







本文主要是由中国科学院智能信息处理重点实验室发表的论文。
文章地址:https://openaccess.thecvf.com/content/CVPR2021/papers/Hou_BiCnet-TKS_Learning_Efficient_Spatial-Temporal_Representation_for_Video_Person_Re-Identification_CVPR_2021_paper.pdf
源代码位置https://github.com/blue-blue272/BiCnet-TKS
Abstract
本文提出了一种有效的视频人物再识别的时空表示方法。
首先,我们提出了一个双边互补网络(BiCnet)来进行空间互补建模。具体来说,BiCnet包含两个分支。细节分支以原始分辨率处理帧以保留详细的视觉线索,上下文分支采用下采样策略捕获长范围上下文。在每个分支上,BiCnet添加多个并行且多样化的注意模块,对连续帧发现发散的身体部位,从而获得目标身份的整体特征。此外,还设计了一个时序核选择(TKS)块,通过自适应模式捕获短期和长期的时序关系。TKS可以任意深度插入BiCnet,构建BiCnetTKS进行时空建模。在多个基准测试上的实验结果表明,BiCnet-TKS的计算量减少了约50%,优于先进水平。
Introduce
1、想法
空间上:双分支结构在相同输入分辨率下,对每一帧进行相同的操作会导致连续帧有高度冗余的空间特征,这些冗余特征容易关注到具有代表性的局部区域。(即看似相同的局部身体部分难以分辨)
时间上:长期时序相关性对减轻遮挡十分重要
短期时序相关性对于快速移动的行人序列在细节动作建模上有重要作用
2、模型设计思想
-
BiCnet(Bilateral Complementary Network)采用双分支结构(细节分支(detail branch)和上下文分支(context brance))对不同视频子部分的互补尺度进行建模。
- 细节分支以输入分辨率操作帧,保留空间细节。
- 上下文分支以下采样分辨率处理帧,相对于细节分支,上下文分支的感受野较大,可以与细节分支所提取的细节特征互补。
- 在两个分支之间有一个CSP(cross-scale paths)模块,其作用就是将细节分支提取的特征传递给上下文分支,使其能够集中到长范围视觉线索以外的线索。
- 在每一条分支上都加上一个DAO(diverse attention operation)。原因:尽管双分支可以提取出互补的线索,但是仍然会轻易的集中到具有代表性的区域周围。因此他的作用就是使BiCnet可以获取目标行人的必要特征,产生更全面空间表征
-
TKS(Temporal Kernel Select block)模块用来对长短期时间相关性进行建模。由于不同尺度下的时间相关性对不同序列的重要性不同。因此TKS可以将多尺度的时间关系动态地结合,并根据输入序列的不同时间尺度赋予不同的权重。TKS包含分区操作、选择操作、激活操作
- 分区操作:减轻空间错位问题
- 选择操作:使用来自所有时间路径的全局信息来决定每个路径的分配权重
- 激活操作
BiCnet与TCLNet区别
| BiCnet | TCLNet |
|---|---|
| 有两个分支可同时提取细节特征和上下文特征 | 只考虑一个空间尺度,并且集中在局部细节 |
| 用soft attention灵活决定区域是否要被注意 | 使用hard erasing降低显著特征,导致表征能力下降 |
| 共享CNNs,具有多样化、轻量级的注意力模块 | 使用多个CNNs挖掘不同部分 |
每个模块的具体流程
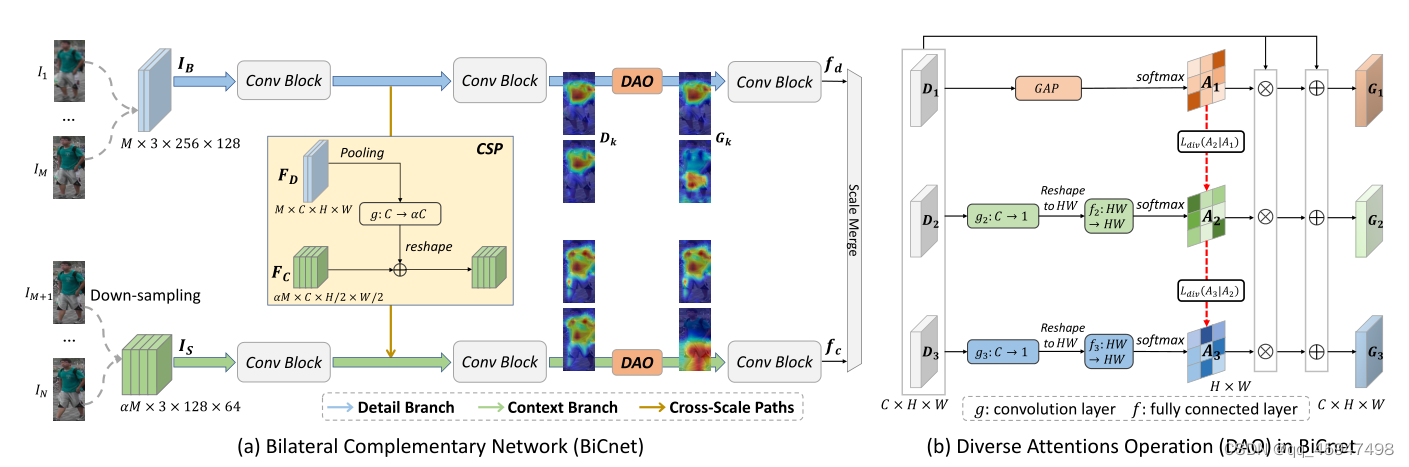
1、双分支结构
- ①将给定的视频片段 I = { I n } n = 1 N I=\left \{ I_{n}\right \} ^N_{n=1} I={In}n=1N划分为两个子部分 I B = { I n } n = 1 M , I S = { I n } n = M + 1 N I_B=\left \{ I_{n}\right \} ^M_{n=1},I_S=\left \{ I_{n}\right \} ^N_{n=M+1} IB={In}n=1M,IS={In}n=M+1N。其中 I B I_B IB为Big frames(就是原始输入帧的分辨率大小,例如256x128)。 I S I_S IS为small frames(原始帧大小的一半,为128x64)。M决定 α \alpha α的大小,且 α = I S I B \alpha=\frac{I_S}{I_B} α=IBIS。
-
I
S
和
I
B
{I_S}和{I_B}
IS和IB分别输入到细节分支和上下文分支获取特征向量
f d = 1 + α N ∑ k C N N D ( I k ) , I k ∈ { I n } n = 1 N 1 + α f c = 1 + α α N ∑ k C N N C ( I k ) , I k ∈ { I n } n = N 1 + α + 1 N \begin{array}{l} f_{d}=\frac{1+\alpha}{N} \sum_{k} \mathrm{CNN}_{\mathrm{D}}\left(I_{k}\right), I_{k} \in\left\{I_{n}\right\}_{n=1}^{\frac{N}{1+\alpha}} \\ f_{c}=\frac{1+\alpha}{\alpha N} \sum_{k} \mathrm{CNN}_{\mathrm{C}}\left(I_{k}\right), I_{k} \in\left\{I_{n}\right\}_{n=\frac{N}{1+\alpha}+1}^{N} \end{array} fd=N1+α∑kCNND(Ik),Ik∈{In}n=11+αNfc=αN1+α∑kCNNC(Ik),Ik∈{In}n=1+αN+1N
2、CSP模块
- F D ∈ R M × C × H × W 和 F C ∈ R α M × C × H / 2 × W / 2 F_D\in R^{M\times C\times H\times W}和F_C\in R^{\alpha M\times C\times H/2\times W/2} FD∈RM×C×H×W和FC∈RαM×C×H/2×W/2是上一阶段提取的特征。
- 为了使 F D 与 F C F_D与F_C FD与FC互补,将 F D 转换为 F D ‾ ∈ R α M × C × H / 2 × W / 2 F_D转换为\overline{F_{D}}\in R^{\alpha M\times C\times H/2\times W/2} FD转换为FD∈RαM×C×H/2×W/2。
- 流程公式化为:
F
D
‾
=
R
(
W
c
∗
P
(
F
D
)
)
\overline{F_{D}}=\mathcal{R}\left(W_{c} * \mathcal{P}\left(F_{D}\right)\right)
FD=R(Wc∗P(FD))
式中
R
:
r
e
s
h
a
p
e
操作,
P
:
最大池化操作,
∗
:卷积操作,
W
c
:
卷积操作的参数
\mathcal{R}:reshape操作,P:最大池化操作,*:卷积操作,W_{c}:卷积操作的参数
R:reshape操作,P:最大池化操作,∗:卷积操作,Wc:卷积操作的参数
3、DAO模块
-
将双分支结构的 F D 和 F C F_D和F_C FD和FC作为输入,并且对每个帧的特征图使用一个特定的注意力模块 ( F D ) k ∈ R C × H × W (F_D)_k\in R^{C\times H \times W} (FD)k∈RC×H×W
-
以 F D F_D FD为例,将 ( F D ) k 视为 D k (F_D)_k视为D_k (FD)k视为Dk
-
由于高级特征图中的,每个像素的强度与可鉴别能力成正比,因此通过通道级平均池化来压缩 D 1 D_1 D1,以此定位 D 1 D_1 D1的激活区域。并产生自注意力图
A k = softmax ( 1 C ∑ c = 1 C ( D k ) c ) , k = 1 A_{k}=\operatorname{softmax}\left(\frac{1}{C} \sum_{c=1}^{C}\left(D_{k}\right)_{c}\right), \quad k=1 Ak=softmax(C1c=1∑C(Dk)c),k=1 -
第二阶段,引入平行的注意力模型来学习、挖掘以及激活不同的区域。(对于激活我的想法是,他每个注意力模块只能关注到图像的一部分,也就是将关注到的部分激活,然后经过多个注意力模块的激活,能够提取出更全面的可鉴别的特征,也就是可以关注到每个区域的不同的细节部分(未证实))
-
对于给定的 D k ( k > 1 ) D_k(k>1) Dk(k>1),这个相应的注意力模型首先采用卷积层对通道维度进行压缩,重塑 R C × H × W —— > R H × W R^{C\times H\times W}——> R^{H\times W} RC×H×W——>RH×W。其次用全连接层嵌入全局的空间上下文特征。最后,产生自主注意力图 A k ∈ R H × W A_k\in R^{H\times W} Ak∈RH×W
-
由于空间注意力图是不一样的,所有引入了散度正则化,用于引导不同注意力模型激活不同区域。
L d i v ( A k ∣ A l ) = 1 − s i m ( A k , A l ) , k > l L_{div}(A_k|A_l)=1-sim(A_k,A_l) ,k>l Ldiv(Ak∣Al)=1−sim(Ak,Al),k>l
式中 A k , A l A_k,A_l Ak,Al为相邻特征图。 s i m ( A k , A l ) sim(A_k,A_l) sim(Ak,Al)计算 A k , A l A_k,A_l Ak,Al的相似度。 -
散度损失计算为
L = − 1 M − 1 ∑ k = 2 M ( 1 k − 1 ∑ l = 1 k − 1 L d i v ( A k ∣ A l ) ) L=\frac{-1}{M-1} \sum_{k=2}^{M}\left(\frac{1}{k-1} \sum_{l=1}^{k-1} L_{d i v}\left(A_{k} \mid A_{l}\right)\right) L=M−1−1k=2∑M(k−11l=1∑k−1Ldiv(Ak∣Al))
式中:L用于引导两个平行的注意力模型进行最优化。即当任意两个注意力图集中在一个行人区域是时,则L的值较高。因此用L进行优化可以驱动不同注意力模型集中在不同行人区域。 -
最后通过残差运算将不同注意力信息编码成输入特征图。
-
在整个双分支架构的最后,将更新后的特征图输入后续的卷积层中,生成嵌入互补的视觉线索的特征向量。
4、TKS
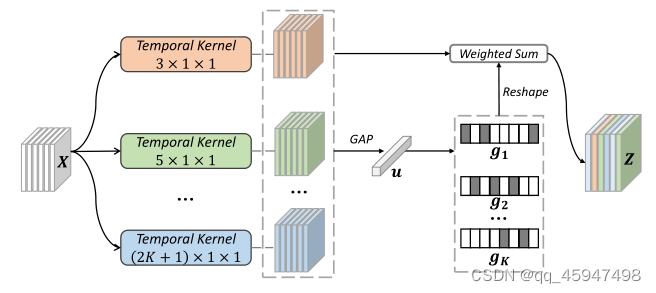
- 将连续特征图F的序列作为输入 F = { F t } t = 1 T F=\left \{ F_t \right \}^T_{t=1} F={Ft}t=1T。接着进行三重操作。
- 分区操作由于行人检测算法的缺陷,相邻帧可能没有合理排列,导致时间卷积在ReID中无效。使用分区策略减轻空间错位的问题。
①将每个帧特征图均匀划分到 h × w h\times w h×w的空间域
②用平均池化生成一个区域级的视频特征图 x ∈ R T × C × h × w x\in R^{T\times C\times h\times w} x∈RT×C×h×w - 选择操作
①将给定的特征x送人k个平行的时间卷积核路径 { F ( i ) : x − > Y ( i ) ∈ R T × C × h × w } \left \{ F^{(i)}:x->Y^{(i)}\in R^{T\times C\times h\times w} \right \} {F(i):x−>Y(i)∈RT×C×h×w}。其基本思想是,用来自所有时间路径的全局信息来确定每条路径的分配权重。
②全局特征: u = G A P T , h , w ( ∑ i = 1 K Y ( i ) ) u=G A P_{T, h, w}\left(\sum_{i=1}^{K} Y^{(i)}\right) u=GAPT,h,w(i=1∑KY(i))
③通道选择特征: g i = e x p ( W i u ) ∑ j = 1 k e x p ( W j u ) , i ∈ { 1 , . . . , k } g_i=\frac{exp(W_iu)}{ {\textstyle \sum_{j=1}^{k}exp}(W_ju) } ,i\in \left \{ 1,...,k\right \} gi=∑j=1kexp(Wju)exp(Wiu),i∈{1,...,k}
④聚集特征图: Z = ∑ i = 1 k R ( g i ) ⊙ Y ( i ) Z=\sum_{i=1}^{k} R(g_i)\odot Y^{(i)} Z=i=1∑kR(gi)⊙Y(i)
⑤值得指出的是,与按比例权重提供的粗融合相比,我们使用按权重进行融合(标号③的公式)。这个权重是根据输入视频,动态计算。不同尺度可能1有不同的支配时间尺度。 - 激活操作
最终的特征图 E = { E t } t = 1 T E=\left \{ E_t \right \}^T_{t=1} E={Et}t=1T
E t = u ( Z t ) + F t E_t=u(Z_t)+F_t Et=u(Zt)+Ft
式中:u为最近邻上采样。
框架总览
BiCnet的分支架构在ResNet50上。
DAO添加在stage3层中。高级特征图保留更多的语义信息。
分支之间结构核权重进行分享。(这是因为多分支结构由于多次引入参数会导致过拟合)
TKS由于可以自适应输入尺度,因此可以插入BiCnet的任意层(本文给出的位置是stage2~stage3层)
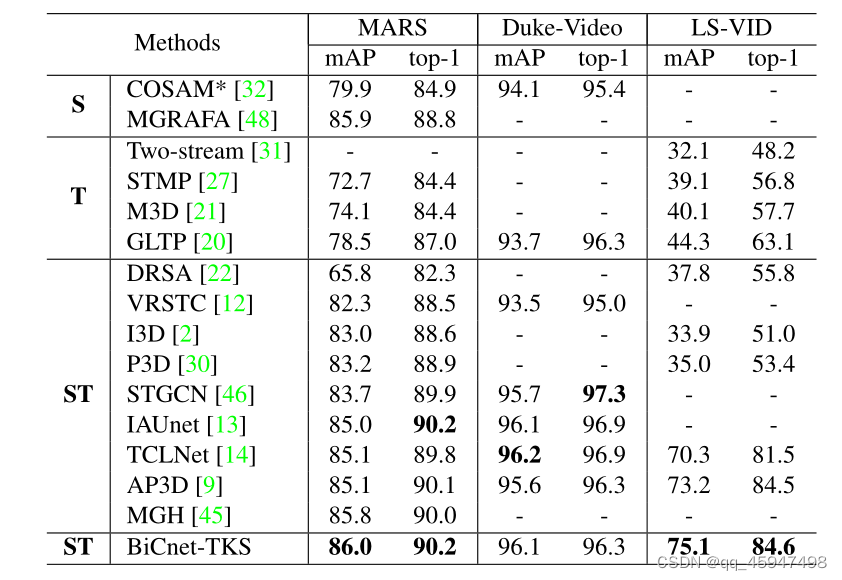
与其他模型的比较















 3252
3252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









