







朴素贝叶斯算法(Naive Bayesian algorithm)是在贝叶斯算法的基础上假设特征变量相互独立的一种分类方法,是贝叶斯算法的简化,常用于文档分类和垃圾邮件过滤。当“特征变量相互独立”的假设条件能够被有效满足时,朴素贝叶斯算法具有算法比较简单、分类效率稳定、所需估计参数少、对缺失数据不敏感等种种优势。而在实务中“特征变量相互独立”的假设条件往往不能得到满足,这在一定程度上降低了贝叶斯分类算法的分类效果,但这并不意味着朴素贝叶斯算法在实务中难以推广,反而它是堪与经典的“决策树算法”比肩的应用最为广泛的分类算法之一。本章我们讲解朴素贝叶斯算法的基本原理,并结合具体实例讲解该算法在Python中的实现与应用。
朴素贝叶斯算法分类及适用条件
与其他机器学习算法相比,朴素贝叶斯算法所需要的样本量比较少(当然样本量肯定是多多益善),样本量少于特征变量数目,那么估计效果也会被削弱。对比支持向量机、随机森林等算法,朴素贝叶斯算法往往估计效果偏弱,但胜在运行速度更快。Python的sklearn模块有四种朴素贝叶斯算法,包括高斯朴素贝叶斯、多项式朴素贝叶斯、补集朴素贝叶斯、二项式朴素贝叶斯。
(1)高斯朴素贝叶斯(Gaussian Naive Bayes)
该算法假设每个特征变量的数据都服从高斯分布(也就是正态分布),用来估计每个特征下每个类别上的条件概率。高斯朴素贝叶斯的决策边界是曲线,可以是环形也可以是弧线。高斯朴素贝叶斯擅长处理连续型特征变量。相对于前面介绍的Logistic回归,如果算法的目的是获得对概率的预测,并且希望越准确越好,那么应该首选Logistic算法;而如果数据十分复杂,或者满足稀疏矩阵的条件(在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律,则称该矩阵为稀疏矩阵),那么高斯朴素贝叶斯算法就更占优势。
(2)多项式朴素贝叶斯(Multinomial Naive Bayes)
该算法通常被用于文本分类,它假设所有特征变量是离散型特征变量,所有特征变量都符合多项式分布。多项式分布来源于统计学中的多项式实验,多项式实验的概念是:在n次重复试验中每项试验都有不同的可能结果,但在任何给定的试验中,特定结果发生的概率是不变的。多项式朴素贝叶斯算法擅长处理分类型特征变量,但受到样本不均衡问题(即分类任务中不同类别的训练样本数目差别很大的情况,一般地,样本类别比例(Imbalance Ratio)(多数类vs少数类)明显大于1:1(如5:1)就可以归为样本不均衡问题)影响较为严重。
(3)补集朴素贝叶斯(Complement Naive Bayes)
该算法是前述多项式朴素贝叶斯算法的改进,不仅能够解决样本不均衡问题,还在一定程度上放松了“所有特征变量之间条件独立的朴素假设”。补集朴素贝叶斯在召回率方面表现较为出色,如果算法的目的是找到少数类(存在异常行为的员工、存在洗钱行为等),则补集朴素贝叶斯算法是一种不错的选择。
4)二项式朴素贝叶斯(Bernoulli Naive Bayes)
也称伯努利朴素贝叶斯,该算法假设所有特征变量是离散型特征变量,所有特征变量都符合伯努利分布(二项分布,取值为两个,注意这两个值并不必然为0、1取值,也可以为1、2取值等)。二项式朴素贝叶斯算法要求将特征变量取值转换为二分类特征向量,如果某特征变量本身不是二分类的,那么可以使用类中专门用来二值化的参数binarize来转换数据,使它符合算法。
以“数据8.1”文件和“数据8.2”文件中的数据为例进行讲解。“数据8.1”记录的是某商业银行在山东地区的部分支行的经营数据(虚拟数据,不涉及商业秘密),变量包括这些商业银行全部支行的V1(转型情况)、V2(存款规模)、V3(EVA)、V4(中间业务收入)、V5(员工人数)。但与“数据7.1”不同的是,V1(转型情况)分为两个类别:“0”表示“未转型网点”;“1”表示“已转型网点。
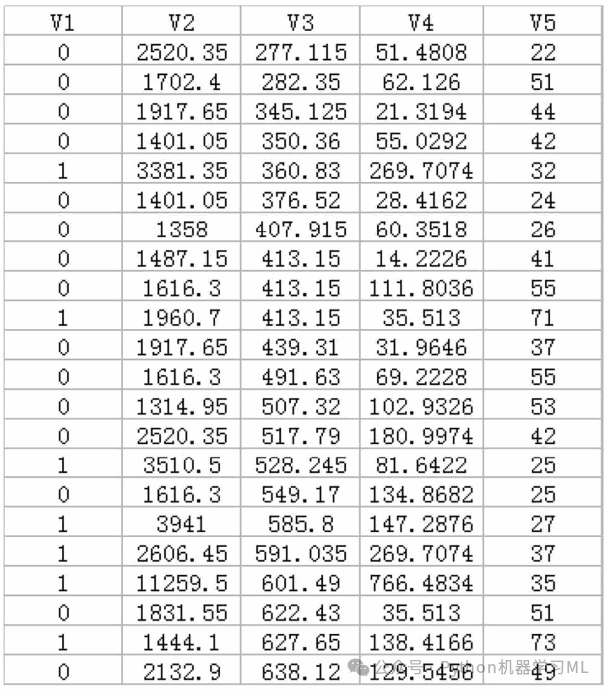
针对“数据8.1”的朴素贝叶斯模型,我们以V1(转型情况)为响应变量,以V2(存款规模)、V3(EVA)、V4(中间业务收入)、V5(员工人数)为特
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









