






仅从代码入手,不讲DDP原理,网上看了一堆都讲的挺全面的了(自己还看不懂)
项目背景:pytorch1.8.1、python3.7、cuda11.1、Ubuntu 18.04、至少两张N卡
从单卡训练到DDP训练增加代码:
1.定义local_rank:卡的编号
import torch.distributed as dist
parse.add_argument('--local_rank', default=-1, type=int, help='node rank for distributed training')2.设置卡间通讯方式
device = torch.device("cuda", args.local_rank)
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)3.定义sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
train_dataloaders = DataLoader(train_dataset, batch_size=args.batch_size, num_workers=args.num_workers, sampler=train_sampler, pin_memory=True)
val_dataloaders = DataLoader(val_dataset, batch_size=1, num_workers=args.num_workers, sampler=val_sampler)
test_dataloaders = DataLoader(test_dataset, batch_size=1, num_workers=args.num_workers, sampler=test_sampler)4.在每个epoch开始时,设置set_epoch(主要用作随机采样),dt_size整除2是因为我只有两张卡ORZ
train_dataloader.sampler.set_epoch(epoch)
val_dataloader.sampler.set_epoch(epoch)
dt_size = len(train_dataloader.dataset) // 25.包装模型
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])6.启动训练
nohup python -u -m torch.distributed.launch --nproc_per_node=2 --master_port=2345 main.py > ./test.log &
其中nproc_per_node为你的卡数量,master_port是可以随机设置的端口号
OK,大功告成!
如果要保存与读取模型:
# 保存模型
if args.local_rank == 0:
state = {'net': model.module.state_dict(), 'optimizer': optimizer.state_dict()}
torch.save(state, your_path)
# 读取模型
checkpoint = torch.load(your_path, map_location='cuda:{}'.format(args.local_rank))
model.load_state_dict(checkpoint['net'])
optimizer.load_state_dict(checkpoint['optimizer'])
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])顺便记录一下自己的疑问:
双卡训练的时候,每张卡都会输出loss、acc等参数,如下图:

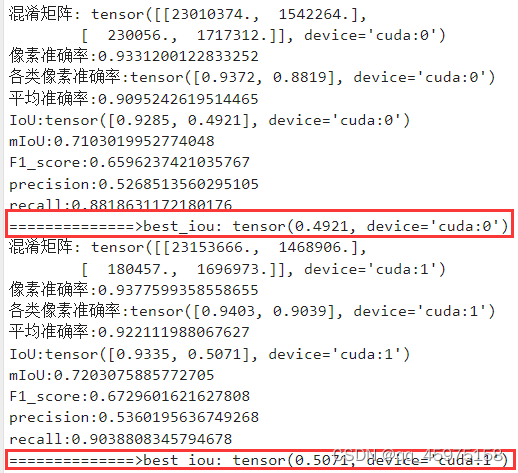
可是两张卡的验证iou都不相同,自己测试后发现卡1的精度总会比卡0的高一点;
那疑问就有:
1.是验证集采样不同导致的精度差异,还是此刻的两卡梯度并未同步?
2.在保存模型的时候使用 args.local_rank == 0 和 args.local_rank == 1 保存是否模型相同?
3.如果是梯度并未同步,有无显式同步方式?
坐等高手XD















 5395
5395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









