







每天给你送来NLP技术干货!
推荐系统
作者:炼丹小助手
来自:炼丹笔记
这篇主要探讨SimCLR,不需要用监督学习(supervision)的方式,采用自监督(self-supervised)的方式使得模型学到很多有用的patterns。众所周知,使用对比学习(修改样本,loss等小trick)就可以显著提高模型的泛化能力,所以我们都需要掌握这项"技艺"。
Self-Supervised Learning(SSL):自监督学习是目前机器学习中一个非常流行的分支,不管监督学习已经多么精准,最终能显著提升监督模型效果的永远是更多的有标签的数据。但是真实情况是,很多任务很难有大量标注的数据。SSL目标就是从无标注数据获取标注,并用他们来训练,在NLP中,我们随机mask掉部分文本,让模型去做完型填空。在几个G的语料库上这样学习后,模型就已经学到了很多语法知识,单词语意等。
研究证明,将这一思想推广到计算机视觉没啥用。想象一下,通过前几帧预测视频中的下一帧。乍一看,这与NLP中的掩蔽非常相似,但问题是,网络可以做出无数看似合理的预测,并且无法计算每一帧的概率,因为我们处于一个超高维、连续的空间中。

Contrastive Learning: 当研究两个物体时,我们很容易区分它们,即使以前从未见过它们。例如,一只狗和一把椅子,尽管它们的颜色可能彼此相似,但会有非常明显的特征,而一对狗,尽管它们的品种差异很小,但属于同一类别,我们会认识到这一事实。换句话说,通过辨别一个物体的视觉特征,能够在它和其他事物之间形成对比。
如下图所示,可以从一个物体中提取三个属性:I)它的颜色有多暗(0表示白色,1表示黑色),II)它有多可爱(0表示一点也不可爱,1表示非常可爱),以及III)它有多“舒适”(0表示一点也不舒适,1表示非常舒适),因此椅子比椅子和狗有更高的余弦相似性。
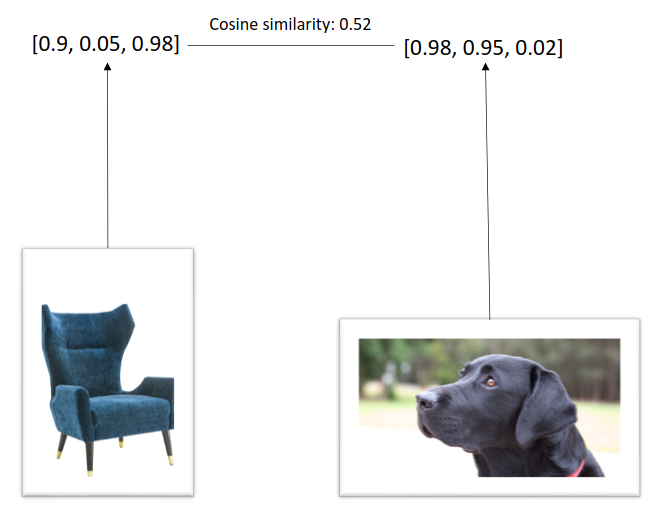

对比学习的工作原理类似,目的是从图像中提取特征,同时努力将相似的图片(也称为正对)放在一起,而将不同的图片(也称为负对)放在很远的地方。目前对比学习已经做了大量的研究,本文从《A Simple Framework for Contrastive Learning of Visual Representations》一文中的提出的SimCLR入手,SimCLR基本可以认为是学对比学习的基石了。
SimCLR:在图像分类任务中,如果每张照片都属于一个类,最基本的就要构造正负样本对,前者是来自一个类别的实例,后者是来自两个类别的两个数据点。然而,这将破坏SSL的目的,因此我们必须设计一种解决方案,处理成堆的未标记数据。SimCLR的方法是将每个图像视为一个单独的类别,并对其进行扩充,以便为每个所谓的类生成实例。例如,与配对(需要监督)不同,下图每行都是正例,随机取两行,取yige:
正例对: (蓝色的椅子, 白色的椅子)
负例对: (蓝色的椅子,狗)



有趣的是,数据增强在自我监督模型的准确性方面起着决定性的作用,即使它可能会损害监督训练。作者对各种数据增强进行了实验,并提出了三种精度最高的增强方法:
Crop, resize, flip: The picture is cropped (the area of the cropped piece is between 8% to 100% of the original size, and the aspect ratio between 3/4 and 4/3), resized back to its original dimensions, and flipped horizontally (with a 50% chance).
Colour distortion: Colour jitter (alter the brightness, contrast, saturation, and hue) with a hyperparameter to control its intensity in composition with greying out the picture, with probabilities of 80% and 20% respectively.
Gaussian blur: A Gaussian kernel 10% of the size of the picture blurs the image half the time. The standard deviation for creating the kernel is randomly picked from the range [0.1, 2.0].
代码也比较简单:
from torchvision import transforms
# Size used in SimCLR
size = 224
crop_resize_flip = transforms.Compose([transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(3/4, 4/3)),
transforms.RandomHorizontalFlip(p=0.5)])
# Higher means stronger
s = 1.0
# 0.8*s and 0.2*s are from the paper
colour_jitter = transforms.ColorJitter(brightness=0.8*s, contrast=0.8*s, saturation=0.8*s, hue=0.2*s)
colour_jitter = transforms.RandomApply([colour_jitter], p=0.8)
colour_distortion = transforms.Compose([colour_jitter,
transforms.RandomGrayscale(p=0.2)])
kernel_size = int(0.1*size)
# The size of the kernel must be odd
kernel_size = kernel_size if kernel_size%2 == 1 else kernel_size+1
gaussian_blur = transforms.GaussianBlur(kernel_size, sigma=(0.1, 2.0))
gaussian_blur = transforms.RandomApply([gaussian_blur], p=0.5)
augment = transforms.Compose([crop_resize_flip,
colour_distortion,
gaussian_blur])这几项简单的数据增强技术如何能够提供截然不同的图像版本,从而提高SSL的性能。接下来,我们将数据输入模型,并指示它在不同的图像之间进行对比,以获得没有任何标签的有用视觉模式。
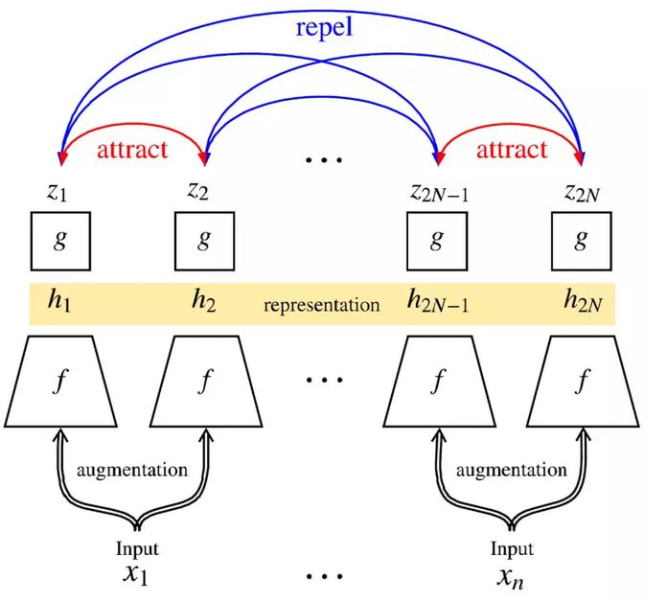
有了数据增强,就可以先随机采样一个batch,每个batch两次增强,让同一张图的不同view在latent space里靠近,不同图的view在latent space里远离,如下图所示。SimCLR使用ResNet-50(4x)作为模型,并在无监督学习后训练了一个linear classifier,最后取得了相当好的效果。
参考文献

SimCLR:https://arxiv.org/pdf/2002.05709.pdf
https://zhuanlan.zhihu.com/p/107269105
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









