






LightViT: 全局与局部的交互与强化
论文: https://arxiv.org/abs/2207.05557
代码: https://github.com/hunto/LightViT
一、前言和贡献
由于缺乏归纳偏置,ViT通常被认为没有卷积神经网络(CNNs)更轻量化。因此,最近的工作将卷积作为一个即插即用的模块,并将它们嵌入到各种ViT中。在本文中,我们认为卷积核执行信息聚合来连接所有token;然而,如果这种显式聚合能够以更均匀的方式发挥作用,那么对于轻量级的ViT,它们实际上是不必要的。受此启发,我们将LightViT作为一个新的轻量级ViT提出,以在无卷积的transformer块上实现更好的精度-效率平衡。我们在ViT的自注意(self-attention)和前馈网络(FFN)中引入了一种全局但有效的聚合方案,其中引入了额外的可学习token来捕获全局依赖关系;并对token嵌入施加二维通道和空间注意。
贡献
本文对于Transformer块中两个关键组件做出新设计,即自注意力和前馈网络(FFN):
对于自注意力,我们利用了局部窗口注意力。特别的是,我们提出引入可学习的全局token,通过建模局部token的全局依赖性来聚合其信息,然后将这些全局依赖关系广播到每个局部token中。通过这种方式,每个图像token可以提供更多信息,因为它同时受益于局部和全局特征。
对于FFN,作为Transformer块中唯一的非线性部分,它通过建模特征模式和隐式捕捉空间相关性在特征提取中发挥重要作用。然而,由于在轻量级模型中通道尺寸较小,其表示能力将受到限制。因此,我们提出了一个二维注意力模块来显式地聚合空间维度和通道维度之间的全局依赖关系,从而提高其能力。
二、方法

针对Self-Attention,在local attention计算得到的局部依赖的基础上,额外引入了global token与image token的交互。这一过程现将image token中的信息聚合,并更新global token。之后反过来再讲global token中的信息传播到image token上得到全局依赖。将全局与局部依赖整合更新image token。最终模块输出为更新后的image和global token。作者们将这一过程基于global token的更新过程称之为information squeeze-and-expand scheme,也就是信息压缩和扩张的形式,与seblock的形式本质上颇为类似。
针对FFN,在原来的点变换的基础上级联了一个双维度的注意力,从空间和通道两个维度上级进行了特征的强化。
在模型整体结构上

三、Conclusion
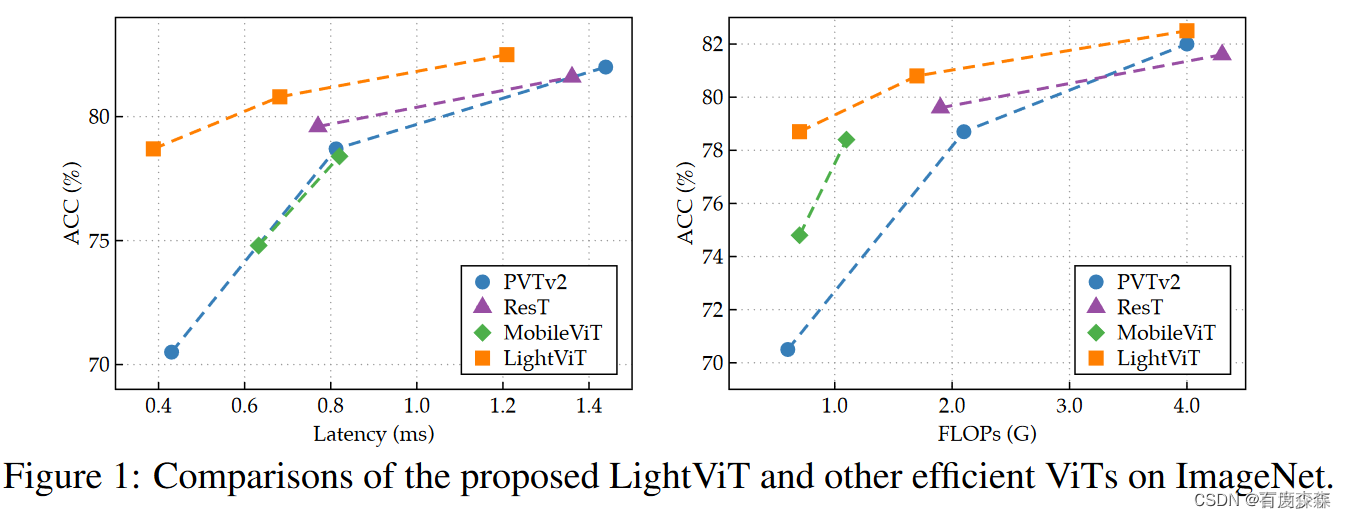
本文提出了一种轻量ViT。虽然最近的工作旨在将卷积和transformer结合在ViT中,但本文在无卷积的纯ViT块上寻求更好的性能-效率的权衡,提出在自注意和前馈网络上进行更好的信息聚合,在ImageNet分类和目标检测上获得了更好的性能。
参考1: https://blog.csdn.net/P_LarT/article/details/126301936
参考2: https://zhuanlan.zhihu.com/p/543656901















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









