







本文主要是由中国科学院智能信息处理重点实验室发表的论文。在2020年发布的文章。
文章地址:https://arxiv.org/pdf/2007.09357.pdf
源代码:https://github.com/blue-blue272/VideoReID-TCLNet
Abstract
提出了一种时间互补学习网络,提取连续视频帧的互补特征,用于视频人物的再识别。首先,我们介绍了一个时序显著性擦除模块,包括显著性擦除操作和一系列有序学习器。具体而言,对于视频的特定帧,显著性擦除操作通过擦除前一帧激活的部分来驱动特定学习器挖掘新的和互补的部分。
这样可以发现连续帧的不同视觉特征,最终形成目标身份的整体特征。
此外,设计了时间显著性增强(TSB)模块,在视频帧之间传播显著性信息,以增强显著性特征。它与TSE互补,有效缓解了TSE擦除操作造成的信息损失。
Introduce
1、想法
①现有的方法没有充分利用丰富的空时域线索。
②由于帧中行人的高度相似,并且现有的方法在同一帧上重复操作产生高度的冗余特征,难以区分行人。
2、模型设计
- 作者提出了TCLNet( Temporal Complementary LearningNetwork)网络
- TCLNet中提出了两个模块TSE(Temporal Saliency Erasing)和TSB(Temporal Saliency Boosting)
- 在TSE模块中包含显著性擦除学习和Learners。key idea:用Learners去学习互补的特征。
①Learner1对第一个视频帧提取显著特征。②显著性擦除学习擦除learner1关注的区域。③用learner2发现新的和互补的部分。④最终获取目标行人的完整特征。 - 然而随着TSE不断擦除输入视频序列的第二或子序列帧的显著部分,对大多数显著部分的表征能力越弱。
- TSB为了防止这种情况的,TSB加强了显著部分的表征能力。利用时间线索在视频帧之间传播显著性信息,使显著特征可以捕获视频中所有帧的线索,展现更强的表征力。
每个模块的具体流程
一、TSE模块
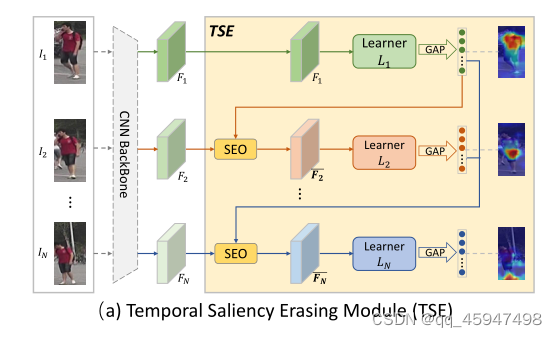
1、存在的问题:现有的方法在每个帧上做重复的操作,导致不同帧的高度冗余。
2解决:用TSE从连续视频帧中挖掘互补部分,形成目标行人的完整特征。
3、对每个帧的迭代做两个操作。
①用SEO(saliency erasing operation)擦除之前帧发现的部分
②通过learner发现新的部分,提取互补特征
4、具体操作
①将视频片段
I
n
I_{n}
In通过CNN骨干网络形成帧级特征
F
n
F_{n}
Fn并作为TSE的输入;
②用learner1对
F
1
F_1
F1进行学习,通过GAP提取出显著特征
f
1
∈
R
D
1
f_1 \in R^{D_1}
f1∈RD1
f
1
=
G
A
P
(
L
1
(
F
1
)
)
f_1=GAP(L_1(F_1))
f1=GAP(L1(F1))
③在
f
1
f_1
f1的显著部分的引导下,用SEO擦除
I
2
I_2
I2的特征向量
F
2
F_2
F2,产生擦除特征
F
ˉ
2
\bar{F}_2
Fˉ2
④使用新的learner_n对
F
ˉ
n
\bar{F}_n
Fˉn进行学习,挖掘新的部分和和获取特征向量
f
n
f_n
fn
F
ˉ
n
=
SEO
(
F
n
;
f
1
,
…
,
f
n
−
1
)
,
f
n
=
GAP
(
L
n
(
F
n
‾
)
)
(
1
<
n
≤
N
)
\bar{F}_n =\operatorname{SEO}\left(F_{n} ; f_{1}, \ldots, f_{n-1}\right), \quad f_{n}=\operatorname{GAP}\left(L_{n}\left(\overline{F_{n}}\right)\right)(1<n \leq N)
Fˉn=SEO(Fn;f1,…,fn−1),fn=GAP(Ln(Fn))(1<n≤N)
⑤SEO和learner学习操作在输入片段的N个连续帧中反复操作,最终获取目标行人的完整特征。
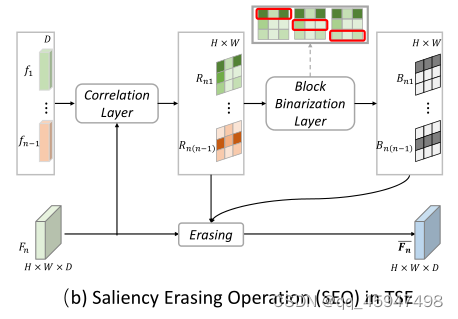
5、SEO中的collelation layer
①对于待擦除的
F
2
F_2
F2,首先通过correlation layer 获取
F
1
F_1
F1的特征向量(
f
k
,
k
<
n
,
f_k,k<n,
fk,k<n,)与
F
2
F_2
F2之间的关联图。
②在
F
n
F_n
Fn的每个向量空间位置(i,j)的特征向量视为一个D维的局部描述符
F
n
(
i
,
j
)
F_n^{(i,j)}
Fn(i,j)(这一步就相当于将
F
n
F_n
Fn重塑为
R
D
R^D
RD)
③然后在关联层用点积相似性计算
f
k
与
F
n
f_k与F_n
fk与Fn的所有局部描述符之间的语义相关性(其实就是两个矩阵相乘)
相关图:
R
n
k
(
i
,
j
)
=
(
F
n
(
i
,
j
)
)
T
(
w
T
f
k
)
(
1
≤
i
≤
H
,
1
≤
j
≤
W
,
1
≤
k
≤
n
−
1
)
相关图:R_{n k}^{(i, j)}=\left(F_{n}^{(i, j)}\right)^{T}\left(w^{T} f_{k}\right) \quad(1 \leq i \leq H, 1 \leq j \leq W, 1 \leq k \leq n-1)
相关图:Rnk(i,j)=(Fn(i,j))T(wTfk)(1≤i≤H,1≤j≤W,1≤k≤n−1)
④由于
f
k
f_k
fk的激活部分在
R
n
k
R_{nk}
Rnk具有高相关值,因此,可以定位上一帧特征向量
f
k
f_k
fk的激活部分在
F
n
F_n
Fn中的位置。
6、SEO中的Block Binarization layer
①由于以前的方法方法使用相关图用于生成二元掩码,以此识别待擦除区域,就是在擦除不连续特征区域时引入一个阈值。但是由于卷积特征单元在空间上是相关的,所以对不连续特征单元进行操作时,被擦除单元信息仍然会传递到下一层。
②解决办法:提出用Block Binarization layer去产生二元掩码,使其能够擦除连续区域的特征图。
③用滑动块的方法在相关图中搜索最突出的连续区域。
对于每一个相关图都可以获取多个候选块(如图,Block Binarization layer上方同一个相关图有三个不同位置的候选块)
候选块中的值就是块中所有项之和。
候选块:
N
p
o
s
=
(
⌊
H
−
h
e
S
h
⌋
+
1
)
×
(
⌊
W
−
w
e
S
w
⌋
+
1
)
候选块:N_{pos}=\left ( \left \lfloor \frac{H-h_e}{S_h} \right \rfloor +1\right ) \times \left ( \left \lfloor \frac{W-w_e}{S_w} \right \rfloor +1\right )
候选块:Npos=(⌊ShH−he⌋+1)×(⌊SwW−we⌋+1)
④最终选出值最大的候选块作为擦除块(如图,Block Binarization layer上方同一个相关图中第一个候选框也就是红色框中的两个项颜色最深,所以这个候选框的相关值应该时最大的)
⑤然后将相关图中待擦除的候选块的值设为0,相关图的其余部分设为1,生成二元掩码
B
n
k
∈
R
H
×
W
B_{nk}\in R^{H\times W}
Bnk∈RH×W
⑥最后将
B
n
k
B_{nk}
Bnk合并成为融合掩码
B
n
B_n
Bn
B
n
=
B
n
1
⊙
B
n
2
⊙
…
⊙
B
n
(
n
−
1
)
B_n=B_{n1}\odot B_{n2}\odot… \odot B_{n(n-1)}
Bn=Bn1⊙Bn2⊙…⊙Bn(n−1)
7、SEO中的Erasing Operation
①引入门控机制擦除特征图Fn
②用softmax层融合相关图,使用
B
n
B_n
Bn擦除所选块得到门控图
G
n
=
s
o
f
t
m
a
x
(
R
n
1
⊙
R
n
2
⊙
…
⊙
R
n
(
n
−
1
)
)
⊙
B
n
,
G
n
∈
R
H
×
W
G_n=softmax\left ( R_{n1}\odot R_{n2}\odot… \odot R_{n(n-1)} \right ) \odot B_{n} ,G_n\in R^{H\times W}
Gn=softmax(Rn1⊙Rn2⊙…⊙Rn(n−1))⊙Bn,Gn∈RH×W
二、TSB模块

1、提出的原因:SEO模块会导致显著部分的信息丢失,而TSB在中间帧级特征图中传递最显著的特征,用这种方式显著特征能够完全捕获视频线索。
2、在TSB中提出了一个查询内存注意力机制(query-memory attention)
①将每个帧的特征图作为查询向量
Q
∈
R
H
×
W
×
D
Q\in R^{H\times W\times D}
Q∈RH×W×D
②内存M包含视频剩余S帧(在TSB中,第一个帧作为Q,其余为M)的特征映射集合,用于增强查询的表征力。
3、具体步骤
①将Q压缩为一个描述查询统计信息的描述符。压缩的过程是通过GAP来生成通道级的统计量
q
∈
R
D
q\in R^D
q∈RD
②重塑M,
M
∈
R
S
×
H
×
W
×
D
——
>
M
∈
R
∣
M
∣
×
D
(
∣
M
∣
=
S
×
H
×
W
)
M\in R^{S \times H\times W\times D}——>M\in R^{\left | M \right | \times D}(\left | M \right |=S\times H\times W)
M∈RS×H×W×D——>M∈R∣M∣×D(∣M∣=S×H×W)视作D维的局部描述符。
③查询向量q通过余弦相似度与每个内存的描述符进行匹配,得到概率图:
概率图:
A
i
=
e
x
p
(
τ
q
ˉ
T
M
ˉ
i
)
∑
j
=
1
∣
M
∣
e
x
p
(
τ
q
ˉ
T
M
ˉ
j
)
概率图:A_i=\frac{exp(\tau\bar{q}^T\bar{M}_i )}{ {\textstyle \sum_{j=1}^{\left |M \right | }exp(\tau\bar{q}^T\bar{M}_j )} }
概率图:Ai=∑j=1∣M∣exp(τqˉTMˉj)exp(τqˉTMˉi)
式中:
M
i
∈
R
D
,
M
M_i\in R^D,M
Mi∈RD,M的第i个局部表示符,
q
ˉ
,
M
ˉ
\bar{q},\bar{M}
qˉ,Mˉ是归一化后的。
τ
\tau
τ时间超参数
④
O
=
M
T
A
O=M^TA
O=MTA与查询相似的M描述符,呈现出更高的权重,可避免低质量帧的损坏。
⑤最后,以残差学习的策略将权重描述符O传递到Q
E
=
B
N
(
O
)
+
Q
E=BN(O)+Q
E=BN(O)+Q

三、总体框架
1、ResNet-50作为骨架网络。
2、ImageNet用于预训练。
3、TSE在ResNet-50的stage4层可以减少计算的复杂度。TSE中的N个learners在前两个残差块中共享参数,在最后一块用自己的参数。
4、TSB插在任意层
5、大致流程
①用插入TSB的骨架网络对T个视频帧进行提取。提取出的帧可表示为
F
=
F
1
,
F
2
…
,
F
T
F={F_1,F_2…,F_T}
F=F1,F2…,FT
②将F划分为L个部分,则每个部分的特征表示为
{
C
k
}
k
=
1
L
\left \{ C_k \right \}_{k=1}^{L}
{Ck}k=1L
③将每个部分的特征向量(也就是帧)送入TSE中提取互补特征。
④最终通过时间平均池化聚集每个部分所提取的特征,并产生视频特征。















 1470
1470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









