







 本文介绍了自监督学习的概念,强调了在无标签数据集上的学习过程,以及如何通过设计辅助任务来获取监督信息。对比学习作为自监督学习的一种,通过构造正负样本学习特征表示。主要步骤包括数据增强、编码和损失最小化。应用领域广泛,如CV、推荐系统和NLP。关键词涉及数据增强、编码器、损失函数和无监督学习策略。
本文介绍了自监督学习的概念,强调了在无标签数据集上的学习过程,以及如何通过设计辅助任务来获取监督信息。对比学习作为自监督学习的一种,通过构造正负样本学习特征表示。主要步骤包括数据增强、编码和损失最小化。应用领域广泛,如CV、推荐系统和NLP。关键词涉及数据增强、编码器、损失函数和无监督学习策略。
视频学习链接:
Contrastive Learning(对比学习)基础讲解_哔哩哔哩_bilibili
背景
在基于深度学习的模型中,一个带标签的大数据集(比如Imagenet)是至关重要的,例如之前我曾经实现的visual trainsformer神经网络,其结果受数据集的影响很大,在小数据集上效果很差,甚至不如LeNet5神经网络。
在现实中,很多情况没有大规模标注的数据集,如医学影像领域以及数据稀疏的推荐系统领域,要如何提升模型的特征提取能力呢?自监督学习就应运而生了。

自监督学习(Self-supervised learning) 旨在对于无标签数据 ,通过设计辅助任务(Proxy tasks)来挖掘数据自身的表征特性作为监督信息,提升模型的特征提取能力。这里与其他几种学习方式做一下区分:
1. 有监督(Supervised): 监督学习是从给定的带标签训练数据集中学习出一个函数(模型参数),在输入新的测试数据时,可以根据这个函数预测结果;
2. 无监督(Unsupervisedg): 无监督学习是从无标签数据中分析数据本身的规律性等解析特征。无监督学习算法分为两大类:基于概率密度函数估计的方法和基于样本间相似性度量的方法;
3. 半监督习(Semi-supervised): 半监督介于监督学习和无监督之间,即训练集中只有一部分数据有标签,需要通过伪标签生成等方式完成模型训练;
4. 弱监督(Weakly-supervised): 弱监督是指训练数据只有不确切或者不完全的标签信息,比如在目标检测任务中,训练数据只有分类的类别标签,没有包含Bounding box坐标信息。
在上述概念中,无监督和自监督学习相似性最大,两者的训练数据都是无标签,但区别在于:自监督学习会通过构造辅助任务来获取监督信息,这个过程中有学习到新的知识;而无监督学习不会从数据中挖掘新任务的标签信息。
其中辅助任务的指的是为达到特定训练任务⽽设计的间接任务。pretext任务的好处是为了简化原任务的求解,在深度学习中就是避免⼈⼯标记样本,实现⽆监督的语义提取。Pretext任务可以进⼀步理解为:对⽬标任务有帮助的辅助任务。主要pretext task包括:图像旋转、图像着⾊、图像修复,即类似于数据增强的操作。
关系
对比学习与自监督学习的关系:
⾃监督学习算法分为两种:对⽐⽅法和⽣成⽅法。对⽐学习属于⾃监督学习,所以对⽐学习是没有标签的。对⽐学习是通过构造正负样例来学习特征。如何构造正负样例对对⽐学习来说很重要。对于⼀个输⼊样本x来说,存在与之相似的样本x+以及与之不相似的样本x-,对⽐学习要做的就是学习⼀个编码器f,这个编码器f能够拉近x与其正样本间的距离,推远x与其负样本之间的距离。即:
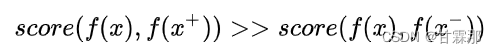
生成式自监督学习与对比式自监督学习:
生成式:训练编码器将输入x编码成显式向量z,解码器从z重建x,最小化重建误差;
对比式:练编码器将输入x编码成显式向量z以度量相似性(例如互信息最大化)。
思想
对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。

本质上,对比学习允许我们的机器学习模型做同样的事情。它会观察哪些数据点对“相似”和“不同”,以便在执行分类或分割等任务之前了解数据更高阶的特征。如学习猫和狗的分类。
原理
图像领域的自监督对比过程描述为三个基本步骤:
(1)对于数据集中的每个图像,我们可以执行两种增强组合(即裁剪 + 调整大小 + 重新着色、调整大小 + 重新着色、裁剪 + 重新着色等)。我们希望模型知道这两个图像是“相似的”,因为它们本质上是同一图像的不同版本。
(2)将这两个图像输入到我们的深度学习模型(Big-CNN,例如 ResNet)中,为每个图像创建向量表示。目标是训练模型输出相似图像的相似表示。
(3)最后通过最小化对比损失函数来最大化两个向量表示的相似性。
通过分解为三个主要步骤来进一步剖析这种对比学习方法:数据增强、编码和损失最小化。
值得注意的是,不同领域的数据增强的操作有所不同:图像领域中的扰动大致可分为两类:空间/几何扰动和外观/色彩扰动。空间/几何扰动的方式包括但不限于图片翻转(flip)、图片旋转(rotation)、图片挖剪(cutout)、图片剪切并放大(crop and resize)。外观扰动包括但不限于色彩失真、加高斯噪声等

自然语言领域的扰动也大致可分为两类:词级别(token-level)和表示级别(embedding-level)。词级别的扰动大致有句子剪裁(crop)、删除词/词块(span)、换序、同义词替换等。表示级别的扰动包括加高斯噪声、dropout等。

另外,对比学习还有多种特殊的损失函数应用不同的领域:
1. 原始对比损失
2. 三元组损失
3. InfoNCE损失
详细请参考:对比学习(一)简介_白衣西蜀梅子酒的博客-CSDN博客_对比学习
总结
对比学习应用广泛,可以被使用于CV、推荐系统、自然语言处理等多个领域之中,可以有效解决标记数据不足的网络训练困难、不准确的问题。
参考视频链接:NLP中的自监督学习和对比学习_哔哩哔哩_bilibili
【论文笔记·对比学习】05 Contrastive Learning of Structured World Models_哔哩哔哩_bilibili

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









