤
1、先定义总共的类/簇(cluster)的数量
2、将每一个簇心(cluster centers)随机定在一个点上
3、将每一个数据关联到最近簇中心所属的簇上
4、对于每一个簇找到其所有关联点的中心点(取每一个点横纵坐标的平均值)
5、将上一步中找到的中心点更新为新的簇心
6、不停地取更新,直到每个簇所拥有的点不变
三、进一步理解k-means算法(例子)
给出一个题目:给你以下6个点,首先将A3和A4作为两个簇的初始簇心,问最后的簇的所属情况?
| 序号 | X | Y |
| A1 | 1 | 2 |
| A2 | 1 | 4 |
| A3 | 3 | 1 |
| A4 | 3 | 5 |
| A5 | 5 | 2 |
| A6 | 5 | 4 |
那么这个问题怎么解呢?我们按照上边的步骤一步一步的算
1、我们现在有了两个定点,接下来的任务就是将每一个数据关联到最近簇中心所属的簇上,也就是计算每个点到簇心的距离,将距离近的点归为一类
| 序号 | X | Y | Distance to A3 | Distance to A4 |
| A1 | 1 | 2 | 2.24 | 3.61 |
| A2 | 1 | 4 | 3.61 | 2.24 |
| A3 | 3 | 1 | 0 | 4 |
| A4 | 3 | 5 | 4 | 0 |
| A5 | 5 | 2 | 2.24 | 3.61 |
| A6 | 5 | 4 | 3.61 | 2.24 |
2、经过上边的距离计算,我们得到了A1、A3、A5为一簇,A2、A4、A6为一簇,接下来就是要将每一簇的所有点的X,Y值分别进行取平均值,然后得到新的簇心
| 位置点 | X | Y |
| new B1 | 3 | 1.67 |
| new B2 | 3 | 4.33 |
3、我们再次计算每一个点到新的簇心B1、B2的距离,将距离近的归为一簇
| 序号 | X | Y | Distance to B1 | Distance to B2 |
| A1 | 1 | 2 | 2.03 | 3.07 |
| A2 | 1 | 4 | 3.07 | 2.03 |
| A3 | 3 | 1 | 0.67 | 3.33 |
| A4 | 3 | 5 | 3.33 | 0.67 |
| A5 | 5 | 2 | 2.03 | 3.07 |
| A6 | 5 | 4 | 3.07 | 2.03 |
4、神奇的是当B1、B2为簇心时,A1、A3、A5还是归为一类,A2、A4、A6归为另一簇,这就反映出了关联点没有变化,所以之后的计算结果不会改变。停止计算,这样簇最后所属的情况就为:蓝色簇(A1、A3、A5)、粉色簇(A2、A4、A6)
四、python代码及其详解
import random
import numpy as np
import matplotlib.pyplot as plt
def kmeans(dataSet, k, initial_centroids=None):
"""
K-means聚类算法
Parameters:
dataSet (list): 数据集,包含多个数据点的列表
k (int): 聚类的数量
initial_centroids (list or None): 自定义的初始质心列表,可以为None
Returns:
centroids (list): 最终的质心列表
clusters (list): 划分后的数据集列表,每个元素表示一个集群,包含属于该集群的数据点
"""
if initial_centroids is None:
centroids = random.sample(dataSet, k) # 使用随机选择的质心初始化
else:
if len(initial_centroids) != k:
raise ValueError("The number of initial centroids must be equal to k.")
centroids = initial_centroids
max_iters = 100
for _ in range(max_iters):
changed, newCentroids = classify(dataSet, centroids, k) # 进行一次聚类
if np.all(changed == 0):
break
centroids = newCentroids
clusters = [[] for _ in range(k)]
for i, point in enumerate(dataSet):
cluster_idx = np.argmin([np.linalg.norm(np.array(point) - np.array(centroid)) for centroid in centroids])
clusters[cluster_idx].append(point)
return centroids, clusters
def classify(dataSet, centroids, k):
"""
将数据点划分到最近的质心,计算新的质心
Parameters:
dataSet (list): 数据集,包含多个数据点的列表
centroids (list): 当前的质心列表
k (int): 聚类的数量
Returns:
changed (numpy array): 标记每个质心是否发生变化的数组
newCentroids (list): 新的质心列表
"""
changed = np.zeros(k)
newCentroids = []
for i in range(k):
# 计算每个质心的新位置(均值)
newCentroid = np.mean([point for j, point in enumerate(dataSet) if i == np.argmin([np.linalg.norm(np.array(point) - np.array(centroid)) for centroid in centroids])], axis=0)
if not np.array_equal(newCentroid, centroids[i]):
changed[i] = 1
newCentroids.append(newCentroid)
return changed, newCentroids
# 创建数据集
def createDataSet():
# 返回一个包含多个二维数据点的列表
return [[1, 2], [1, 4], [3, 1], [3, 5], [5, 2], [5, 4]]
if __name__ == '__main__':
dataset = createDataSet()
initial_centroids = [[3, 1], [3, 5]] # 自定义初始质心,每个质心是一个二维点的列表
centroids, clusters = kmeans(dataset, 2, initial_centroids=initial_centroids) # 对数据集进行K-means聚类,k=2
print('质心为:%s' % centroids) # 打印最终的质心
print('集群为:%s' % clusters) # 打印每个集群中的数据点
# 可视化
for i, cluster in enumerate(clusters):
points = np.array(cluster)
plt.scatter(points[:, 0], points[:, 1], marker='o', label=f'Cluster {i+1}') # 绘制每个集群的散点图
centroids = np.array(centroids)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', color='red', s=100, label='Centroids') # 绘制质心的散点图
plt.legend()
plt.show() # 显示散点图
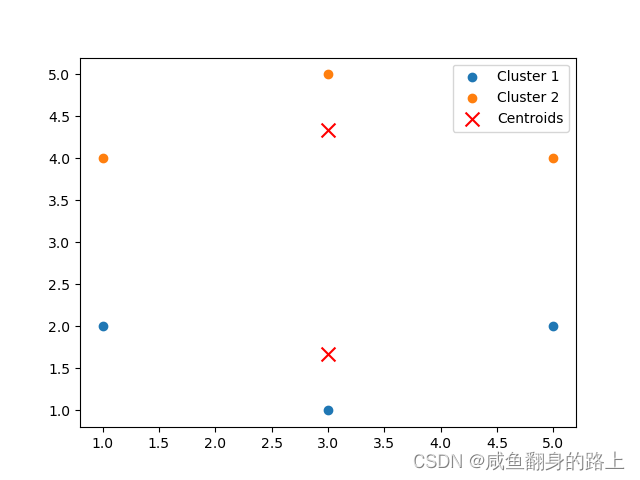
五、python运行结果展示
我们将[3,1]、[3,5]作为初始的质点,运行结果如下图所示:

六、k-means聚类算法的小结
K-means是一种常见的聚类算法,用于将数据集划分为K个不同的簇(cluster),每个簇包含相似的数据点。它的工作原理相对简单,以下是对K-means聚类算法的总结:
1、优点:
① 简单而高效:K-means是一种简单而高效的聚类算法,易于实现和理解。
② 可扩展性:对于大规模数据集,K-means的计算速度相对较快。
③ 适用性广泛:K-means适用于数值型数据,因此在很多领域都可以使用,如图像分割、文本分类等。
④ 结果可解释性:K-means的结果相对直观,得到的K个簇可以解释为不同的数据群组。
2、缺点:
①依赖初始值:K-means对初始质心的选择敏感,不同的初始质心可能会得到不同的聚类结果。
②局部最优解:K-means可能会陷入局部最优解,得到不是全局最优的聚类结果。
③簇数量K的选择:在实际应用中,通常需要根据领域知识或者通过其他评估指标来选择合适的簇数量K。
④处理噪声和离群值:K-means对噪声和离群值敏感,可能会导致错误的聚类结果。
⑤只适用于凸形簇:K-means对非凸形状的簇效果较差,无法很好地处理非线性边界的数据。
尽管K-means有一些局限性,但在许多实际问题中,它仍然是一个快速有效的聚类算法,并且在数据量较大且聚类结构较简单的情况下表现较好。对于复杂的数据集或者需要更好的聚类结果的场景,其他聚类算法(例如层次聚类、DBSCAN等)可能更加合适。
















 2094
2094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











