






模型量化
对量化的了解
模型量化是一种将浮点计算转成低比特定点计算的技术,可以有效的降低模型计算强度、参数大小和内存消耗,但往往带来巨大的精度损失。尤其是在极低比特(<4bit)、二值网络(1bit)、甚至将梯度进行量化时,带来的精度挑战更大。
一、量化综述
模型量化是由模型、量化两个词组成。我们要准确理解模型量化,要看这两个词分别是什么意思。
在计算机视觉、深度学习的语境下,模型特指卷积神经网络,用于提取图像/视频视觉特征。
量化是指将信号的连续取值近似为有限多个离散值的过程。可理解成一种信息压缩的方法。在计算机系统上考虑这个概念,一般用“低比特”来表示。也有人称量化为“定点化”,但是严格来讲所表示的范围是缩小的。定点化特指scale为2的幂次的线性量化,是一种更加实用的量化方法。
卷积神经网络具有很好的精度,甚至在一些任务上比如人脸识别、图像分类,已经超越了人类精度。但其缺点也比较明显,具有较大的参数量,计算量,以及内存占用。而模型量化可以缓解现有卷积神经网络参数量大、计算量大、内存占用多等问题,具有为神经网络压缩参数、提升速度、降低内存占用等“潜在”优势。
二、压缩参数
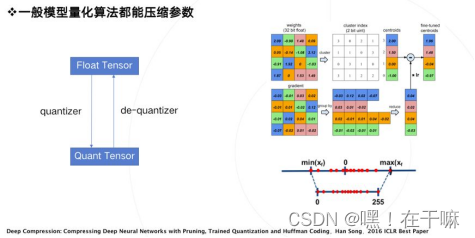
模型量化在最初的定义里是为了压缩模型参数,比如韩松在ICLR2016上获得best paper的论文,首次提出了参数量化方法。其使用k-mean聚类,让相近的数值聚类到同一个聚类中心,复用同一个数值,从而达到用更少的数值表示更多的数,这是量化操作的一种方案。反过来,从量化数变到原始数的过程,称之为反量化,反量化操作完之后,模型就可以按照原来的方式进行正常的计算。
三、提升速度

量化是否一定能加速计算?回答是否定的,许多量化算法都无法带来实质性加速。引入一个概念:理论计算峰值。在高性能计算领域,这概念一般被定义为:单位时钟周期内能完成的计算个数 乘上 芯片频率。
什么样的量化方法可以带来潜在、可落地的速度提升呢?我们总结需要满足两个条件:
量化数值的计算在部署硬件上的峰值性能更高 。
2、量化算法引入的额外计算(overhead)少 。
已知提速概率较大的量化方法主要有如下三类,
1、二值化,其可以用简单的位运算来同时计算大量的数。对比从nvdia gpu到x86平台,1bit计算分别有5到128倍的理论性能提升。且其只会引入一个额外的量化操作,该操作可以享受到SIMD(单指令多数据流)的加速收益。
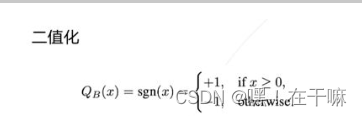
2、线性量化,又可细分为非对称,对称和ristretto几种。在nvdia gpu,x86和arm平台上,均支持8bit的计算,效率提升从1倍到16倍不等,其中tensor core甚至支持4bit计算,这也是非常有潜力的方向。由于线性量化引入的额外量化/反量化计算都是标准的向量操作,也可以使用SIMD进行加速,带来的额外计算耗时不大。
3、对数量化,一个比较特殊的量化方法。可以想象一下,两个同底的幂指数进行相乘,那么等价于其指数相加,降低了计算强度。同时加法也被转变为索引计算。但没有看到有在三大平台上实现对数量化的加速库,可能其实现的加速效果不明显。只有一些专用芯片上使用了对数量化。
总结一下,要使用量化技术来提升模型运行速度,需要满足两个条件:
1、选择适合部署的量化方案。
2、在部署平台上使用经过深度优化的量化计算库
线性量化:
数学公式r=Round(S(q-z))
q 原始的float32数值;Z float32数值的偏移量(Zero Point);
S 表示float32的缩放因子(Scale) r表示的是量化后的一个整数值
根据Z是否为0分为两类对称量化和非对称量化
注意:对于单边分布如(2.5, 3.5),需要将其范围放宽至(0, 3.5)再量化,在极端的单边分布的情况下会损失精度。
即若min大于0,就将范围缩放到(0,max)。
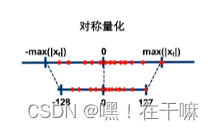
对称量化
scale(缩放因子)计算公式如下,对8bits量化来说N_levels为128:
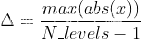
对称量化比较简单,它限制零点值为0,量化公式如下: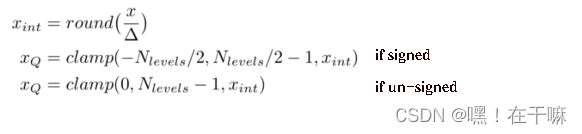
反量化公式:
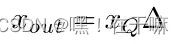
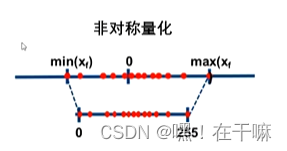
非对称量化
假设输入的浮点数范围为(X_min, X_max),量化后的范围为(0, N_levels - 1)
对8bits量化来说N_levels为256,scale和零点的计算公式如下:

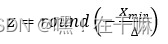
上述z要取一个round,zeropoint基于定点域平移, zeropoint是一个定点域的数,需要四舍五入取整。
得到了scale和零点后,对于任意的输入x,量化计算过程为:
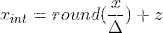


对应的反量化计算公式为:
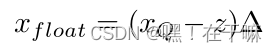
注意:对于单边分布如(2.5, 3.5),需要将其范围放宽至(0, 3.5)再量化,在极端的单边分布的情况下会损失精度。
即若min大于0,就将范围缩放到(0,max)。
TensorRt -Int8量化
训练后量化,对称量化,量化公式
FP32 T=FP32_scale(sf)8-bit(t)+FP32_bias(b)
英伟达实验表明,bias去掉后进度影响不是很大
T=sft
简单的max-max映射,针对均匀分布否则会有较大的精度损失
S=|max|/127
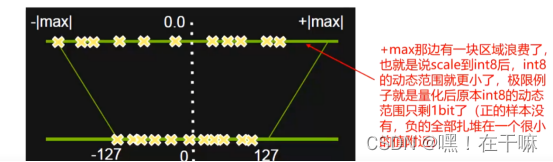
非饱和截取的问题是当数据分布极不均匀的时候,有很多动态范围是被浪费的,而饱和截取就是弥补这个问题。当数据分布不均匀的适合,如图左边比右边多,那么就把原始信息在映射之前截断一部分,然后构成对称且分布良好的截断信息,再把这个信息映射到int8上去,就不会有动态范围资源被浪费了。
如图所有小于-|T|映射到了-127 大于|T|映射到了127
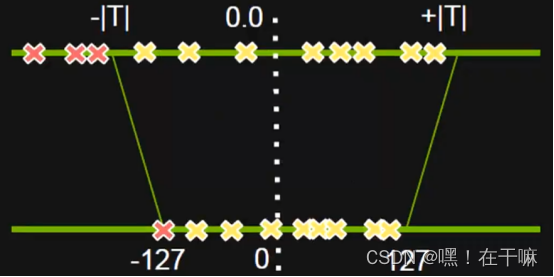
最好的T应使得量化后信息损失最少
NVIDA选择的是KL-divergence(相对熵),它可以表述两个分布的差异程度,这里指的是量化前后两个分布的差异程度,差异最小就是最好的了,因此问题转换为求相对熵的最小值。
相对熵的计算机公式(p,q是两个分布)
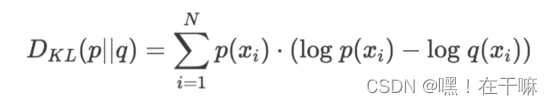

宏观处理流程如下,
首先准备一个校准数据集,然后对每一层:
收集激活值的直方图
基于不同的阀址产生不同的量化分布
然后计算每个分布与原分布的相对熵,然后选择熵最少的一个,也就是跟原分布最像的一个,此时阀值就选出来啦,对应的scale值也就出来了。
最关键:校准算法部分

算法解释:
1、首先不断地截断参考样本P,长度从128开始到2048,为什么从128开始呢?因为截断的长度为128的话,那么我们直接一一对应就好了,完全不用衰减因子了
2、将截断区外的值全部求和;
3、截断区外的值加到截断样本P的最后一个值之上(截断区之外的值为什么要加到截断区内最后一个值呢?个人理解就是有两个原因,其一是求P的概率分布时,需要总的P总值,其二将截断区之外的加到截断P的最后,这样是尽可能地将截断后的信息给加进来。)
4、求得样本P的概率分布;
5、创建样本Q,其元素的值为截断样本P的int8量化值;
6、将Q样本长度拓展到 i ,使得和原样本P具有相同长度;
7、求得Q的概率分布;
8、然后就求P、Q的KL散度值
9、上面就是一个循环,不断地构造P和Q,并计算相对熵,然后找到最小(截断长度为m)的相对熵,此时表示Q能极好地拟合P分布了。
10、而阀值就等于(m + 0.5)*一个bin的长度。
当前bins数目和要量化为bins数目不整除时,按照比例处理(参考腾讯ncnn深度学习框架)

四、降低内存
模型量化还有一个潜在的好处是降低运行时内存占用,这个特性无论是在移动端还是云端都是具有现实意义的。如果降低内存占用,可以得到如下好处:
1、降低访存量,存在提升速度的可能 。
2、在同样硬件环境下,同时处理更多视频或者视频路数 。
3、训练更大的模型。
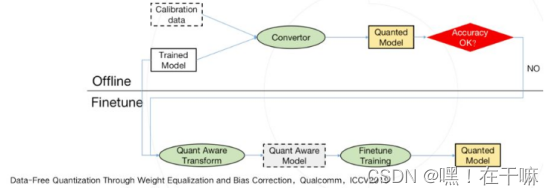
生产一个量化模型的有以下几种方法,借鉴了ICCV2019上一篇data-free量化论文的定义。
L1:直接将一个浮点参数直接转化成量化数,一般会带来很大的精度损失,但使用上非常简单。
L2:基于数据校准的方案,很多芯片都会提供这样的功能,比如tensorRT,高通,寒武纪等。它需要转模型的时候提供一些真实的计算数据。
L3:基于训练finetune的方案,有很多论文都是使用这种方法,它的好处是可以带来更大的精度提升,缺点是需要修改训练代码,实施周期比较长。
一种实用的pipeline流程,一般会优先使用不进行finetune的offline方法,也就是离线方案。当离线方案精度损失过于严重,我们才会进行基于finetune的方法,来做进一步的抢救。
五、量化模型的落地
模型量化算法落地的几个问题,核心当然是精度问题。主要存在几个Gap:
1、可落地的线性量化方案无法很好的刻画一些分布,比如高斯分布
2、比特数越低,精度损失就越大,实用性就越差
3、任务越难,精度损失越大,比如识别任务,就比分类任务要难非常多
4、小模型会比大模型更难量化
5、某些特定结构,如depthwise,对量化精度十分不友好
6、常见的对部署友好的方法比如merge BN,全量化,都会给精度带来更大的挑战
软硬件支持不好也是一个阻碍:不同的硬件支持的低比特指令是不一样的,同样训练得到的低比特模型,无法直接部署在所有硬件上。除了硬件之外,不同软件库实现的量化方案和细节也不一样,量化细节里包括量化位置、是否支持perchannel、是否混合精度等等。即使硬件支持了量化,但你会发现不是所有硬件可以在低比特上提供更好的速度提升, 造成这个状况的主要原因有多个,一方面是指令集峰值提升可能本身就并不多,而要引入较多的额外计算,另一方面也取决于软件工程师优化指令的水平,同时由于网络结构灵活多样,不一定能在不同网络结构上达到同样好的加速比,需要优化足够多的的corner case才可以解决。
六、现代深度学习框架中的量化
最完善的工具之一是TensorFlow Lite的模型优化工具包。它包含了尽可能缩小模型的方法。
You can find the documentation and an introductory article below.
https://www.tensorflow.org/lite/performance/model_optimization
https://medium.com/tensorflow/introducing-the-model-optimization-toolkit-for-tensorflow-254aca1ba0a3
PyTorch还支持多种量化工作流程。尽管目前已将其标记为实验性功能,但功能齐全。 (但是,请注意API会一直更改,直到它处于实验状态。)
https://pytorch.org/blog/introduction-to-quantization-on-pytorch/
pyroch中的量化
官方教程(英文):
https://pytorch.org/docs/stable/quantization.html
pytorch.org
官方教程(中文):
https://pytorch.apachecn.org/docs/1.4/88.html
量化流程
以最常用的Post Training (Static) Quantization为例:
1.准备模型:准备一个训练收敛了的浮点模型,用QuantStub和DeQuantstub模块指定需要进行量化的位置;
2. 模块融合:将一些相邻模块进行融合以提高计算效率,比如conv+relu或者conv+batch normalization+relu,最常提到的BN融合指的是conv+bn通过计算公式将bn的参数融入到weight中,并生成一个bias;
3. 确定量化方案:这一步需要指定量化的后端(qnnpack/fbgemm/None),量化的方法(per-layer/per-channel,对称/非对称),activation校准的策略(最大最小/移动平均/L2Norm);
activation校准:利用torch.quantization.prepare()
利用torch.quantization.prepare() 插入将在校准期间观察激活张量的模块,然后将校准数据集灌入模型,利用校准策略得到每层activation的scale和zero_point并存储;
5. 模型转换:使用 torch.quantization.convert()函数对整个模型进行量化的转换。 这其中包括:它量化权重,计算并存储要在每个激活张量中使用的scale和zero_point,替换关键运算符的量化实现;


















 2116
2116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











