






一.概述
1.推荐算法(recommendation algorithm):
推荐算法是计算机专业中的一种算法,通过一些数学算法,推测出用户可能喜欢的东西,目前应用推荐算法比较好的地方主要是网络,其中淘宝做的比较好。所谓推荐算法就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西。
详情参考:https://baike.so.com/doc/962578-1017418.html
2.实例:
在推荐系统中,最重要的数据是用户对商品的打分数据,数据形式如下所示:
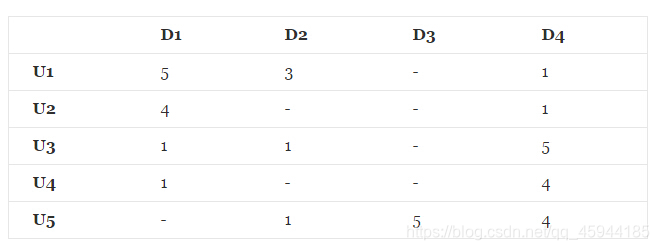
其中,U1⋯U5表示的是5个不同的用户,D1⋯D4表示的是4个不同的商品,这样便构成了用户—商品矩阵,在该矩阵中,用户对每一件商品的打分,其中“-”表示的是用户未对该商品进行打分。
二.矩阵分解算法
1.矩阵分解的一般形式
矩阵分解是指将一个矩阵分解成两个或者多个矩阵的乘积。对于上述的用户-商品矩阵(评分矩阵),记为Rm×n。可以将其分解成两个或者多个矩阵的乘积,假设分解成两个矩阵Pm×k和Qk×n,我们要使得矩阵Pm×k和Qk×n的乘积能够还原原始的矩阵Rm×n:
Rm×n≈Pm×k × Qk×n=R^m×n
其中,矩阵Pm×k表示的是m个用户与k个主题之间的关系,而矩阵Qk×n表示的是k个主题与n个商品之间的关系。在算法里面k是一个参数,需要调节的,通常10~100之间。
2.损失函数
首先令:
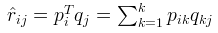
其次使用原始的评分矩阵与重新构建的评分矩阵构建损失函数:
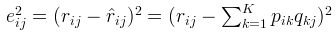
最终求出所有"-"项的损失之和的最小数:
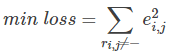
3.更新变量
求导:
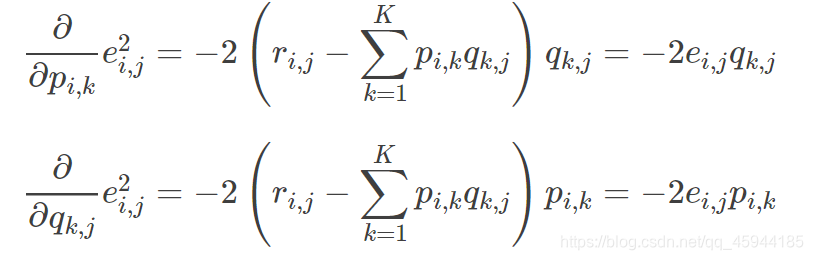 根据负梯度的方向更新变量:
根据负梯度的方向更新变量:
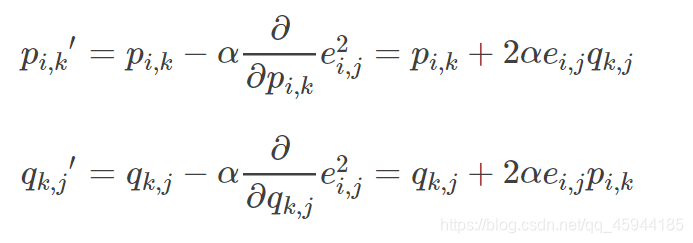 4.加入正则化项
4.加入正则化项
通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入L2正则的损失函数为(其中加号后面的为正则化项):
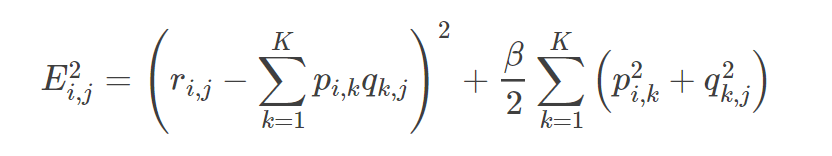 求导:
求导:
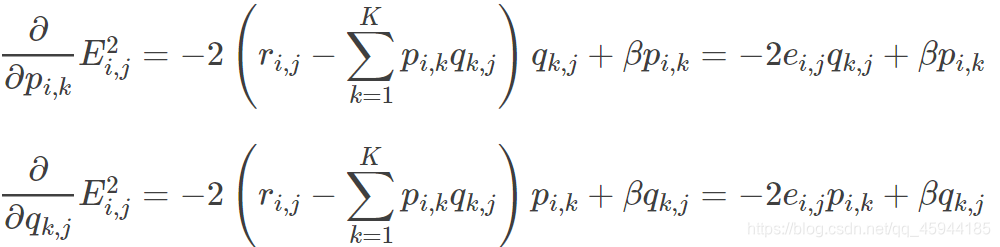 根据负梯度的方向更新变量:
根据负梯度的方向更新变量:
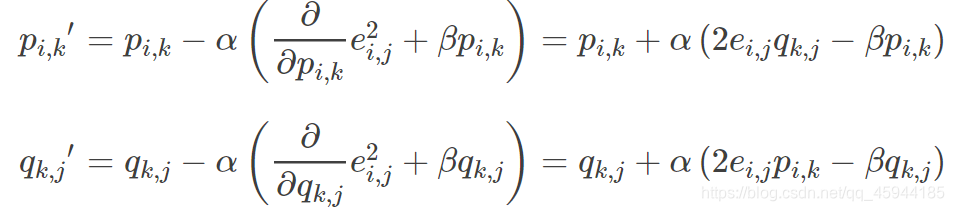 注:每次更新完后,计算一次loss值,若loss值非常小或者到达最大迭代次数,结束算法。于是就得到了我们最终的预测矩阵
注:每次更新完后,计算一次loss值,若loss值非常小或者到达最大迭代次数,结束算法。于是就得到了我们最终的预测矩阵
三.Python代码实现
import numpy as np
import math
import matplotlib.pyplot as plt
#定义矩阵分解函数
def Matrix_decomposition(R,P,Q,N,M,K,alpha=0.0002,beta=0.02):
Q = Q.T #Q矩阵转置
loss_list = [] #存储每次迭代计算的loss值
for step in range(5000):
#更新R^
for i in range(N):
for j in range(M):
if R[i][j] != 0:
#计算损失函数
error = R[i][j]
for k in range(K):
error -= P[i][k]*Q[k][j]
#优化P,Q矩阵的元素
for k in range(K):
P[i][k] = P[i][k] + alpha*(2*error*Q[k][j]-beta*P[i][k])
Q[k][j] = Q[k][j] + alpha*(2*error*P[i][k]-beta*Q[k][j])
loss = 0.0
#计算每一次迭代后的loss大小,就是原来R矩阵里面每个非缺失值跟预测值的平方损失
for i in range(N):
for j in range(M):
if R[i][j] != 0:
#计算loss公式加号的左边
data = 0
for k in range(K):
data = data + P[i][k]*Q[k][j]
loss = loss + math.pow(R[i][j]-data,2)
#得到完整loss值
for k in range(K):
loss = loss + beta/2*(P[i][k]*P[i][k]+Q[k][j]*Q[k][j])
loss_list.append(loss)
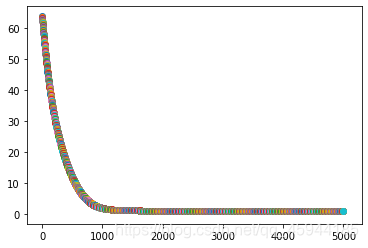
plt.scatter(step,loss)
#输出loss值
if (step+1) % 1000 == 0:
print("loss={:}".format(loss))
#判断
if loss < 0.001:
print(loss)
break
plt.show()
return P,Q
if __name__ == "__main__":
N = 5
M = 4
K = 5
R = np.array([[5,3,0,1],
[4,0,0,1],
[1,1,0,5],
[1,0,0,4],
[0,1,5,4]]) #N=5,M=4
print("初始评分矩阵:")
print(R)
#定义P和Q矩阵
P = np.random.rand(N,K) #N=5,K=2
Q = np.random.rand(M,K) #M=4,K=2
print("开始矩阵分解:")
P,Q = Matrix_decomposition(R,P,Q,N,M,K)
print("矩阵分解结束。")
print("得到的预测矩阵:")
print(np.dot(P,Q))
结果:
运行结果:
初始评分矩阵:
[[5 3 0 1]
[4 0 0 1]
[1 1 0 5]
[1 0 0 4]
[0 1 5 4]]
开始矩阵分解:
loss=2.0892998707976247
loss=1.2332798795187576
loss=1.1769570383770755
loss=1.1599470701741768
loss=1.1540725163786416
矩阵分解结束。
得到的预测矩阵:
[[4.97910806 2.97663711 3.57179496 1.00321826]
[3.97953072 2.00384955 3.07816994 1.0001903 ]
[1.01333835 0.96710297 5.04188003 4.97002944]
[0.99365904 1.1291602 4.07478463 3.98267432]
[2.19988958 1.03578547 4.97586767 3.99549984]]
注意问题:
1.正则化(regularization),是指在线性代数理论中,不适定问题通常是由一组线性代数方程定义的,而且这组方程组通常来源于有着很大的条件数的不适定反问题。大条件数意味着舍入误差或其它误差会严重地影响问题的结果。
2.正则化就是对最小化经验误差函数上加约束,这样的约束可以解释为先验知识(正则化参数等价于对参数引入先验分布)。约束有引导作用,在优化误差函数的时候倾向于选择满足约束的梯度减少的方向,使最终的解倾向于符合先验知识
同时,正则化解决了逆问题的不适定性,产生的解是存在,唯一同时也依赖于数据的,噪声对不适定的影响就弱,解就不会过拟合,而且如果先验(正则化)合适,则解就倾向于是符合真解(更不会过拟合了),即使训练集中彼此间不相关的样本数很少。
3.反问题有两种形式。最普遍的形式是已知系统和输出求输入,另一种系统未知的情况通常也被视为反问题。
4.设A为m×n阶矩阵(即m行n列),第i 行j 列的元素是a(i,j),即:A=a(i,j)
定义A的转置为这样一个n×m阶矩阵B,满足B=a(j,i),即 b (i,j)=a (j,i)(B的第i行第j列元素是A的第j行第i列元素),记A’=B。(有些书记为AT=B,这里T为A的上标)
直观来看,将A的所有元素绕着一条从第1行第1列元素出发的右下方45度的射线作镜面反转,即得到A的转置。
即:
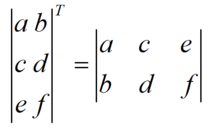














 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









