






目录
7.2 K折交叉验证选择超参数,可以在浅层网络调,然后在深层网络上用嘛?或者在随机抽取得少量数据调整,然后在全部数据上用嘛?
1. 访问和探索数据集
竞赛数据分为训练集和测试集。 每条记录都包括房屋的属性值和属性,如街道类型、施工年份、屋顶类型、地下室状况等。 这些特征由各种数据类型组成。 例如,建筑年份由整数表示,屋顶类型由离散类别表示,其他特征由浮点数表示。 这就是现实让事情变得复杂的地方:例如,一些数据完全丢失了,缺失值被简单地标记为“NA”。 每套房子的价格只出现在训练集中(毕竟这是一场比赛)。 我们将希望划分训练集以创建验证集,但是在将预测结果上传到Kaggle之后, 我们只能在官方测试集中评估我们的模型。
import pandas as pd
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
train_data = pd.read_csv('./train.csv')
test_data = pd.read_csv('./test.csv')初步探索数据
print(train_data.shape) # (1460, 81)
print(test_data.shape) # (1459, 80)train_data.head()
test_data.head()
很明显可以发现,id这个特征对于我们虽然有识别作用,但是不携带任何有用的信息,可以进行去除,这里可以看到我们把训练数据的最后一行的label也通过切片去除了
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))2. 数据预处理

2.1 标准化数据
标准化也叫标准差标准化,经过处理的数据符合标准正态分布。为什么要进行这种处理?
首先训练一个神经网络提取特征,然后用提取的特征进行分类和位置回归,提取的特征决定了分类和位置回归的准确性,提取的特征要能够代表每个类别的特点,因此神经网络更关注的是类别之间的差异性,并不是看图像的绝对值,例如图像很亮,图像很暗之类的,为了突出差异,所有输入的图像都要减去平均值,平均值是整个数据的平均亮度,形状不一样的图,在某个位置上比其他图亮一些,另外一个位置则比其他要暗一些,这个就是它的特征,这些差异传入神经网络,帮助网络来判断。对于除以方差:数据的不同的特征都可以看作一张图片的一个个像素,这些像素有亮有暗,有些地方变化小,变化大的权重比较大,对网络的影响比较大,但是我们在做特征提取的时候,更希望网络关注的是整个图像的变化,而不是某个局部变化大的地方来影响它的输出。如果除以方差,它的效果是所有像素的取值范围。
根据求导的链式法则,w的局部梯度是X,当X全为正时,由反向传播传下来的梯度乘以X后不会改变方向,要么为正数要么为负数,也就是说w权重的更新在一次更新迭代计算中要么同时减小,要么同时增大。
''' 若无法获得测试数据,则可根据训练数据计算均值和标准差 '''
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
''' 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0 '''
all_features[numeric_features] = all_features[numeric_features].fillna(0)2.2 离散值处理(独热编码)
pandas - 数据离散化之 get_dummies,可以帮我们实现文本数据的独热编码
'''Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征'''
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape ''' (2919, 331) ''' 你可以看到,此转换会将特征的总数量从79个增加到331个。 最后,通过values属性,我们可以 从pandas格式中提取NumPy格式,并将其转换为张量表示用于训练。
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values,
dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values,
dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1),
dtype=torch.float32)3. 训练
首先,我们训练一个带有损失平方的线性模型。 显然线性模型很难让我们在竞赛中获胜,但线性模型提供了一种健全性检查, 以查看数据中是否存在有意义的信息。 如果我们在这里不能做得比随机猜测更好,那么我们很可能存在数据处理错误。 如果一切顺利,线性模型将作为基线(baseline)模型, 让我们直观地知道最好的模型有超出简单的模型多少。
这里net_1是老师给的简单的单层线性模型,调参测试发现在k折交叉验证可能能保持很好,但是总体训练损失函数不稳定,分数也很低,net_2是我自己简单进行了两层隐藏层,采用ReLU激活函数。
loss = nn.MSELoss()
in_features = train_features.shape[1]
def net_1():
net = nn.Sequential(nn.Linear(in_features,1))
return net
def net_2():
net = nn.Sequential(nn.Linear(in_features,128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 1))
return net
这里我们为了取对数的时候数据能够稳定,使用压缩区间的torch.clamp对它最大值最小值进行压缩
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()与前面的部分不同,我们的训练函数将借助Adam优化器 (我们将在后面章节更详细地描述它)。 Adam优化器的主要吸引力在于它对初始学习率不那么敏感
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls4. K折交叉验证
你可能还记得,我们在第四章讨论模型选择的部分中介绍了K折交叉验证, 它有助于模型选择和超参数调整。 我们首先需要定义一个函数,在K折交叉验证过程中返回第i折的数据。 具体地说,它选择第i个切片作为验证数据(slice切片函数),其余部分作为训练数据。 注意,这并不是处理数据的最有效方法,如果我们的数据集大得多,会有其他解决办法。
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid再写入一个函数,在K折交叉验证中训练K次后,返回训练和验证误差的平均值。(对K求平均)。这里我加入一个Net参数,用于写入不同的神经网络。
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size, Net):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = Net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k5. 模型选择
李沐老师选择了一组未调优的超参数,并将其留给读者来改进模型。 找到一组调优的超参数可能需要时间,这取决于一个人优化了多少变量。 有了足够大的数据集和合理设置的超参数,K折交叉验证往往对多次测试具有相当的稳定性。 然而,如果我们尝试了不合理的超参数,我们可能会发现验证效果不再代表真正的误差。
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')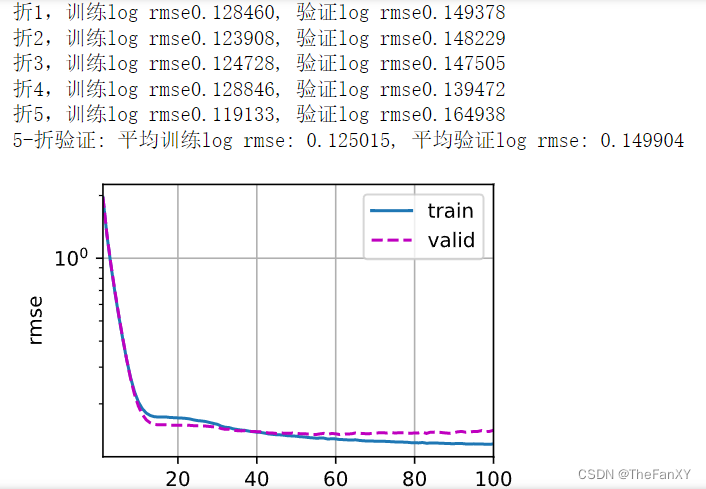
这里是我自己优化的三层网络训练调参后的结果,可以观察到,对于纯线性层是可以设置较高的学习率,我猜测可能因为纯线性模型的导数几乎是一个固定值,大些的学习率可以更快找到这个值,但是也不是越大越好。但是对于设置了隐藏层的MLP多层感知机网络,就需要设置低一些的学习率,来使得weight的更新趋于平稳。
k, num_epochs, lr, weight_decay, batch_size = 12, 300, 0.001, 0.001, 128
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size, net_2)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')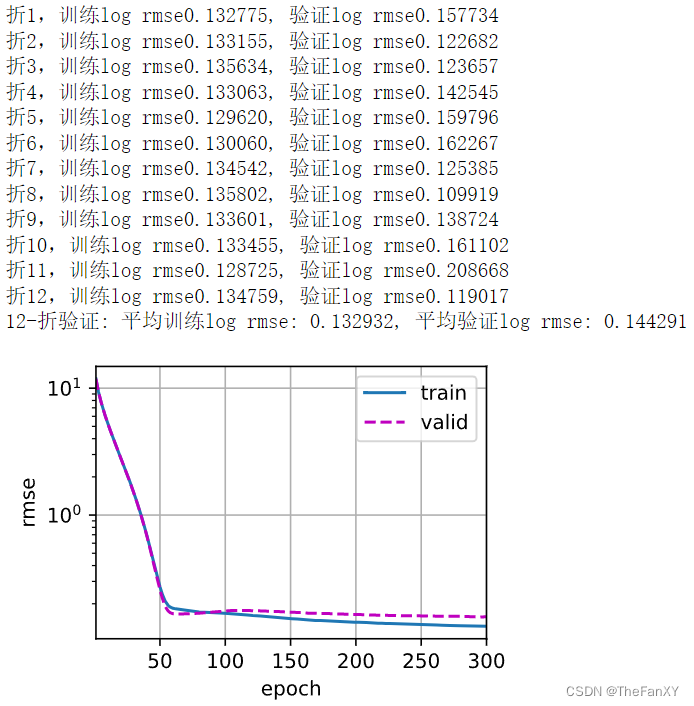
请注意,有时一组超参数的训练误差可能非常低,但K折交叉验证的误差要高得多, 这表明模型过拟合了。 在整个训练过程中,你将希望监控训练误差和验证误差这两个数字。 较少的过拟合可能表明现有数据可以支撑一个更强大的模型, 较大的过拟合可能意味着我们可以通过正则化技术来获益。
6. 提交你的预测
既然我们知道应该选择什么样的超参数, 我们不妨使用所有数据对其进行训练 (而不是仅使用交叉验证中使用的1−1 / K的数据)。 然后我们通过这种方式获得的模型可以应用于测试集。 将预测保存在CSV文件中可以简化将结果上传到Kaggle的过程。
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size, Net):
net = Net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)如果测试集上的预测与K倍交叉验证过程中的预测相似, 那就是时候把它们上传到Kaggle了。 下面的代码将生成一个名为submission.csv的文件
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size, net_2)
这里也是靠这个简单的模型,和不到10分钟的调参拿到了2000的名次,相信大家根据参考去设计更好的网络和调参,可以取得更好的效果。其次这次可以发现李沐老师说的一些调参策略取得一些效果——先想办法扩大网络的能力去过拟合,然后逐步去削弱,然后对于这个比较简单的模型,感觉weightdecay的效果并不是特别好,日后再去详细去了解正则化的调参。

7. QA环节
7.1 减小特征维度能用label encoding嘛?
不要在意特征维度的问题,维度这个多一点少一点其实都是没有关系的
7.2 K折交叉验证选择超参数,可以在浅层网络调,然后在深层网络上用嘛?或者在随机抽取得少量数据调整,然后在全部数据上用嘛?
第一个是肯定不可以的,因为网络也是一种超参数,你换了网络训练的模型就大大改变,不是参数能够代替的。第二个是一个比较好的策略,因为太大的数据训练训练时间很长,可以使用这个策略先找个一个大概的参数区间,然后在整个数据集去细微调整。
7.3 为了避免overfit是调参好,还是不调参好?还是有什么别的经验?
正常比赛肯定是开始只能接触到公榜的数据的,比如你拿到了6个月的数据,你可以用前五个月去预测最后一个月,你调参,找到一个真的你觉得非常好的超参数。我的建议是去调整这个超参数的值,往上往下去微调,测试模型的变化,如果你发现微小的变化对模型非常敏感,那么只能说你很有可能到了一个非常不均匀的平面,只是靠运气摸到了一个预测好的精准参数,泛化能力是达不到的。实际应用数据是一直在变的,只有竞赛需要进行调参的细致调整。
7.4 MLP有值得仔细调参的价值嘛?
还是值得去调参的,MLP取决于应用,像是一些新出的组合的网络,也可以应用不同情况,所以我认为如果贴合应用还是值得去调参的。















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









