







吴恩达机器学习 第一周
0 总结
参考视频: B站吴恩达机器学习
学习时间:2022.8.29 ~ 2022.9.4
- 掌握了机器学习的定义
- 掌握监督学习、非监督学习的定义和区别
- 以房价预测问题为例,掌握单变量线性回归的模型构建方法
- 掌握了梯度下降获取最优值的方法
- 将梯度下降运用到线性回归中
- 复习线性代数内容,学会矩阵的基本算法
1 引言
1-1 机器学习例子
- 谷歌、必应的精确搜索
- Facebook 或苹果的图片分类程序
- 电子邮件垃圾邮件筛选器
- 数据库挖掘(把数据转化为知识)
- 手写识别
- …
1-2 什么是机器学习
第一个机器学习的定义来源于Arthur Samuel
机器学习为,在进行特定编程的情况下,给予计算机学习能力的领域。
Arthur Samuel并非下棋高手,却可以使程序经过学习后,可以成为西洋棋高手。
Tom Mitchell机器学习的定义
机器学习是,一个好的学习问题定义如下,他说,一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值P,当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。
以下围棋为例:经验e 就是程序上万次的自我练习的经验; 任务 t 就是下棋;性能度量值 p ,就是它在与一些新的对手比赛时,赢得比赛的概率。
1-3 监督学习 Supervised Learning
房价预测问题

图中,横坐标为房子的面积(单位:
f
e
e
t
2
feet^2
feet2),纵坐标为价格(单位:千美元)。基于这组数据,预测:750平方英尺的房子可以卖多少钱。
若拟合一条直线:(图中粉色线条)卖$150,000。
若拟合二次方程:(图中蓝色曲线)卖$200,000。
乳腺癌(良性,恶性)

图中,横轴表示肿瘤的大小,纵轴只有两个取值:0表示良性,1表示恶性。预测:给出一肿瘤大小,预测是良性还是恶性。
在这个例子中,只有一个特征:即肿瘤的大小,但是在实际情况中,大部分具有多个特征:肿瘤尺寸、患者年龄、肿块密度…

图中,有两个特征,横坐标为肿瘤大小,纵坐标为患者年龄,圈为良性,x为恶性,这些映射在二维平面的点的良性或者恶性,可以称为标签。以后会讲一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征。
监督学习定义
监督学习基本思想是:
我们数据集中的每个样本都有相应的“正确答案”(标签)。再根据这些样本作出预测,就像房子和肿瘤的例子中做的那样。
回归问题
即通过回归来推出一个连续的输出,比如房价问题。
分类问题
目标是推出一组离散的结果,比如乳腺癌问题。
1-4 无监督学习 Unsupervised Learning
无监督学习与监督学习
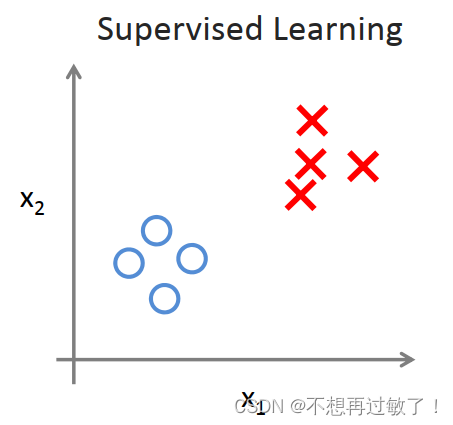
左图为监督学习:这个数据集中每条数据都已经标明是阴性或阳性,即是良性或恶性肿瘤。所以,对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案,是良性或恶性了。
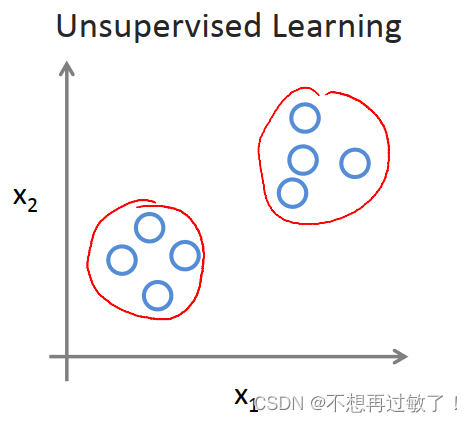
右图为无监督学习:没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。
针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。
对于无监督学习:我们只有一堆数据,不知道数据里面有什么,不知道谁是什么类型,不知道人们有哪些不同的类型,这些类型又是什么。但是你能自动地聚类哪些个体到各个类。
谷歌新闻
谷歌新闻做的就是搜索非常多的新闻事件,自动地把它们聚类到一起。所以,这些新闻事件全是同一主题的,所以显示到一起。
社交网络分析
已知你朋友的信息,比如你经常发 email 的,或是你 Facebook 的朋友、谷歌+圈子的朋友,我们能否自动地给出朋友的分组呢?即每组里的人们彼此都熟识,认识组里的所有人?
市场分割
许多公司有大型的数据库,存储消费者信息。所以,你能检索这些顾客数据集,自动地发现市场分类,并自动地把顾客划分到不同的细分市场中,你才能自动并更有效地销售或不同的细分市场一起进行销售。
音频处理问题
两个人同时说话,编写算法区分出两个音频资源。一行代码完成:
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
2 单变量线性回归 Linear Regression with One Variable
2-1 模型描述
以预测房价为例:我们需要使用一个数据集,数据集包含某市的住房价格,据此画出数据集如下图所示。现在需要预测:1250
f
e
e
t
2
feet^2
feet2的房子可以卖多少钱?
因此现在需要做的就是构建一个模型,比如一条直线,大概能以220,000美元卖出。

这是一个回归问题。另一个常见的监督学习方式是分类问题:比如肿瘤是良性还是恶性。
假设训练集(Training Set)如表所示:

| 变量 | 含义 |
|---|---|
| m m m | 训练集中实例的数量 |
| x x x | 特征/输入变量(这个例子中是房子的大小) |
| y y y | 目标变量/输出变量(这个例子中是房子的价格) |
| ( x , y ) (x,y) (x,y) | 训练集中的实例 |
| ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)} ) (x(i),y(i)) | 第 i 个观察实例 |
| h h h | 学习算法的解决方案或函数也称为假设(hypothesis) |

h是一个从x到y的函数映射。
对于房价预测问题,如何表达h?
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_\theta(x)=\theta_0+\theta_1x
hθ(x)=θ0+θ1x因为只有一个输入变量,所以叫:单变量线性回归问题。
2-2 代价函数 cost function
已知:m=47即训练集中有47个数据
目的:寻找最合适的
θ
0
\theta_0
θ0和
θ
1
\theta_1
θ1使该直线能够最好地拟合数据

定义目标函数:
min
θ
0
,
θ
1
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
\min_{\theta_0,\theta_1}\frac{1}{2m}\sum^{m}_{i=1}(h_\theta(x^{i})-y^{i})^{2}
θ0,θ1min2m1i=1∑m(hθ(xi)−yi)2
m:样本数量
h θ ( x i ) h_\theta(x^{i}) hθ(xi):输入为 x i x^{i} xi时得到的输出
y i y^{i} yi:第 i i i个样本的实际输出
公式含义:求使得 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 \frac{1}{2m}\sum^{m}_{i=1}(h_\theta(x^{i})-y^{i})^{2} 2m1∑i=1m(hθ(xi)−yi)2最小的 θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1
改写上述公式:
代价函数(cost function):
J
(
θ
0
,
θ
1
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
J(\theta_0,\theta_1)=\frac{1}{2m}\sum^{m}_{i=1}(h_\theta(x^{i})-y^{i})^{2}
J(θ0,θ1)=2m1i=1∑m(hθ(xi)−yi)2
这个代价函数也被称为平方误差函数(sqare err function),目标:
min
θ
0
,
θ
1
J
(
θ
0
,
θ
1
)
\min_{\theta_0,\theta_1}J(\theta_0,\theta_1)
θ0,θ1minJ(θ0,θ1)
总结:
对于房价预测问题,建立模型,其中假设函数是关于
x
x
x的函数:
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_\theta(x)=\theta_0+\theta_1x
hθ(x)=θ0+θ1x代价函数是关于
θ
0
,
θ
1
\theta_0,\theta_1
θ0,θ1的函数:
J
(
θ
0
,
θ
1
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
J(\theta_0,\theta_1)=\frac{1}{2m}\sum^{m}_{i=1}(h_\theta(x^{i})-y^{i})^{2}
J(θ0,θ1)=2m1i=1∑m(hθ(xi)−yi)2优化目标是寻求使得代价函数最小的
θ
0
,
θ
1
\theta_0,\theta_1
θ0,θ1:
min
θ
0
,
θ
1
J
(
θ
0
,
θ
1
)
\min_{\theta_0,\theta_1}J(\theta_0,\theta_1)
θ0,θ1minJ(θ0,θ1)
2-3 梯度下降 Gradient Desent

:=表示赋值操作。a:=b表示不管a原先存储的数值,直接把b的值赋给a。
=表示判断。a=b表示判断出a=b。
α \alpha α表示学习率, α \alpha α越大表示沿下降方向走的步子越大。
需要注意的是:
θ
0
,
θ
1
\theta_0,\theta_1
θ0,θ1应当同步更新!
2-4 线性回归的梯度下降


3 线性代数基础
矩阵
如图为4x2的矩阵,即4行2列,矩阵的维度即行数x列数。
A
i
,
j
A_{i,j}
Ai,j即指第
i
i
i行,第
j
j
j列的元素。

向量
向量是一种特殊的矩阵, 讲义中的向量一般都是列向量,如:
y
=
[
y
1
y
2
y
3
y
4
]
y= \left[\begin{matrix} y_1\\ y_2 \\ y_3 \\ y_4 \\ \end{matrix} \right]
y=⎣
⎡y1y2y3y4⎦
⎤
为四维列向量(4× 1)。一般使用1索引向量。
矩阵乘法
满足乘法结合律:
(
A
×
B
)
×
C
=
A
×
(
B
×
C
)
(A\times{B})\times{C}=A\times({B}\times{C})
(A×B)×C=A×(B×C)
不满足乘法交换律:
A
×
B
≠
B
×
A
A\times{B}\neq{B}\times{A}
A×B=B×A
单位矩阵

矩阵的逆
只有方阵有逆矩阵,满足:
A
A
−
1
=
A
−
1
A
=
I
AA^{-1}=A^{-1}A=I
AA−1=A−1A=I
矩阵的转置 Transpose















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









