






YOLOV8多模态(可见光+红外光,基于Ultralytics官方代码实现)
回复1:
统一回复为啥没有打印读取红外文件的pbar
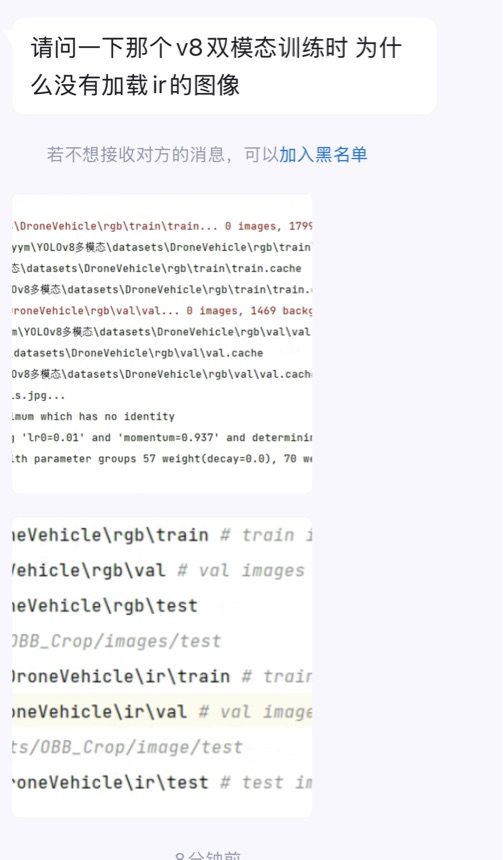
另外红外图像的yaml路径其实并没用到,因为我发现v8代码在判断label的坐标不合法时候,会删除掉数据,所以很有会导致可见光图像被删除掉了,导致两个数据个数不同,我是直接使用的replace替换可见光的images路径。留下ir路径只是为了方便以后的拓展。
回复2:
AttributeError: ‘NoneType’ object has no attribute ‘replace’
f1
将
f1=im.replace(‘images’,‘image’)
改为
f1=self.im_files[i].replace(‘images’,‘image’)
同时训练可见光和红外图片,需要改动网络的结构,对每层的特征进行融合。同时需要对图片质量进行评价,给出自适应的融合权重。
在nn/moudle/block中融合模块中可修改融合策略。具体细节请阅读代码,主要修改有数据增强、读取部分、模型前向传播等。
各位读者麻烦给个star或者fork,求求了。
YOLOV8多模态目标检测
前言:环境配置要求
torch 2.3.1
torchvision 0.18.1
Python 3.8.19
tensorrt 8.5.3.1
1. 数据集DroneVehicle数据集(可见光+热红外)
DroneVehicle 数据集由无人机采集的 56,878 张图像组成,其中一半是 RGB 图像,其余是红外图像。我们为这 5 个类别制作了丰富的注释,其中包含定向边界框。其中,汽车在 RGB 图像中有 389,779 个注释,在红外图像中有 428,086 个注释,卡车在 RGB 图像中有 22,123 个注释,在红外图像中有 25,960 个注释,公共汽车在 RGB 图像中有 15,333 个注释,在红外图像中有 16,590 个注释,厢式车在 RGB 图像中有 11,935 个注释,在红外图像中有 12,708 个注释,货车在 RGB 图像中有 13,400 个注释, 以及红外图像中的 17,173 个注释。
在 DroneVehicle 中,为了在图像边界处对对象进行注释,我们在每张图像的顶部、底部、左侧和右侧设置了一个宽度为 100 像素的白色边框,因此下载的图像比例为 840 x 712。在训练我们的检测网络时,我们可以执行预处理以去除周围的白色边框并将图像比例更改为 640 x 512。

2. 数据集文件格式(labeles: YOLO格式)
datasets
├── image
│ ├── test
│ ├── train
│ └── val
├── images
│ ├── test
│ ├── train
│ └── val
└── labels
├── test
├── train
└── val
images 保存的是可见光图片
image 保存的是热红外图片
labels 公用一个标签(一般来说使用红外图片标签)
3. 权重文件下载
目标检测权重| 模型 | 尺寸 (像素) | mAPval 50-95 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (ms) | 参数 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
| 模型 | 尺寸 (像素) | mAPtest 50 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (ms) | 参数 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n-obb | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
| YOLOv8s-obb | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
| YOLOv8m-obb | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
| YOLOv8l-obb | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
| YOLOv8x-obb | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
4. 配置模型yaml文件和数据集yaml文件
分别在yaml文件夹和data文件下进行模型和数据集文件的配置
5. 训练
python train.py
6. 测试
python test.py
7. 打印模型信息
python info.py
8. obb
推理:detect/obbDetect.py
热图绘制: detect/hbbHeapmap.py
onnx推理: detect/obbOnnxdetect.py
9. hbb
推理:detect/hbbDetect.py
热图绘制: detect/hbbHeapmap.py
10. onnx
导出onnx格式文件: export/exportOnnx.py
判断onnx格式和pth格式的输出是否相同: export/campareOnnxWithPth.py
删除导出engine文件的meta信息:export/delEngineMeta.py
11. 绘制框
绘制hbb真实框: plot/plotGt.py
绘制obb真实框 plot/plotObb.py
绘制文件下所有图片的hbb真实框 plot/plotAllGt.py
12. int8量化
从训练集随机挑选测试集作为校准集并进行int8量化: int8Calib/int8Claib.py
删除int8量化的中间文件:int8Calib/delData.sh
多次生成校准集量化: int8Calib/testClaib.sh
13. 检测结果
挑选最好的检测结果:findBestDetect/bestMatch.py
比较原来模型和新的模型的检测结果: findBestDetect/campareOriginWithNew.py
14. 数据处理
裁剪droneVechile数据集的白边: dataProcess/cropData.py
droneVechile数据集从Dota格式转OBB格式:dataProcess/dotaToOBB.py
















 4099
4099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











