







这一章节主要介绍神经网络的一些重要性质.这些性质部分地解释了当前流行的神经网络,也激发了探索更深层次架构的必要性。虽然浅层神经网络是一个通用的逼近器,但更深的架构可以在保留表示能力的同时显著降低对资源的要求。最后会介绍反向传播的一些性质。
目录
Universal Approximation Property(泛逼近性)
Backpropagation Finds Global Optimal for Linear Separable Data反向传播算法对线性可分数据寻找全局最优
Backpropagation Fails for Linear Separable Data对于线性可分数据,反向传播失败
Universal Approximation Property(泛逼近性)
由感知机到神经网络实际只是将感知机放在一起。如一个单层的神经网络就是将感知机并排放置。而一个多层神经网络(被称为多层感知机MLP)就是将一个单层神经网络堆叠在另一个单层神经网络上。
这里的泛逼近性主要包含三个方面,大致是说一个MLP可以表示任意的函数
- 布尔逼近:只有一个隐含层的多层感知器(an MLP of one hidden layer,本文是把一个两层的神经网络 称为 有一个隐含层的神经网络)可以精确表示任意布尔函数;
- 连续逼近:只有一个隐含层的多层感知器可以任意精度逼近任意有界连续函数;
- 任意逼近:有两个隐含层的多层感知器可以任意精度逼近任意函数。
接下来将对这三个性质进行解释。
任意布尔函数的表示(布尔逼近)
在第二章:从亚里士多德到现代人工神经网络这部分内容中证明了每个线性感知机可以执行AND或OR。根据德摩根定律:
非(P 且 Q) = (非 P) 或 (非 Q)
非(P 或 Q) = (非 P) 且 (非 Q)
每个命题的公式都可以转化为等价的合取范式
任何命题公式,最终都能够化成 ( A 1 ∨ A 2 ) ∧ ( A 3 ∨ A 4 ) 的形式,这种先 ∨ 析 取,再 ∧ 合 取的范式,被称为 “ 合取范式”。因此就可以把布尔函数改写成这种形式,并以这样的方式设计网络:输入层执行所有的AND操作,而隐藏层只是简单的OR操作。
任意有界连续函数的逼近
如果想表示一个更复杂的函数,如图4 ( a )所示,我们可以使用一组线性感知器(如图4(b)所示),其中每个线性感知器描述一个半空间。同理,就可以使用如图4 ( c )所示的多个线性感知机将a表示出来。在图4 ( c )中显示的数字表示由感知器描述的落入相应区域的子空间的数量。可以看到,通过适当的选取阈值( (如图4 ( c )中θ = 5) ),就可以将目标函数束缚出来。因此,可以只用一个隐含层来描述任何有界连续函数;图d的表示也是同样的道理。
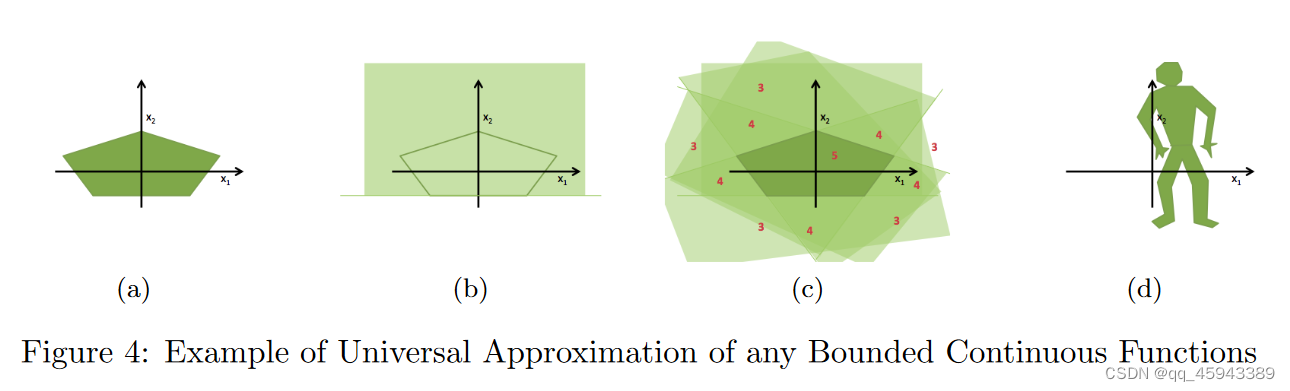
之后通过公式解释了一下为什么可以实现有界连续函数的逼近,证明是通过反证法得到的,根据Hahn - Banach定理和Riesz表示定理,f ( x )的闭包不全是f ( x )所在的子空间,这与σ是激活函数的假设相矛盾。(这里没看懂,为什么还和激活函数有关?)
在这个性质被证明之后的十年,Castro等人( 2000 )得出结论:当最终输出被压扁时,这个万能逼近性质仍然成立。
值得注意的是,这个性质是在激活函数是压扁函数(squashed function)的情况下显示出来的。
最近深度学习研究的很多激活函数都不属于这个范畴
任意函数的逼近
首先需要说明一个关于将线性感知器结合到神经网络中的主要性质。由图5可以看出,随着约束目标函数的线性感知器数量的增加,多边形外面积与阈值接近的区域缩小。遵循这一趋势,我们可以使用大量的感知器来绑定一个圆,即使在不知道阈值的情况下,这也可以实现,因为接近阈值的区域会收缩到一无所有。
具有一个隐含层的神经网络可以表示任意直径的圆。进一步地,可以引入了另一个隐藏层,用于组合多个不同圆的输出。这个新增加的隐藏层仅用于执行OR操作。当使用额外的隐含层对上一层的圆进行合并时,可以使用神经网络对任意函数进行逼近。且目标函数不一定是连续的。、
把这个性质和傅里叶级数逼近联系起来并不困难,换句话说,就是每个函数曲线都可以分解成许多简单曲线的和。有了这种联系,要表明这种普遍的逼近性质,就是要表明任何一个单隐层的神经网络都可以表示一个简单的曲面,然后第二个隐层将这些简单的曲面求和来逼近一个任意的函数。
一个隐藏层神经网络只需执行一个阈值求和操作,因此,仅剩下的一步是表明第一个隐藏层可以表示一个简单的曲面。为了理解"简单表面",结合傅里叶变换,人们可以想象一维情况下正弦曲线的一个周期,或者二维情况下平面的一个"凸点"。然后,利用f1 ( x ) + f2 ( x ),从t1≤x≤t2开始创建一个高度为2h的简单曲面。这可以很容易地推广到n维情形,即对于每个简单曲面,我们需要2n个Sigmoid函数(神经元)。然后对于每个对最终函数有贡献的简单曲面,在第二个隐藏层上添加一个神经元。因此,尽管需要神经元的数量,人们永远不需要第三个隐藏层来逼近任何函数。
万能逼近特性显示了浅层神经网络的巨大潜力,但代价是这些层上的神经元数量成倍增加。随之而来的一个问题是,如何在保持表征能力的同时减少所需神经元的数量。尽管浅层神经网络已经具有无限的建模能力,但这个问题促使人们转向更深层的神经网络。另一个值得关注的问题是,虽然神经网络可以逼近任意函数,但是寻找一组参数来解释数据并不是一件平凡的事情。在接下来的两节中,我们将分别讨论这两个问题.
(这段证明没有认真看)
The Necessity of Depth深度的必要性
浅层神经网络的万能逼近特性是以指数级的大量神经元为代价的,但是实际是不现实的。如何在减少计算单元数量的同时保持网络的这种表达能力是多年来一直被问及的问题。Bengio( 2011 )认为,追求更深层次的网络是自然的。
1)人类的神经系统是一个深层的架构。
2 )人类倾向于将一个抽象层次的概念表示为低层次概念的组合。
有一个观点是:如果使用k - 1层结构,那么具有多项式多个神经元的k层神经网络的表示能力需要用指数多个神经元来表示。然而,从理论上讲,这一结论仍在完善之中。(意思是如果使用k层神经网络,就可以使用多项式级别的多个神经元进行表示,但是如果变成k-1就需要指数级别的才能进行表示?)
这一结论可以追溯到30年前关于浅层电路功能的局限性的问题。Hastad ( 1986 )后来用奇偶电路证明了这一性质:"存在以多项式大小和深度k可计算的函数,但当深度限制在k - 1时需要指数大小"。他主要通过应用德摩根定律来说明这一性质,即任何AND或OR都可以改写为AND的OR,反之亦然(这个内容在布尔逼近中提到了)。因此,他通过将一层AND改写成OR,简化了AND和OR相继出现的电路,并将这一操作合并到其相邻的OR层。通过重复这个过程,他能够用更少的层来表示相同的函数,但计算量更大。
从电路到神经网络,德拉洛和Bengio ( 2011 )比较了深度和浅层的和积神经网络。他们指出,一个可以用深度为k的网络上的O ( n )个神经元表示的函数至少需要两层神经网络上的O ( 2√n )和O( ( n-1 ))k )个神经元。进一步地,比安基尼和斯卡尔塞利( 2014 )将该研究推广到了包含tanh和sigmoid等多个主要激活函数的一般神经网络。他们表明,对于浅层网络,表示能力只能关于神经元数量呈多项式增长,但对于深层结构,表示能力可以关于神经元数量呈指数增长。Eldan和Shamir ( 2015 )给出了一个更充分的证明,证明了对于一个标准的MLP,对于任何流行的激活函数,神经网络的深度都比神经网络的宽度更有价值。他们的结论是在仅有的几个弱假设下得出的,这些假设限制了激活函数是轻度增加的,可测量的,并且能够允许浅层神经网络逼近任何单变量Lipschitz函数。
这部分内容的主要思想就是:通过使用更深的网络,可以在使用更少神经元的情况下仍让网络保持同样的表达能力,甚至更好的表达能力。
但是在当时,如果继续增加层数,就会出现很多问题。其中,学习适当参数的难度增加可能是最突出的一个。因此有了下文对反向传播的讨论。
反向传播及其性质
反向传播这个名称最初并不是指用于学习神经网络参数的算法,而是指在应用梯度下降算法学习参数( Hecht-Nielsen , 1989)时,能够有效计算参数梯度的技术。
这里将讨论反向传播的两个有趣且看似矛盾的性质。
Backpropagation Finds Global Optimal for Linear Separable Data反向传播算法对线性可分数据寻找全局最优
Gori和Tesi ( 1992 )研究了反向传播中的局部极小值问题。有趣的是,当社会认为神经网络或深度学习方法被认为会进入局部最优时,他们提出了一种保证全局最优的体系结构。只需要网络的几个弱假设就可以达到全局最优,包括·
金字塔结构:上层神经元数量较少·
权重矩阵是满行秩的·
输入神经元的数量不能小于数据的类别/模式。
Backpropagation Fails for Linear Separable Data对于线性可分数据,反向传播失败
另一方面,Brady等( 1989 )研究了线性可分数据集上反向传播失败的情况。他指出,当数据是线性可分的时候可能会出现这种情况,但是用反向传播学习的神经网络不能找到这种边界。他还展示了这种情况发生时的例子。他的例证只有在错误分类的数据样本显著少于正确分类的数据样本时才成立,也就是说,错误分类的数据样本可能只是异常值(??)。因此,这个有趣的性质,在今天看来,可以说是反向传播的一个理想属性,因为我们通常期望机器学习模型忽略异常值。因此,这一发现并没有引起太多的关注。
反向传播可以实现深度神经网络的优化。但是,距离我们能够很好地对其进行优化还有很长的一段路要走。在第7节的后面,我们将简要讨论与神经网络优化相关的更多技术。















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









