







本文主要是由中国科学院智能信息处理重点实验室发表的论文。在2019年发布的文章。
文章地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Hou_VRSTC_Occlusion-Free_Video_Person_Re-Identification_CVPR_2019_paper.pdf
摘要:
视频人物再识别(re-ID)在监控视频分析中占有重要地位。然而,在部分遮挡条件下,视频重识别性能严重退化。在本文中,我们提出了一种新的网络,称为时空补全网络(STCnet),以显式地处理部分遮挡问题。STCnet不同于以往大多数作品都是丢弃被遮挡的帧,STCnet可以恢复被遮挡部分的外观。首先,行人框架的空间结构可以用来从该框架的未遮挡身体部位预测遮挡的身体部位。另一方面,行人序列的时间模式为生成被遮挡部分的内容提供了重要线索。利用这些时空信息,STCnet可以恢复被遮挡部分的外观,并利用被遮挡部分进行更精确的视频再识别。将reID网络与STCnet相结合,提出了一种抗部分遮挡的视频重id框架(VRSTC)。
简介
1、主要解决帧遮挡的问题。
2、在部分帧遮挡的情况下,由于对所有帧的相同处理,视频特征通常会被损坏,导致严重的性能退化。
3、想法:
①基于注意力机制的方法,丢弃被遮挡的帧事不理想的。并且丢弃的帧会中断视频的实时信息。
②保留被丢弃帧的视觉部分能提供更好的线索。
4、设计
①提出Spatial-Temporal Completion network(STCnet)通过重新获取遮挡部分的外观处理遮挡部分的问题。
②根据行人帧的空间结构,未遮挡的帧可以预测遮挡的帧。
③由于行人序列的时间模式,来自相邻帧的信息有助于重新获取当前帧的外观信息。
④通过②③设计了spatial structure generator和 temporal attention generator
⑤spatial structure generator利用帧的空间信息预测遮挡帧的外观信息。
⑥ temporal attention generator利用视频的时间信息和temporal attention layer去细化空间生成的部分。
3、框架总览
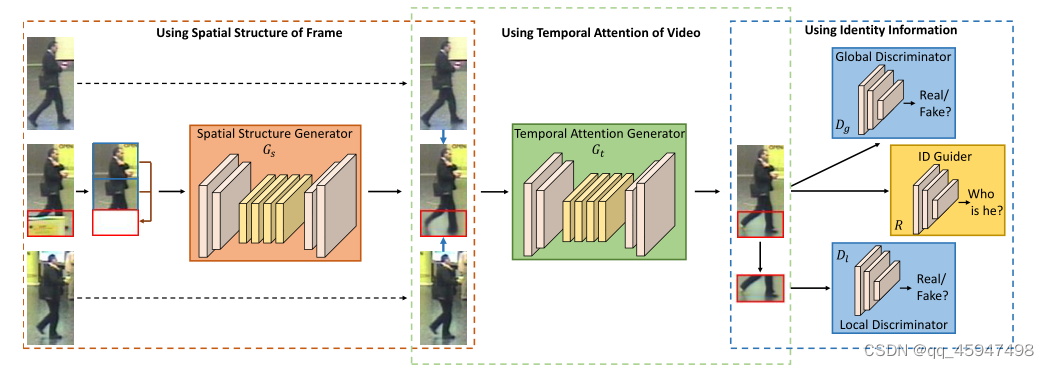
STCnet主要由spatial structure generator 、temporal attention generator、two discriminator(global discriminator和local discriminator)、 ID Guider subnetwork组成。
1、spatial structure generator :在当前帧的可视部分的条件下,对遮挡部分的内容做初始化的粗预测。
2、temporal attention generator:用来自相邻帧的信息,细化遮挡部分的内容。
3、global discriminator:对于整个帧对求全局一致性。
4、local discriminator:对于遮挡部分产生更多现实结果。
5、ID Guider subnetwork:维持补全之后的帧的ID标签。
1、整体流程
- 将输入视频帧划分为上中下三个区域。
- 提取每个区域的特征,用余弦相似度计算出每个区域的得分
- 将得分低于给定阈值的视为遮挡部分。
- 将遮挡部分用白色像素填充(白色像素的值为0)
- 用spatial structure generator 对遮挡区域进行粗预测。
其中spatial structure generator①是一个自编码结构,②encoder用于产生遮挡帧的潜在特征表示,③decoder产生遮挡部分的内容。 - temporal attention generator用相邻帧的信息细化遮挡部分的内容
①temporal attention layer用于建模空间生成器生成的帧与相邻帧之间的相关性。
②用一个encoder关注出现幻视的内容。另外2个分别针对先前帧和下一相邻且未遮挡的帧
③2个temporal attention layer附加在encoder的顶部,获取感兴趣的相邻帧特征。
④decoder获取最终输出。 - 用discriminator对上一输出的特征进行处理
①local discriminator:将整个遮挡部分作为输入,决定合成的内容是否真实。它有助于生成细节外观,激发补全部分的有效性。
②global discriminator:将整个帧作为输入,调整帧的全局结构,查看整个图像,评估它作为一个整体是否连贯。
③两个discriminator共同工作,确保产生的内容不仅有效而且前后一致。 - 提出3个损失函数对STCnet进行训练。
①针对spatial structure generator 和temporal attention generator引入reconstruction loss用以捕获整体结构
②adversarial loss分为global adversarial loss(反应整个帧的合理性)和local adversarial loss(反应生成内容的有效性)
③guider loss:维持补全帧的ID
2、spatial structure generator
- 由于帧的空间结构,遮挡部分的内容可用可视部分(未遮挡部分)进行预测,因此提出spatial structure generator对遮挡部分和可视部分之间的相关性进行建模。
- spatial structure generator设计成自编码的
- 其中encoder将一个帧的遮挡部分用白色像素填充吗。
- decoder生成特征表征并产生遮挡部分的内容
- 在encoder中采用膨胀卷积,有助于将较远的可视部分的信息传递到遮挡部分
- encoder由五个卷积层+堆叠4个膨胀卷积层(将分辨率降至初始大小的四分之一)
- decoder包含两个反卷积层用于存储帧的初始分别率。
3、temporal attention generator
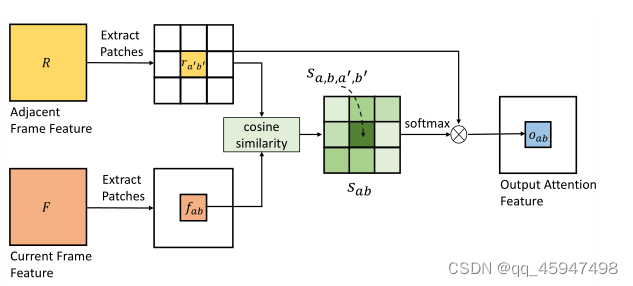
- 来自相邻帧的信息用于预测遮挡部分的内容,因此引入了一个temporal attention layer
- temporal attention layer 从相邻帧中学习在何处添加特征用于生成遮挡部分的内容。
- 建模空间生成器补全的帧(也作为当前帧)和相邻帧之间的相关性。
- ①从当前帧F和相邻帧R提取出的3*3的patches。
②在F和R之间作余弦相似度。
s a , b , a ′ , b ′ = ⟨ f a , b ∥ f a , b ∥ 2 , r a ′ , b ′ ∥ r a ′ , b ′ ∥ 2 ⟩ s_{a, b, a^{\prime}, b^{\prime}}=\left\langle\frac{f_{a, b}}{\left\|f_{a, b}\right\|_{2}}, \frac{r_{a^{\prime}, b^{\prime}}}{\left\|r_{a^{\prime}, b^{\prime}}\right\|_{2}}\right\rangle sa,b,a′,b′=⟨∥fa,b∥2fa,b,∥ra′,b′∥2ra′,b′⟩
③用softmax函数作归一化操作
s a , b , a ′ , b ′ ∗ = exp ( s a , b , a ′ , b ′ ) ∑ c ′ d ′ exp ( s a , b , c ′ , d ′ ) s_{a, b, a^{\prime}, b^{\prime}}^{*}=\frac{\exp \left(s_{a, b, a^{\prime}, b^{\prime}}\right)}{\sum_{c^{\prime} d^{\prime}} \exp \left(s_{a, b, c^{\prime}, d^{\prime}}\right)} sa,b,a′,b′∗=∑c′d′exp(sa,b,c′,d′)exp(sa,b,a′,b′)
④对于当前帧的patch,通过加权求和以及聚合相邻帧的所有patches来更新。权重由两个patches之间的相似度决定。
o a , b = ∑ a ′ b ′ s a , b , a ′ , b ′ ∗ r ( a ′ , b ′ ) o_{a,b}=\sum_{a'b'}^{} s^{*}_{a,b,a',b'}r(a',b') oa,b=a′b′∑sa,b,a′,b′∗r(a′,b′) - 用一个encoder关注出现幻视的内容。另外2个分别针对先前帧和下一相邻且未遮挡的帧
2个temporal attention layer附加在encoder的顶部,获取感兴趣的相邻帧特征。
decoder获取最终输出。
3、 Object Function
1、对于Spatial Generator
G
s
G_s
Gs和Temporal Generator
G
t
G_t
Gt引入reconstruction Loss:
L
r
,
L
1
L_r,L_1
Lr,L1是网络输出与初始帧之间的距离。
L
r
=
∥
x
−
x
^
1
∥
1
+
∥
x
−
x
^
2
∥
1
x
^
1
=
M
⊙
G
s
(
(
1
−
M
)
⊙
x
)
+
(
1
−
M
)
⊙
x
x
^
2
=
M
⊙
G
t
(
x
^
1
,
x
p
,
x
n
)
+
(
1
−
M
)
⊙
x
L_r=\left \| x-\hat{x}_1 \right \|_1+ \left \| x-\hat{x}_2 \right \|_1\\ \hat{x} _1=M\odot G_s((1-M)\odot x)+(1-M)\odot x\\ \hat{x} _2=M\odot G_t(\hat{x} _1,x_p,x_n)+(1-M)\odot x
Lr=∥x−x^1∥1+∥x−x^2∥1x^1=M⊙Gs((1−M)⊙x)+(1−M)⊙xx^2=M⊙Gt(x^1,xp,xn)+(1−M)⊙x
式中:
x
是
G
s
的输入(当前帧),
x
p
是先前帧,
x
n
是下一相邻帧,
x
^
1
和
x
^
2
分别是
G
s
和
G
t
的预测
x是G_s的输入(当前帧),x_p是先前帧,x_n是下一相邻帧,\hat{x} _1和\hat{x} _2分别是G_s和G_t的预测
x是Gs的输入(当前帧),xp是先前帧,xn是下一相邻帧,x^1和x^2分别是Gs和Gt的预测,M:二元掩码(用1表示被丢弃帧的区域)
2、对于global discriminator
D
g
D_g
Dg和local discriminator
D
l
D_l
Dl
定义global adversarial loss
L
a
1
L_{a1}
La1和local adversarial loss
L
a
2
L_{a2}
La2
L
a
1
=
min
G
s
,
G
t
max
D
g
E
x
∼
p
data
(
x
)
[
log
D
g
(
x
)
+
log
D
g
(
1
−
x
^
2
)
]
L
a
2
=
min
G
s
,
G
t
max
D
l
E
x
∼
p
data
(
x
)
[
log
D
l
(
M
⊙
x
)
+
log
D
l
(
1
−
M
⊙
x
^
2
)
]
\begin{array}{r} L_{a_{1}}=\min _{G_{s}, G_{t}} \max _{D_{g}} \mathbb{E}_{x \sim p_{\text {data }}(x)}\left[\log D_{g}(x)\right. \left.+\log D_{g}\left(1-\hat{x}_{2}\right)\right] \\ L_{a_{2}}=\min _{G_{s}, G_{t}} \max _{D_{l}} \mathbb{E}_{x \sim p_{\text {data }}(x)}\left[\log D_{l}(M \odot x)\right. \left.+\log D_{l}\left(1-M \odot \hat{x}_{2}\right)\right] \end{array}
La1=minGs,GtmaxDgEx∼pdata (x)[logDg(x)+logDg(1−x^2)]La2=minGs,GtmaxDlEx∼pdata (x)[logDl(M⊙x)+logDl(1−M⊙x^2)]
3、guider loss
L
c
L_c
Lc是一个简单的交叉熵损失
L
c
=
−
∑
k
−
1
k
q
k
l
o
g
R
(
x
^
2
)
k
L_c=-\sum_{k-1}^{k} q_klogR(\hat{x}_2 )_k
Lc=−k−1∑kqklogR(x^2)k
k:表示分类数量。q:表示输入帧的真实值(ground-true)
4、最终
L
=
L
r
+
λ
1
(
L
a
1
+
L
a
2
)
+
λ
2
L
c
L=L_r+\lambda_1(L_{a1}+L_{a2})+\lambda_2L_c
L=Lr+λ1(La1+La2)+λ2Lc
4、 Similarity Scoring
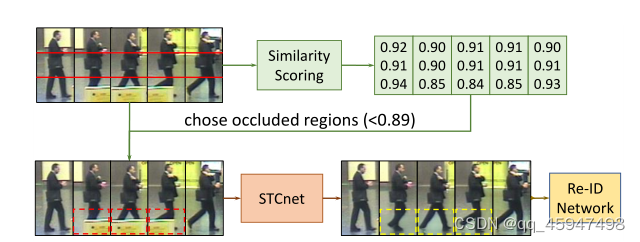
1、先前的方法构建一个子网络去预测每个帧的权重,但是对于权重没有直接监督,子网络难以自动地为遮挡帧分配低权重。
2、提出imilarity Scoring mechanism对帧的每个区域产生注意力得分。
3、观察到遮挡部分发生在一些连续的帧,并且遮挡有来自初始身体部不同的语义特征
4、在帧区域特征和视频区域特征之间用余弦相似度作为得分
①输入视频
I
=
{
I
t
}
t
=
1
τ
I=\left \{ I_t \right \}_{t=1}^{\tau }
I={It}t=1τ
②将帧垂直划分成3个固定区域
I
t
=
{
I
t
u
,
I
t
m
,
I
t
l
}
I_t=\left \{ I_{t}^{u},I_t^m,I_t^l \right \}
It={Itu,Itm,Itl}
③用CNN提取每个区域的特征
{
v
ˉ
k
∣
k
∈
{
u
,
m
,
l
}
}
\left \{ \bar{v} ^k|k\in \left \{ u,m,l \right \} \right \}
{vˉk∣k∈{u,m,l}}
④用平均池化获取特征
v
ˉ
k
=
1
T
∑
t
=
1
T
v
t
k
\bar{v} ^k=\frac{1}{T}\sum_{t=1}^{T}v_t^k
vˉk=T1∑t=1Tvtk
⑤用
v
t
k
=
⟨
v
t
k
∥
v
t
k
∥
2
,
v
ˉ
k
∥
v
ˉ
k
∥
2
⟩
v_t^k=\left \langle \frac{v_t^k}{\left \|v_t^k \right \| }_2 , \frac{\bar{v}^k }{\left \|\bar{v}^k \right \| }_2 \right \rangle
vtk=⟨∥vtk∥vtk2,∥vˉk∥vˉk2⟩计算每个帧区域的得分
⑥将得分低于阈值的视为存在遮挡
⑦通过STCnet补全遮挡帧,并作为新的数据训练重识别的任务。
5、 Re-ID Network
1、用ResNet50作为骨架网络
2、为了捕获时序上的依赖,引入non-local block

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









