




 该文章提出了时空记忆网络(STMN)来应对视频行人重识别中的挑战,如背景杂波和部分遮挡。STMN包括空间记忆和时间记忆,分别用于抑制空间干扰和优化时间模式的注意力。通过使用记忆扩散损失,模型能更有效地处理多种干扰并生成区分度高的行人表征。实验结果证明了STMN的有效性。
该文章提出了时空记忆网络(STMN)来应对视频行人重识别中的挑战,如背景杂波和部分遮挡。STMN包括空间记忆和时间记忆,分别用于抑制空间干扰和优化时间模式的注意力。通过使用记忆扩散损失,模型能更有效地处理多种干扰并生成区分度高的行人表征。实验结果证明了STMN的有效性。
本文是韩国延世大学,电气与电子工程学院所发表的基于视频行人重识别的文章。
文章地址:https://openaccess.thecvf.com/content/ICCV2021/papers/Eom_Video-Based_Person_Re-Identification_With_Spatial_and_Temporal_Memory_Networks_ICCV_2021_paper.pdf
源码地址:https://github.com/cvlab-yonsei/STMN
Abstract
人物视频中的空间和时间干扰因素,例如背景杂波和帧上的部分遮挡,分别使这项任务比基于图像的人物识别更具挑战性。我们观察到空间干扰物在特定位置一致地出现,而时间干扰物则表现出几种模式,例如,部分遮挡出现在前几帧,这种模式为预测关注哪一帧提供了信息线索(即时间注意力)。在此基础上,我们提出了一种新的时空记忆网络(STMN)。空间记忆存储了视频帧中频繁出现的空间干扰特征,而时间记忆存储了针对真人视频中典型时间模式优化的注意力。我们利用空间和时间记忆分别细化帧级人物表示,并将细化的帧级特征聚合到序列级人物表示中,有效地处理人物视频中的空间和时间干扰。我们还引入了内存扩散损失,防止我们的模型只在内存中处理特定的项目。
Introduction
1、作者的想法
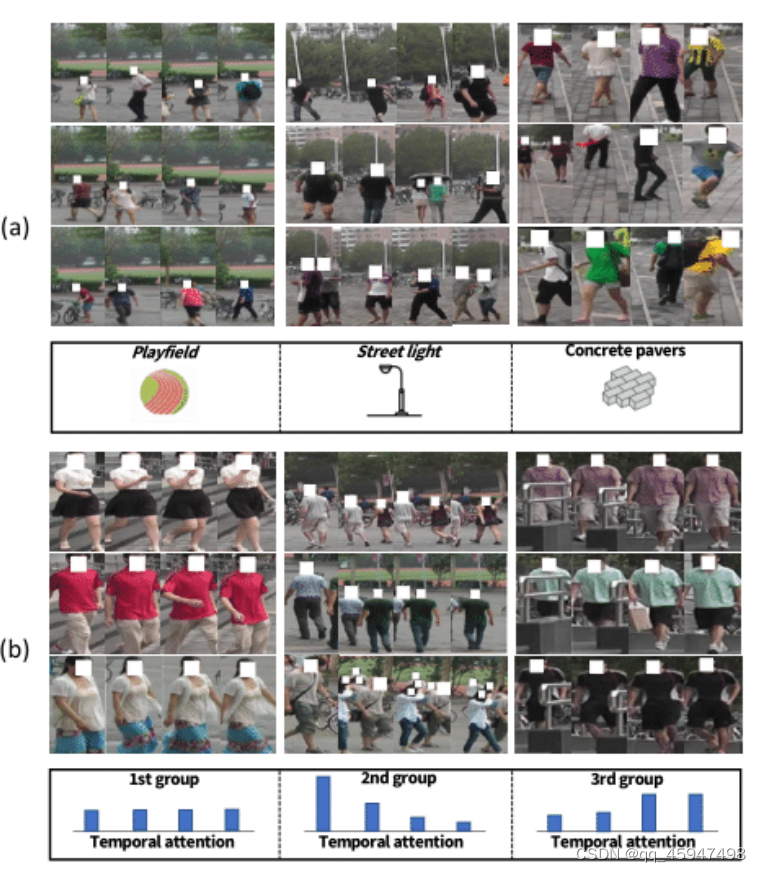
①数据来自固定相机拍摄,因此背景会产生杂物
②时间上会出现时间模式(就是时序上会出现的问题,作者归结为时间模式)
2、基于上述想法,提出STMN框架利用空间memory和时间memory
STMN框架具体工作
STMN框架主要由encoder、spatial memory、temporal memory组成
- encoder
用于提取行人表征和两个查询映射(query map),并且每个查询向量分别用于访问spatial memory、temporal memory。 - spatial memory
存储场景细节以及在视频中频繁出现的干扰特征。使用查询向量从空间记忆中提取这些特征,并使用这些特征去细化行人表征,抑制干扰行人识别的信息。 - temporal memory
存储行人视频中重复出现的典型的时间模式,对时间模式的注意力进行优化。使用查询向量访问时间记忆,并将细化后的帧级特征聚合到序列级的行人表征上。
在训练阶段使用memory spread 、三元组和交叉熵损失进行训练。memory spread loss可以防止模型对少数记忆相重复访问,激励模型访问所有项。
STMN中每个模块的具体流程
STMN框架图

encoder
- 将视频序列作为输入 F i ∣ i = 1 L F_{i}|^{L}_{i=1} Fi∣i=1L,i为序列的第i帧,L为帧的总数量
- 将ResNet50作为网络的骨干。在本文中作者将ResNet50的stage4层替换为3个head。这3个head分别用于提取行人表征 f i o f^{o}_{i} fio、空间查询向量 q i s q^{s}_{i} qis和时间查询向量 q i t q^{t}_{i} qit
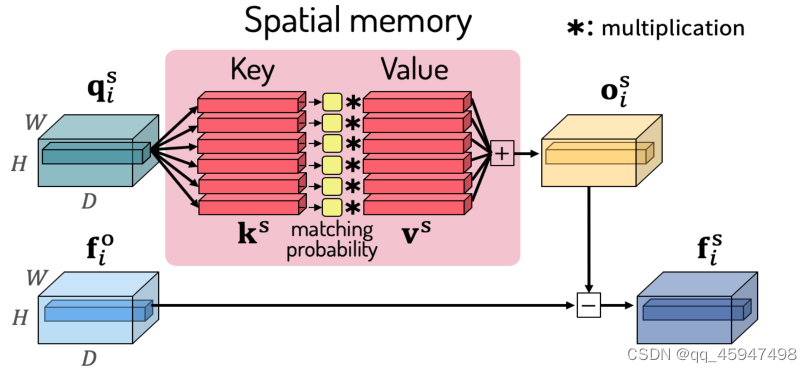
Spatial Memory
1、主要作用:
从下图中我们可以看到在相同背景不同行人的情况下,特征提取的注意力在背景上而不是在行人的位置上,所以 Spatial Memory的作用就是抑制特征中背景杂物,使注意力重新回到行人上。

2、具体流程
-
将 f i o f^{o}_{i} fio和 q i s q^{s}_{i} qis作为输入,由于输入帧的不同部分可能包含有区别的场景细节,使用查询向量访问各个组将的memory。
-
在memory中使用q和k计算余弦相似度,并产生一个1*m的匹配概率图 a i , k , n s a^{s}_{i,k,n} ai,k,ns
a i , k , n s = e x p ( ( q i , k s ) T K n s ) ∑ n = 1 M e x p ( ( q i , k s ) T K n s ) a^{s}_{i,k,n}=\frac{exp((q^{s}_{i,k})^{T}K^{s}_{n})}{ {\textstyle \sum_{n=1}^{M}}exp((q^{s}_{i,k})^{T}K^{s}_{n})} ai,k,ns=∑n=1Mexp((qi,ks)TKns)exp((qi,ks)TKns)
匹配概率图 a i , k , n s a^{s}_{i,k,n} ai,k,ns表示为记录在第n个内存项中的场景细节存在于第i帧的第K个位置的可能性 -
使 a i , k , n s a^{s}_{i,k,n} ai,k,ns与 v n s v^{s}_{n} vns做一个加权平均值
O i , k s = ∑ n = 1 M a i , k , n s v n s O^{s}_{i,k}=\sum_{n=1}^{M}a^{s}_{i,k,n}v^{s}_{n} Oi,ks=n=1∑Mai,k,nsvns
O i , k s O^{s}_{i,k} Oi,ks表示对于第i帧的第k个位置。删除干扰识别行人的信息特征 -
细化行人表征 f i , k s = f i , k o − B N ( O i , k s ) f^{s}_{i,k} =f^{o}_{i,k}-BN(O^{s}_{i,k}) fi,ks=fi,ko−BN(Oi,ks)。BN层用于调整编码器输出和存储器之间的分布差距
-
模型中k和v是外部参数(自己初始化的,源代码中可见)通过反向传播进行更新,self-attention的k和v是通过输入特征计算出来的
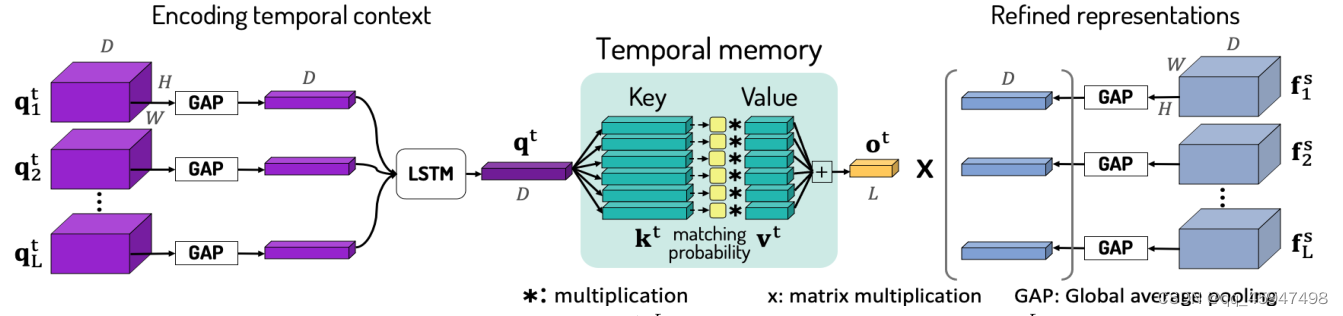
Temporal Memory
1、主要作用:
对于较少干扰的输入序列,memory与时间平均池化类似,融合相同概率的视频帧。
对于受干扰的输入序列,temporal memory使模型提取对时间变化具有健壮性的行人表征

2、具体流程
-
将spatial memory细化后的表征 f i , k s f^{s}_{i,k} fi,ks与 时间查询向量 q i t q^{t}_{i} qit作为输入
-
我们首先编码给定序列的时间上下文,例如,遮挡出现在中间帧,使用查询映射。生成 q i t q^{t}_{i} qit
-
使用全局平均池化(GAP)对 q i t q^{t}_{i} qit进行空间聚合,并将其输入到LSTM中:
q t = L S T M [ G A P ( q 1 t ) , G A P ( q 2 t ) , . . . , G A P ( q L t ) ] q^{t}=LSTM[GAP(q^{t}_{1}),GAP(q^{t}_{2}),...,GAP(q^{t}_{L})] qt=LSTM[GAP(q1t),GAP(q2t),...,GAP(qLt)] -
将 q t q^{t} qt用于访问temporal memory
-
匹配概率 a n t a^{t}_{n} ant,表示编码时间上下文 q t q^{t} qt属于时间模式存储在第n个记忆项 K n t K^{t}_{n} Knt的概率
a n t = e x p ( ( q t ) T K n t ) ∑ n = 1 M e x p ( ( q t ) T K n t ) a^{t}_{n}=\frac{exp((q^{t})^{T}K^{t}_{n})}{ {\textstyle \sum_{n=1}^{M}}exp((q^{t})^{T}K^{t}_{n})} ant=∑n=1Mexp((qt)TKnt)exp((qt)TKnt) -
时间注意力
o t = ∑ n = 1 M a n t v n t o^{t}=\sum_{n=1}^{M}a^{t}_{n}v^{t}_{n} ot=n=1∑Mantvnt -
o i t o^{t}_{i} oit表示第i个输出的元素,表明在序列中第i个项的相关重要性
f t = ∑ n = 1 N o ^ i t G A P ( f i s ) f^{t}=\sum_{n=1}^{N}\hat{o}^{t}_{i}GAP(f^{s}_{i}) ft=n=1∑No^itGAP(fis)这个公式相当于空间和时间的特征融合。其中
o ^ i t = e x p ( o i t ) ∑ i = 1 L e x p ( o i t ) \hat{o}^{t}_{i}=\frac{exp(o^{t}_{i})}{{\textstyle\sum_{i=1}^{L}}exp(o^{t}_{i})} o^it=∑i=1Lexp(oit)exp(oit) -
f t f^{t} ft是最终的行人表征
先前的方法是根据人的表征来决定在时间融合过程中关注哪些帧。这可能会强制表示对时间背景以及与身份相关的线索进行编码,防止表示具有歧视性,特别是当不同身份的视频序列包含类似的时间背景时。相反,在我们的框架中,人员表示与编码时间上下文分离,其中查询映射 q i t q^{t}_{i} qit和临时存储器 k t k^{t} kt中的键,对这些上下文进行编码。这鼓励我们的模型提取人员表示,重点关注对区分不同身份有用的信息,从而提高reID任务的性能。
Train loss
L
t
o
t
a
l
=
L
s
+
L
I
D
L_{total}=L_{s}+L_{ID}
Ltotal=Ls+LID
L
s
L_{s}
Ls为memory spread loss:使模型可访问多个项,而不是特定的项
L
s
=
∑
n
=
1
M
[
m
i
n
(
a
n
s
)
−
m
a
x
(
a
n
s
)
]
+
+
[
m
i
n
(
a
n
t
)
−
m
a
x
(
a
n
t
)
]
+
L_{s}=\sum_{n=1}^{M} [min(a^{s}_{n})-max(a^{s}_{n})]_{+}+[min(a^{t}_{n})-max(a^{t}_{n})]_{+}
Ls=n=1∑M[min(ans)−max(ans)]++[min(ant)−max(ant)]+
L
I
D
L_{ID}
LID可以从视频序列中提取有区别的行人表征
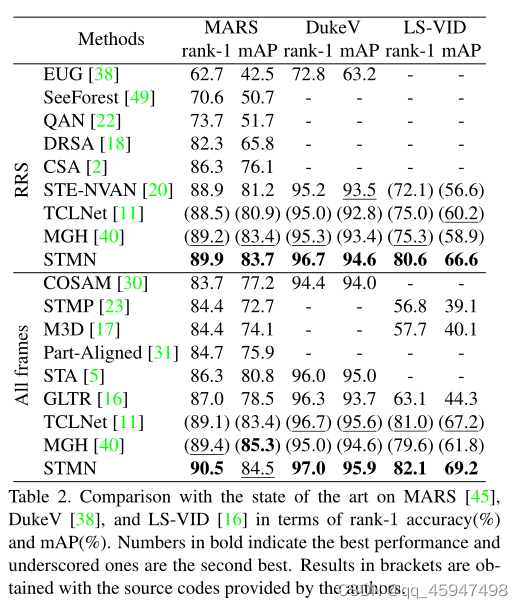
结果
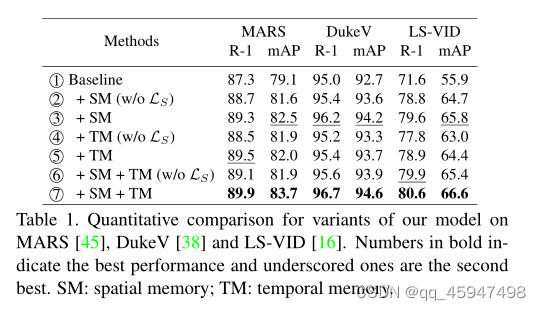
模型比较

















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









