






二编:更新了多分类任务下的AnyLoss代码
第一次写学习心得,如果有什么漏错,请大家海涵!
论文地址:AnyLoss: Transforming Classification Metrics into Loss Functions (arxiv.org)
代码地址:GitHub - doheonhan/anyloss
提出目的:由于传统机器学习中的混淆矩阵是离散的,很难生成可微的损失函数进行优化。因此,本文中,提出了一种通用方法将任何基于混淆矩阵的指标转换为可用于优化过程的损失函数 AnyLoss。
优势:直接针对混淆矩阵进行优化、处理不平衡数据集时表现出色
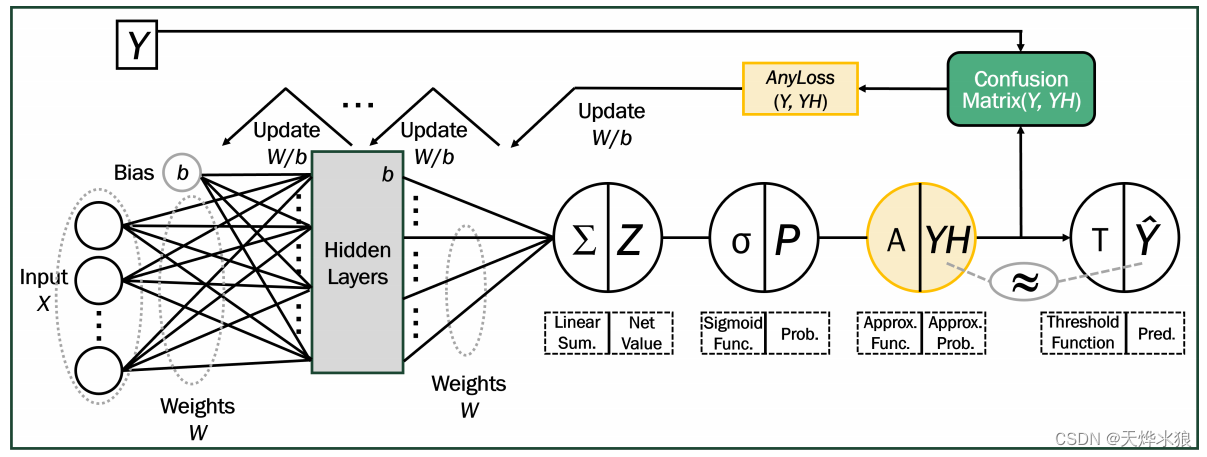
核心组件:Approx函数,将经过Sigmoid得到的类概率标签进一步缩放,使其更接近0或1。
近似函数的作用,简单来说就是“对于给定的任意pi,使其充分收敛到0或1,但不能达到0或1”。近似函数的数学形式如下,放大倍数L为正实数,pi为经过sigmoid函数后给定的类别概率。函数A(pi)在运算时需要满足两个条件,这两个条件决定了放大倍数L的取值。

第一个条件:缩放。近似函数应该能够使 A(pi) 更接近0或1。此过程放大了类概率pi,以便近似概率A(pi)可以被视为实际标签。如果类概率 pi 大于 0.5,则 A(pi) 应该大于 pi 并接近于 1。例如,如果 pi 为 0.7,近似函数应该生成大于 0.7 且接近于 1 的 A(pi),这样我们就可以将其假设为实际标签“1”。相反,如果 pi 为 0.2,近似函数应该生成小于 0.2 且接近于 0 的 A(pi),这样我们就可以将其假设为实际标签“0”。
第二个条件:达不到 0或1。即A(pi) ∈(0, 1)。如果 A(pi) 值变为 0 或 1,当然可以保证更准确地计算评估指标分数,因为它们与实际标签相同。然而,这会导致一个严重的问题,即“不再更新”。因为 A(pi) 的偏导数的形式如图所示:
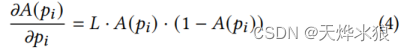
该导数同时包含 A(pi) 和 (1-A(pi)) 项,因此任何 A(pi) = 0 或 1 的情况都会使偏导数为 0。
上述两个条件决定了超参数L的范围,关于L的取值讨论在论文中有详细介绍,此处不在赘述。文中推荐值L=73。
以下是自己编写的Pytorch版代码,
import torch
import torch.nn as nn
"""
y_true:torch.tensor,真实标签
y_pred:torch.tensor,经过Sigmoid函数的类概率
"""
class BinaryAnyLoss(nn.Module):
def __init__(self, L=73):
super().__init__()
self.L = L
def forward(self, y_true, y_pred):
y_pred = 1 / (1 + torch.exp(-self.L * (y_pred - 0.5)))
TP = torch.sum(y_true * y_pred)
TN = torch.sum((y_true == 0) * (1.0 - y_pred))
FP = torch.sum((y_true == 0) * y_pred)
FN = torch.sum((y_true == 1) * (1.0 - y_pred))
return TP, TN, FP, FN
class AnyLoss(nn.Module):
def __init__(self, L=73):
super().__init__()
self.L = L
def forward(self, y_true, y_pred):
nclass = y_pred.shape[1]
y_true = nn.functional.one_hot(y_true.long(), nclass)
y_true = torch.transpose(y_true, 1, len(y_true.shape) - 1)
assert y_true.shape == y_pred.shape, 'predict & target shape do not match'
bAnyLoss = BinaryAnyLoss(L=self.L)
total_loss = 0.
for i in range(nclass):
TP, TN, FP, FN = bAnyLoss(y_true[:, i], y_pred[:, i])
total_loss += FP
total_loss += FN
total_loss /= nclass
return total_loss
# 分类任务
anyloss = AnyLoss()
label = torch.randint(0, 10, [5])
pred = torch.softmax(torch.randn([5, 10]), dim=1)
loss = anyloss(label, pred)
print(loss)
# 分割任务
label = torch.randint(0, 10, [1, 512, 512])
pred = torch.softmax(torch.randn([1, 10, 512, 512]), dim=1)
loss = anyloss(label, pred)
print(loss) 之后便可以通过TP、TN、FP、FN等构建自己需要的函数。例如。需要注意的是,作为损失函数出现时应该:















 2878
2878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









