







一 MobileNet系列
1.12017MobileNet
论文地址:
项目地址:tensorflow框架
Zehaos/MobileNet: MobileNet build with Tensorflow (github.com)
主要思想:
提出深度可分离卷积depthwise separable convolutions ,比一般卷积要减少计算量。
MobileNet 使用 3 × 3 深度可分离卷积,它使用的计算量比标准卷积少 8 到 9 倍,而准确度仅略有下降。

1.2.MobileNetV2
论文地址:[1801.04381] MobileNetV2: Inverted Residuals and Linear Bottlenecks (arxiv.org)
项目地址:pytorch框架
Randl/MobileNetV2-pytorch: Impementation of MobileNetV2 in pytorch (github.com)
主要思想:
提出反残差块inverted residual block和线性瓶颈 Linear Bottlenecks
当n=2,3等低维度的时候,ReLU会造成大量的信息丢失,而n=15,16 等高维度的时候只会有少量信息丢失。所以把最后一个ReLU6换成了Linear 变换。即linear-bottlenecks

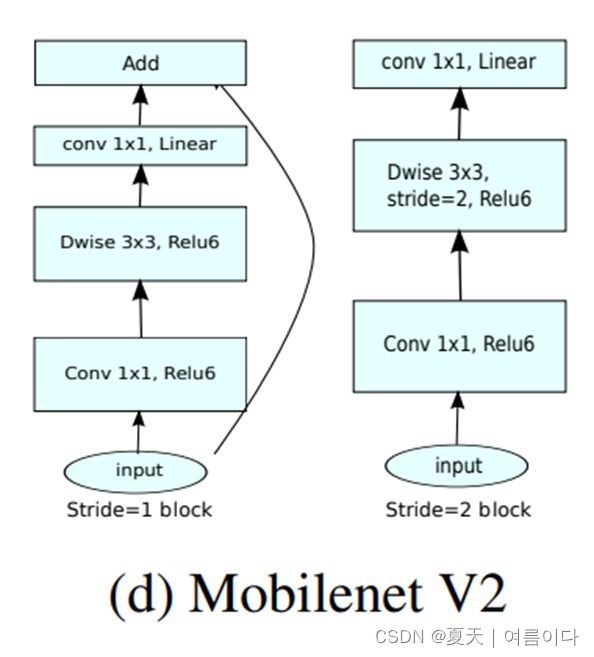
MobileNetV2引入了两种结构Linear Bottleneck和 Inverted Residual Blocks,既能够去除高维度feature的冗余信息,又能够去除低维度feature的信息坍塌。
1.3.MobileNetV3
论文地址:1905.02244.pdf (arxiv.org)
项目地址:pytorch框架
xiaolai-sqlai/mobilenetv3: mobilenetv3 with pytorch,provide pre-train model (github.com)

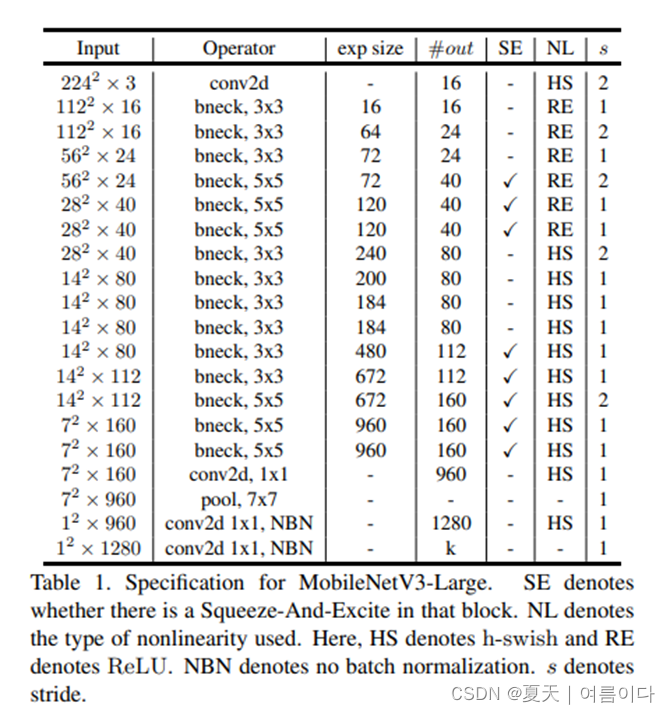
1.3.1 MobileNetV3 for Image Classification
论文地址:MobileNetV3 for Image Classification | IEEE Conference Publication | IEEE Xplore
在论文中,比较了MobileNetV3的性能。AlexNet、InceptionV3和ShuffleNetV2在不同的数据集,并验证了MobileNetV3的效率和适应性。论文的主要贡献可以概括为归纳为以下几点。
1) 果实360,10个猴子物种和鸟类物种分类,作为移动设备上常见图像的代表数据集,用于训练和评估所选神经网络的性能。
2) MobileNetV3、AlexNet、InceptionV3和ShuffleNetV2
被应用于多个与移动场景相关的图像分类任务。
移动场景相关的多个图像分类任务。
3)采用多种评价指标来分析不同模型在不同数据集上的表现。
4)根据实验结果,总结了MobileNetV3在图像分类上的特点和它在移动设备上的优势。
1.3.2 2020GhostNet
论文地址:
项目地址:https: //github.com/huawei-noah/ghostnet
主要思想:
提出的Ghost模块可以作为一个即插即用的组件来升级现有的卷积神经网络。


1.3.3 2021SkipblockNet(基于MobileNetv3的修改)
论文地址:Bias Loss for Mobile Neural Networks (thecvf.com)
项目地址:pytorch框架

图4. SkipblockNet架构的概述。在此基础上倒置的残差,SkipblockNet使用跳块将第一块的高级特征转移到最后一层。该网络故意设计得很简单,这使得我们可以集中精力于新颖的偏置损失的贡献,它通过将训练集中在一组偏置损失上而提高了性能。通过将训练集中在一组具有丰富学习信号的数据点上来提高性能。
二 2017Xception
论文地址:Xception: Deep Learning With Depthwise Separable Convolutions (thecvf.com)
三 ShuffleNet系列
3.1 2018ShuffleNetV1
ShuffleNet:An Extremely Efficient Convolutional Neural Network for Mobile Devices
论文地址:CVPR 2018 Open Access Repository
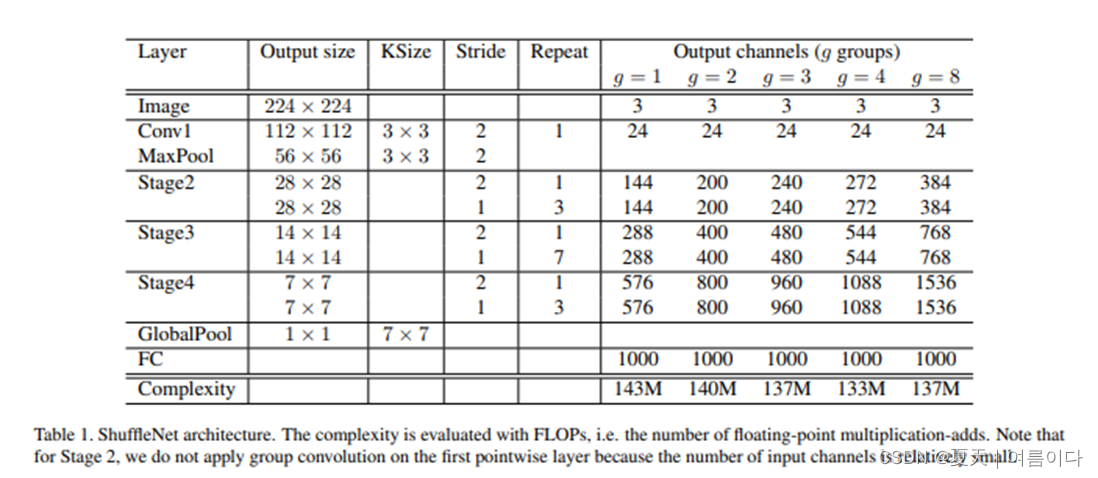
主要思想:提出顺时针分组卷积和信道洗牌,以大大降低计算成本,同时保持准确性。
ShuffleNetV1采用了pointwise组卷积和类似bottleneck的结构。另外引入一个channel shuffle操作使得不同组的通道信息流通。
由上述4个准则可知,pointwise组卷积和bottleneck结构增加MAC,这违反了G1和G2。使用过多的组数违反了G3。逐元素相加违反了G4。
因此,为了实现较高的模型容量和效率,关键问题是如何保持大量且同样宽的通道,既没有密集卷积也没有太多的分组。
3.2 2018ShuffleNetV2
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
以往的工作都是用FLOPs来衡量计算复杂度的,然而FLOPs不是一个直接的指标,本论文关心的是speed。
四个准则
对轻量级网络各种操作的运行时间进行分析,作者提出了4个准则:
G1:通道宽度均衡可以最小化MAC。
G2:增加组卷积会增加MAC。
G3:网络碎片化降低了并行度。
G4:元素操作是不可忽略的。
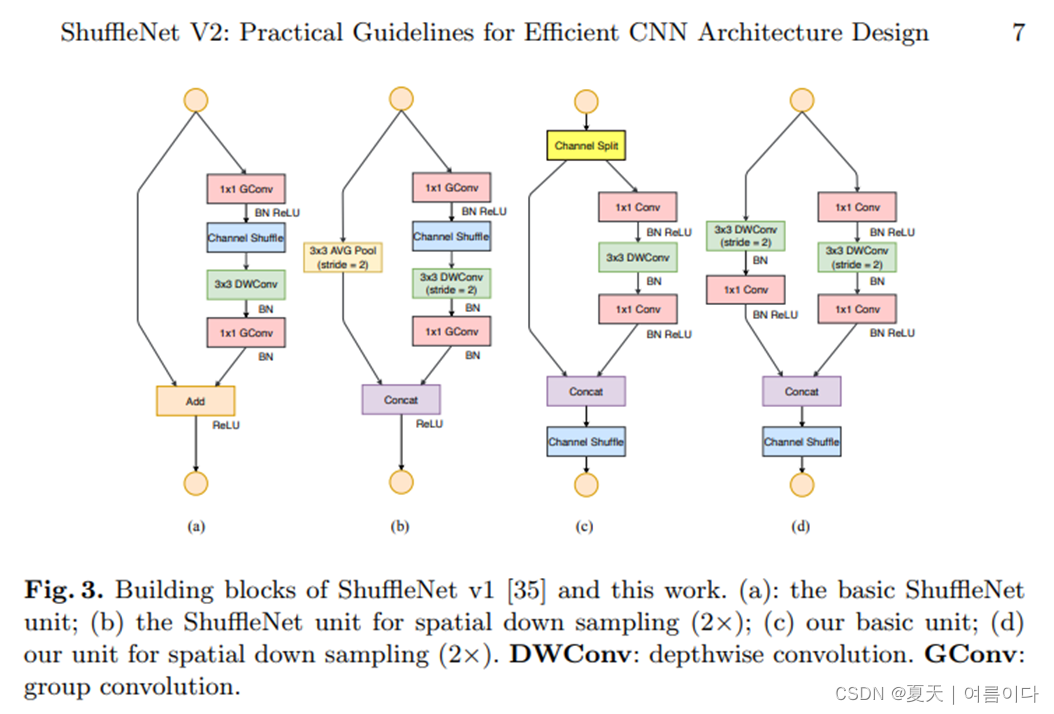
在每个单元的开始,输入通道数为c的feature通过channel split分成了2个分支,按照准则G3,一个分支作为identity,另一个分支由3个输入输出通道数相同的卷积组成(满足准则G1)。两个1x1卷积不再是group-wise的了,一部分原因是准则G2,另一部分原因是channel split操作已经分成了两组。卷积后,两个分支concat操作,因此输出通道数和输入通道数保持相同(满足准则G1)。随后引入channel shuffle使得两个分支的通道信息流通。
值得注意的是,ShuffleNetV2去掉了Add操作,元素操作比如ReLU和depth-wise convolutions只在一个分支中存在。并且3个连续的操作Concat、Channel Shuffle和Channel Split被合并成一个元素操作。按照准则G4,这些改变对精度是有帮助的。
对于带有下采样的模块,需要稍微修改一下模块,移除掉channel split操作。输出的通道数增加一倍。

四 2019EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks重新思考卷积神经网络的模型缩放
论文地址:http://proceedings.mlr.press/v97/tan19a/tan19a.pdf
论文提出了一种新的缩放方法,该方法使用简单但高效的复合系数统一缩放深度/宽度/分辨率的所有维度。论文证明了这种方法在 MobileNets 和 ResNet 上的有效性。更进一步使用神经架构搜索来设计一个新的基线网络并将其放大以获得一系列模型,称为 EfficientNets,它们比以前的 ConvNets 实现了更好的准确性和效率。

5 PPLCNet:CPU端强悍担当,吊打现有主流轻量型网络,百度提出CPU端的最强轻量型架构
Paper:2109.15099.pdf (arxiv.org)
主要思想:
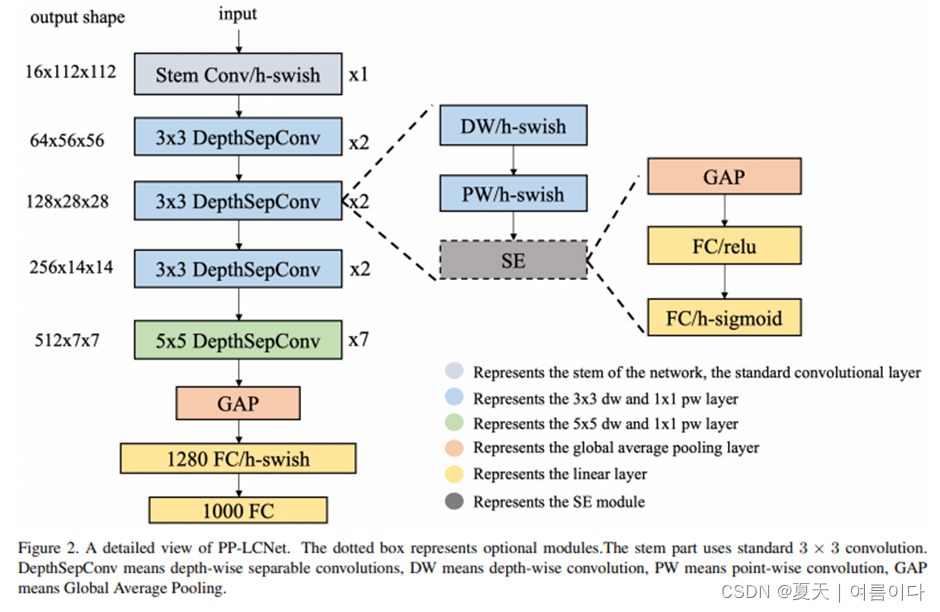




总结:
轻量级网络的俩个关键点:计算复杂度和速度
卷积核的大小一般有1x1,3x3和5x5的尺寸(一般是奇数x奇数)
卷积核大小必须大于1才有提升感受野的作用,所以最常用于特征提取的卷积核不能为1
函数g一般称为过滤器(filters),函数f指的是信号/图像。
 思考?
思考?
1:为什么卷积核总是奇数?
因为偶数卷积核在进行卷积操作时,很难找到卷积的中心点,导致在填充的时候像素特征不断偏移,随着层次的加深,偏移现象就会越来越明显,
举一个不是很正确的例子(为了很好的理解):
一张3*3的图1和一张4*4的图找中心点

如果想要通过一个点确认位置,3*3的中心点是5里边,而4*4的中心点却无法直接说出来,因为它在6和7之间,点的半径大一点的话可能又是6又是7,中间徒增计算量。
2:大卷积核和小卷积核的区别:
计算量差别(一个不太精确地例子,5*5=25,俩次3*3,就是9+9=16)
小卷积核比大卷积核减少了网络参数
一般情况下,卷积核越大,感受野越大,看到的图片信息越多,所获得的全局特征越好。但大的卷积核会导致计算量的暴增,计算性能也会降低。















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











