







Multi-Scale Temporal Cues Learning for Video Person Re-Identification
用于视频行人重识别的多尺度时间线索学习
1、摘要
摘要中提到将时间线索嵌入到视频中对于行人重识别是一个非常重要的线索。
为了解决将时间线索嵌入应用到ReID中,提出了一个新的方法,在原来的2D卷积网络中,添加一个新的被叫做M3D(Multi-scale 3D convolution layer)的卷积层。根据M3D在2D卷积网络插入的位置,可分为局部M3D和全局M3D。
局部M3D层被插入2D卷积层之间,用来学习相邻2D特征图之间的空时域线索。
全局M3D被用来计算相邻帧特征向量,以学习它们的全局时间关系。
因此,局部和全局M3D层学习互补的时间线索。它们的组合为传统的2DCNN引入了一小部分参数,但产生了强大的多尺度时间特征学习的能力。
可学习的时间和空间的特征的融合,可以构成视频行人重识别的最终空时域表示。
这篇论文用了4个视频行人ReID数据集:1、MARS,accuracy有88.63%,2、DukeMTMC-VideoReID,3、PRID2011,4、iLIDS-VID
2、结论
结论的内容与摘要一样
3、introduction
1.介绍什么是行人重识别和行人重识别应用场景
行人重识别通过匹配他的图片或者来自其他摄像机的视频序列来识别特定的人。
应用场景:在安全领域相关的应用。例如,智慧监控、犯罪调查
2.为什么要将时间和空间线索相结合
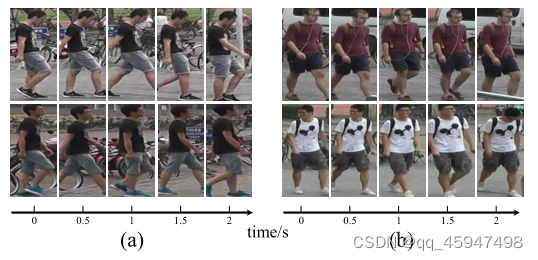
在图像领域行人ReID取得显著的成功,但是在视频领域中会出现问题。如图1中的两组数据(a)是外观相同但步态不同,(b)是步态相似但外观不同。因此(a)在视觉上很难单独区分,但是通过时间线索可以快速区分。而(b)在时间线索上难以区分,但在空间线索(也就是视觉上)上容易区分。因此作者就提出了如果同时利用时间和空间的信息来提高视频行人的ReID的精度。
与会议版相比,本作有以下不同之处。 1) 我们分别设计了两种 M3D 层变体,例如全局 M3D 和局部 M3D。局部 M3D 层捕获局部时空细节,但可能对相邻帧之间的未对齐敏感。因此,全局 M3D 层应用于相邻帧特征以学习全局时间线索,并提高特征鲁棒性。尽管 M3D 层是时间线索学习的通用结构,但其局部和全局变体在不同的特征尺度上工作并学习互补特征。
3.在视频行人ReID上的当前的一些研究方法以及不足之处
a、通过池化层和融合权重学习提取帧级和产生视频特征 。通过池化产生的特征不会受到视频帧顺序的影响,因此不能有效地表示时间线索。
b、对optical flow中提取的空间和额外的时间线索进行融合。这个方法在时间线索上有效,对空间线索不敏感。
c、利用RNN将提取的帧级特征去产生视频特征。RNN只能计算时间线索想过的特征,但是抓不住时间线索上的细节特征。
d、利用3D CNN。3D CNN覆盖的时间范围太短;产生的参数过多,导致计算量太大。
e、M3D CNN(作者提出来的)与2D CNN进行残差连接的方式相结合。

4.贡献
1、针对视频行人ReID提出了一个新的M3D卷积层去共同学习多尺度时间线索。
2、提出了由M3D CNN和 2D CNN组成的双流框架来学习空间和时间的特征,
3、这是视频行人ReID研究轻量级高效3D CNN的早期尝试
4、相关工作
本章节将图像重识别领域的相关方法和视频重识别的相关算法做了简要的介绍。并且引出作者的方法与前人方法的不同
1.作者的方法是在一个紧密的单流3D CNN中使用扩展的时间卷积(dilated temporal convolution)去完成多尺度的特征学习。
2.与使用堆叠的光流(optical flow)作为输入的先前工作不同,我们的方法直接从最初的视频序列中提取时间特征。
5、M3D卷积网络
- 整个模型采用的是双流的网络架构模式。
- 在框架的右边采用的是2D CNN网络架构模式,主要是为了提取空间特征。
- 在框架的左边采用的多尺度3D卷积神经网络,主要是为了提取时间特征。
- 多尺度3D卷积神经网络主要是将M3D层去替换掉原来的2D卷积网络层替换。
- 根据M3D在2D卷积网络层替换的位置,可分为局部M3D层和全局M3D层。
- 在最后,采用简单高效的Concat进行连接。
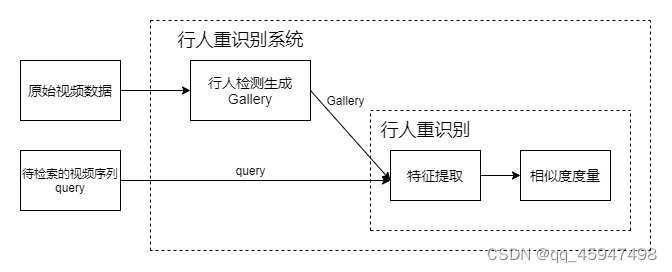
1.行人重识别的总体框架
给定一个待查询的视频序列query,给定一个gallery(就是原始视频序列的数据集),对query和gallery的序列进行特征提取,通过距离度量的方式,计算出query与gallery的相似度,并返回一组排列的列表。
行人检测:通过目标检测器识别出原始视频数据中的人,并且将识别后的数据生成视频序列gallery
特征提取:本文中特征提取主要采用的是双流的网络架构
2.将问题公式化
将空间和时间线索嵌入视频序列对于识别单独的行人是非常重要的。由于空间和时间是相互补充的,我们用两个模型去提取。
f
=
[
f
s
,
f
t
]
v
i
d
e
o
r
e
p
r
e
s
e
n
t
a
t
i
o
n
f
,
f
s
与
f
t
分别表示空间和时间上的表示。
[
,
]
表示特征的融合
f = [f_{s}, f_{t}]\\ video \; representation f,f_{s}与f_{t}分别表示空间和时间上的表示。 [ \;,\; ]表示特征的融合
f=[fs,ft]videorepresentationf,fs与ft分别表示空间和时间上的表示。[,]表示特征的融合
其中,fs和ft分别表示空间和时间表示,[,]表示特征融合,可以使用包括加权融合和自适应融合在内的不同策略来实现。本文利用矢量拼接的简单性和高效性

提取序列空间特征f_{s}的完成是通过从每一个单独的视频帧中首次提取空间表示
f
s
=
1
T
∑
t
=
1
T
F
2
d
(
S
t
)
f_{s}=\frac{1}{T} \sum_{t=1}^{T} F_{2d}(S^{t} )
fs=T1t=1∑TF2d(St)
对于时间表示f_{t}我们提出了一个M3D CNN从视频序列中提取时间特征
f
t
=
F
M
3
D
(
S
)
f_{t}=F_{M3D}(S)
ft=FM3D(S)
f t = a v g p o o l ( F ˉ ) = 1 T ∑ t = 1 T F ˉ [ t , 1 , 1 ] f_{t}=avgpool(\bar{F} )=\frac{1}{T} \sum_{t=1}^{T} \bar{F} [t,1,1] ft=avgpool(Fˉ)=T1t=1∑TFˉ[t,1,1]
在2D CNN这边 通过Temporal Pooling 来聚集帧特征
3.多尺度3D卷积
局部M3D层:
3D神经网络的缺点促使我们设计一个紧凑的卷积核,以捕获更长的时间线索。受碰膨胀卷积的启发,我们提出在时间维度上并行膨胀卷积来捕获时间线索。
当n=3时如图所示,局部M3D层具有比传统3D卷积更大的时间感受野,例如,覆盖9个时间维度。局部M3D层的另一个优点是通过多个时间内核学习长时间线索和短时间线索。此外,如图所示,通过残差连接插入多个时间核,任何2D CNN层都可以成为局部M3D层。这种结构允许使用训练有素的2D CNN层初始化局部M3D。例如,M3D层可以通过将时间内核的权重设置为0来初始化,这等于2D CNN层。在良好的2D CNN模型上初始化,本地M3D模型将更容易通过模型微调进行优化。

与现有的I3D和P3D层类似,局部M3D层中的每个神经元都有固定的空间感受野,因此可能对失准误差敏感。我们继续提出全局M3D层以增强学习的时间特征的鲁棒性。
全局M3D层:
进一步提出全局M3D层来从帧级特征学习时间线索
与局部M3D层类似,全局M3D层也由并行扩展卷积组成,以覆盖多尺度时间范围。
在全局M3D层,我们给定一个输入
F
∈
R
d
×
T
×
1
×
1
F \in R^{d \times T \times 1 \times 1}
F∈Rd×T×1×1
经过下面公式
F
ˉ
(
i
)
=
τ
ˉ
(
i
)
(
F
)
,
F
ˉ
(
i
)
[
t
,
1
,
1
]
=
∑
a
=
−
1
1
F
[
t
+
a
×
r
ˉ
(
i
)
,
1
,
1
]
×
W
‾
(
i
)
[
a
]
\bar{F}^{(i)}=\bar{\tau }^{(i)}(F),\\ \bar{F}^{(i)}[t, 1,1]=\sum_{a=-1}^{1} F\left[t+a \times \bar{r}^{(i)}, 1,1\right] \times \overline{\mathbf{W}}^{(i)}[a]
Fˉ(i)=τˉ(i)(F),Fˉ(i)[t,1,1]=a=−1∑1F[t+a×rˉ(i),1,1]×W(i)[a]
计算得出全局M3D层的输出
F
ˉ
∈
R
(
n
+
1
)
d
×
T
×
1
×
1
\bar{F} \in R^{(n+1)d \times T \times 1 \times 1}
Fˉ∈R(n+1)d×T×1×1 这是F和来自n个并行扩展时间卷积的输出的组合。
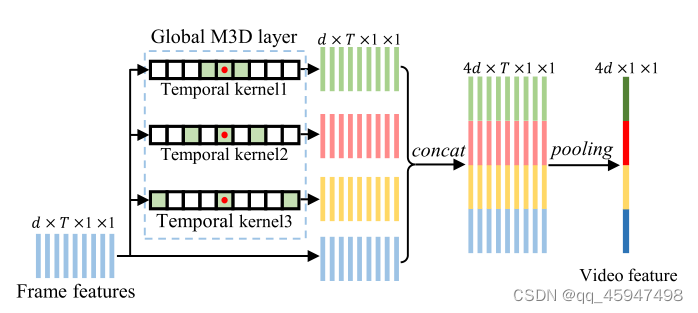
局部和全局M3D的区别,全局M3D层是基于全局特征向量计算的,因此在更大的空间尺度上学习时间线索。这使得全局M3D层对未对准误差更加鲁棒,并提高了特征鲁棒性。
4.单流M3D网络视频特征的产生:
最后的视频特征是空间特征和时间特征的级联。应用时间平均池化来生成固定长度的时间特征,
temporal pooling:
直接聚合所有时间戳中的帧特征。在图像行人ReID中针对特征融合多用temporal pooling或者权重学习的策略
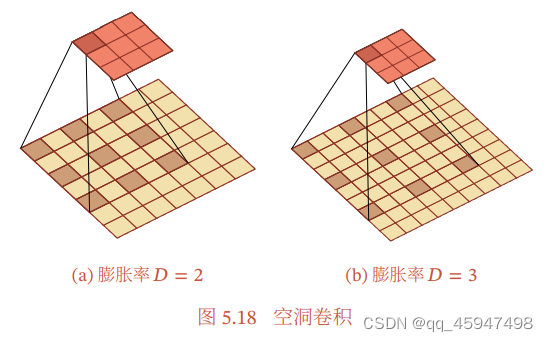
5.空洞卷积(也称为膨胀卷积)
空洞卷积是一种不增加参数数量,同时增加输出单元感受野的一种方式。空洞卷积通过给卷积核插入“空洞”来变相增加其大小。如果在卷积核的每两个元素之间插入D-1个空洞,卷积核的有效大小为
K
′
=
K
+
(
K
−
1
)
×
(
D
−
1
)
{K}'= K+(K-1)\times(D-1 )
K′=K+(K−1)×(D−1)
其中D称为膨胀率(本文中膨胀率为r)。当D=1时卷积核为普通的卷积核。















 3252
3252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









