









| 标题 | Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model |
|---|---|
| 论文地址 | https://arxiv.org/pdf/2401.09417.pdf |
| 项目地址 | https://github.com/hustvl/Vim |
速通版
提出了Vision Mamba(Vim),它结合了双向SSM,用于数据依赖的全局视觉上下文建模和位置嵌入,用于位置感知视觉理解。所提出的Vim具有与ViT相同的建模能力,而它只有次二次时间复杂性和线性内存复杂性。在准确率和效率上都有一定的提升,作者期待它成为下一代视觉backbone,并且有更多的下游任务的探索。
原文部分翻译
Abstract
Recently the state space models (SSMs) with efficient hardware-aware designs, i.e., Mamba, have shown great potential for long sequence modeling. Building efficient and generic vision backbones purely upon SSMs is an appealing direction. However, representing visual data is challenging for SSMs due to the position-sensitivity of visual data and the requirement of global context for visual understanding. In this paper, we show that the reliance of visual representation learning on self-attention is not necessary and propose a new generic vision backbone with bidirectional Mamba blocks (Vim), which marks the image sequences with position embeddings and compresses the visual representation with bidirectional state space models. On ImageNet classification, COCO object detection, and ADE20k semantic segmentation tasks, Vim achieves higher performance compared to well-established vision transformers like DeiT, while also demonstrating significantly improved computation & memory efficiency. For example, Vim is 2.8× faster than DeiT and saves 86.8% GPU memory when performing batch inference to extract features on images with a resolution of 1248×1248. The results demonstrate that Vim is capable of overcoming the computation & memory constraints on performing Transformer-style understanding for high-resolution images and it has great potential to become the next-generation backbone for vision foundation models.
最近,具有高效硬件感知设计的状态空间模型(SSMs),即Mamba,在长序列建模方面显示出巨大潜力。纯粹基于SSMs构建高效通用的视觉backbone是一个有吸引力的方向。然而,由于视觉数据的位置敏感性和视觉理解对全局上下文的要求,对于ssm来说,视觉表示数据是一个挑战。在本文中,我们证明了视觉表示学习对自注意力的依赖并非必要,并提出了一种新的具有双向Mamba块(Vim)的通用视觉骨干,它使用位置嵌入标记图像序列,并利用双向状态空间模型压缩视觉表示。在ImageNet分类、COCO目标检测和ADE20k语义分割任务中,与DeiT等成熟的视觉Transformer相比,Vim实现了更高的性能,同时还显著提高了计算和内存效率。例如,当对分辨率为1248×1248的图像进行批量推理以提取特征时,Vim比DeiT快2.8倍,节省了86.8%的GPU内存。结果表明,Vim能够克服对于高分辨率图像执行Transformer-style理解的计算和内存限制,并具有成为视觉基础模型的下一代骨干的巨大潜力。
Intro
Recent research advancements have led to a surge of interest in the state space model (SSM). Originating from the classic state space model [30], modern SSMs excel at capturing long-range dependencies and benefit from parallel training. Some SSM-based methods, such as the linear state-space layers (LSSL) [22], structured state space sequence model (S4) [21], diagonal state space (DSS) [24],and S4D [23], are proposed to process sequence data across a wide range of tasks and modalities, particularly on modeling long-range dependencies. They are efficient on long sequences because of convolutional computation and nearlinear computation. 2-D SSM [2], SGConvNeXt [37], and ConvSSM [52] combine SSM with CNN or Transformer architecture to process 2-D data. The recent work, Mamba [20], incorporates time-varying parameters into the SSM and proposes a hardware-aware algorithm to enable efficient training and inference. The superior scaling performance of Mamba indicates that it is a promising alternative to Transformer in language modeling. Nevertheless, a generic pure-SSM-based backbone has not been explored for vision tasks.
最近的研究进展导致了对状态空间模型(SSM)激增。现代ssm源自经典的状态空间模型[30],擅长捕获远程依赖关系,并受益于并行训练。一些基于ssm的方法,如线性状态空间层(LSSL)[22]、结构化状态空间序列模型(S4)[21]、对角状态空间(DSS)[24]和S4D [23], 被提出来处理序列数据,特别是用来在远程依赖关系方面进行建模,这些数据广泛存在于各类的任务和模式中。由于卷积计算和近线性计算,它们在长序列上是有效的。二维SSM[2]、SGConvNeXt[37]和ConvSSM[52]将SSM与CNN或Transformer架构结合起来处理二维数据。最近的工作Mamba[20]将时变参数纳入SSM,并提出了一种硬件感知算法,以实现高效的训练和推理。Mamba优越的伸缩性能表明,它是语言建模中替代Transformer的一个很有前途的选择。然而,视觉任务上一个通用的纯ssm为基础的backbone还没有被探索。
Vision Transformers (ViTs) have achieved great success in visual representation learning, excelling in both largescale self-supervised pre-training and high performance on downstream tasks. Compared with convolutional neural networks, the core advantage lies in that ViT can provide each image patch with data/patch-dependent global context through self-attention. This differs from convolutional networks that use the same parameters, i.e., the convolutional filters, for all positions. Another advantage is the modalityagnostic modeling by treating an image as a sequence of patches without 2D inductive bias, which makes it the preferred architecture for multimodal applications [3, 36, 40].At the same time, the self-attention mechanism in Transformers poses challenges in terms of speed and memory usage when dealing with long-range visual dependencies, e.g., processing high-resolution images.
视觉Transformer(Vision Transformers, ViTs)在视觉表征学习方面取得了巨大的成功,在大规模自监督预训练和下游任务上都表现优异。与卷积神经网络相比,其核心优势在于ViT可以通过自注意力为每个图像patch提供数据依赖或块依赖的全局上下文。这与卷积网络不同,卷积网络,即卷积滤波器,在所有位置使用相同的参数。另一个优点是模态不可知建模,通过将图像视为一系列没有二维偏置的块,这使其成为多模态应用的首选架构[3,36,40]。与此同时,transformer中的自注意机制在处理远程视觉依赖(例如,处理高分辨率图像)时,在速度和内存使用方面面临挑战。
Motivated by the success of Mamba in language modeling, it is appealing that we can also transfer this success from language to vision, i.e., to design a generic and efficient visual backbone with the advanced SSM method.However, there are two challenges for Mamba, i.e., unidirectional modeling and lack of positional awareness. To address these challenges, we propose the Vision Mamba (Vim) block, which incorporates the bidirectional SSMs for data-dependent global visual context modeling and position embeddings for location-aware visual recognition. We first split the input image into patches and linearly project them as vectors to Vim. Image patches are treated as the sequence data in Vim blocks, which efficiently compresses the visual representation with the proposed bidirectional selective state space. Furthermore, the position embedding in Vim block provides the awareness for spatial information, which enables Vim to be more robust in dense prediction tasks. In the current stage, we train the Vim model on the supervised image classification task using the ImageNet dataset and then use the pretrained Vim as the backbone to perform sequential visual representation learning for downstream dense prediction tasks, i.e., semantic segmentation, object detection, and instance segmentation.Like Transformers, Vim can be pretrained on large-scale unsupervised visual data for better visual representation. Thanks to the better efficiency of Mamba, the large-scale pretraining of Vim can be achieved with lower computational cost.
受Mamba在语言建模方面的成功启发,我们也可以将这种成功从语言转移到视觉上,即利用先进的SSM方法设计一个通用的、高效的视觉主干。然而,Mamba面临两个挑战,即单向建模和缺乏位置意识。为了解决这些挑战,我们提出了Vision Mamba(Vim)块,它结合了用于数据依赖的全局视觉上下文建模的双向ssm和用于位置感知视觉识别的位置嵌入。我们首先将输入图像分割成patch,并将它们作为向量线性投影到Vim上。将图像块作为Vim块中的序列数据,利用所提出的双向可选状态空间有效地压缩视觉表示。此外,Vim块中的位置嵌入提供了对空间信息的感知,使Vim在密集预测任务中具有更强的鲁棒性。在当前阶段,我们使用ImageNet数据集在监督图像分类任务上训练Vim模型,然后使用预训练的Vim作为主干,对下游密集预测任务(即语义分割、对象检测和实例分割)进行顺序视觉表示学习。因此,Vim可以在大规模无监督的视觉数据上进行预训练,以获得更好的视觉表现。由于Mamba具有更好的效率,可以用更低的计算成本实现Vim的大规模预训练。
Compared with other SSM-based models for vision tasks, Vim is a pure-SSM-based method and models images in a sequence manner, which is more promising for a generic and efficient backbone. Thanks to the bidirectional compressing modeling with positional awareness, Vim is the first pure-SSM-based model to handle dense prediction tasks. Compared with the most convincing Transformerbased model, i.e., DeiT [60], Vim achieves superior performance on ImageNet classification. Furthermore, Vim is more efficient in terms of GPU memory and inference time for high-resolution images. The efficiency in terms of memory and speed empowers Vim to directly perform sequential visual representation learning without relying on 2D priors (such as the 2D local window in ViTDet [38]) for high-resolution visual understanding tasks while achieving higher accuracy than DeiT.
与其他基于ssm的视觉任务模型相比,Vim是一种纯基于ssm的方法,以序列方式对图像进行建模,更有希望建立通用高效的主干。由于具有位置感知的双向压缩建模,Vim是第一个处理密集预测任务的纯基于ssm的模型。与最有说服力的基于transformer的模型DeiT[60]相比,Vim在ImageNet分类上取得了更优异的性能。此外,Vim在GPU内存和高分辨率图像的推理时间方面更高效。在内存和速度方面的效率使Vim能够直接执行顺序视觉表示学习,而不依赖于2维先验 (如ViTDet中的2D局部窗口[38]) 来完成高分辨率的视觉理解任务,同时实现比DeiT更高的精度。
Our main contributions can be summarized as follows:
- We propose Vision Mamba (Vim), which incorporates bidirectional SSM for data-dependent global visual context modeling and position embeddings for locationaware visual understanding.
- Without the need of attention, the proposed Vim has the same modeling power as ViT while it only has subquadratic-time computation and linear memory complexity. Specifically, our Vim is 2.8× faster than DeiT and saves 86.8% GPU memory when performing batch inference to extract features on images at the resolution of 1248×1248.
- We conduct extensive experiments on ImageNet classification and dense prediction downstream tasks. The results demonstrate that Vim achieves superior performance compared to the well-established and highly-optimized plain vision Transformer, i.e., DeiT.
- Benefiting from the efficient hardware-aware design of Mamba, Vim is much more efficient than the selfattention-based DeiT [60] for high-resolution computer vision tasks, e.g., video segmentation, aerial image analysis, medical image segmentation, computational pathology.
我们的主要贡献可以总结如下:
- 我们提出了Vision Mamba(Vim),它结合了双向SSM,用于数据依赖的全局视觉上下文建模和位置嵌入,用于位置感知视觉理解。
- 哎你别说,所提出的Vim具有与ViT相同的建模能力,而它只有次二次时间复杂性和线性内存复杂性。具体来说,我们的Vim比DeiT快2.8倍,在执行批处理推理以提取分辨率为1248×1248的图像上的特征时节省了86.8%的GPU内存。
- 我们对ImageNet分类和密集预测下游任务进行了广泛的实验。结果表明,与成熟且高度优化的plain vision Transformer(即DeiT)相比,Vim具有优越的性能。
- 得益于Mamba高效的硬件感知设计,对于高分辨率计算机视觉任务,例如视频分割、航空图像分析、医学图像分割、计算病理学,Vim比基于自注意的DeiT[60]效率更高。
Related work
Architectures for generic vision backbone
In the early eras, ConvNet [34] serves as the de-facto standard network design for computer vision. Many convolutional neural architectures [25, 26, 33, 50, 51, 56–58, 63, 72] have been proposed as the vision backbone for various visual applications. The pioneering work, Vision Transformer (ViT) [14] changes the landscape. It treats an image as a sequence of flattened 2D patches and directly applies a pure Transformer architecture. The surprising results of ViT on image classification and its scaling ability encourage a lot of follow-up works [16, 59, 61, 62]. One line of works focuses on hybrid architecture designs by introducing 2D convolutional priors into ViT [9, 13, 15, 69]. PVT [66] proposes a pyramid structure Transformer. Swin Transformer [42] applies self-attention within shift windows. Another line of works focuses on improving traditional 2D ConvNets with more advanced settings [41, 67]. ConvNeXt [43] reviews the design space and proposes pure ConvNets, which can be scalable as ViT and its variants. RepLKNet [12] proposes to scale up the kernel size of existing ConvNets to bring improvements.
Convnet、Vit、Swin等逐渐登场。
Though these dominant follow-up works demonstrate superior performance and better efficiency on ImageNet [10] and various downstream tasks [39, 74] by introducing 2D priors, with the surge of large-scale visual pretraining [1, 5, 17] and multi-modality applications [3, 29, 35, 36, 40, 49], vanilla Transformer-style model strikes back to the center stage of computer vision. The advantages of larger modeling capacity, unified multi-modality representation, being friendly to self-supervised learning etc., make it the preferred architecture. However, the number of visual tokens is limited due to the quadratic complexity of Transformer. There are plenty of works [7, 8, 11, 32, 48, 55, 65] to address this long-standing and prominent challenge, but few of them focus on visual applications. Recently, LongViT [68] built an efficient Transformer architecture for computational pathology applications via dilated attention. The linear computation complexity of LongViT allows it to encode the extremely long visual sequence. In this work, we draw inspiration from Mamba [20] and explore building a pure-SSM-based model as a generic vision backbone without using attention, while preserving the sequential, modality-agnostic modeling merit of ViT.
它们很强、但还不够强。
State space models for long sequence modeling
[21] proposes a Structured State-Space Sequence (S4) model, a novel alternative to CNNs or Transformers, to model the long-range dependency. The promising property of linearly scaling in sequence length attracts further explorations. [53] proposes a new S5 layer by introducing MIMO SSM and efficient parallel scan into S4 layer. [18] designs a new SSM layer, H3, that nearly fills the performance gap between SSMs and Transformer attention in language modeling. [46] builds the Gated State Space layer on S4 by introducing more gating units to improve the expressivity. Recently, [20] proposes a data-dependent SSM layer and builds a generic language model backbone, Mamba, which outperforms Transformers at various sizes on large-scale real data and enjoys linear scaling in sequence length. In this work, we explore transferring the success of Mamba to vision, i.e., building a generic vision backbone purely upon SSM without attention.
[20]提出了一个依赖于数据的SSM层,并构建了一个通用语言模型主干Mamba. 我们把它迁移到了视觉上,也就是本文的Vim。
State space models for visual applications
[27] uses 1D S4 to handle the long-range temporal dependencies for video classification. [47] further extends 1D S4 to handle multi-dimensional data including 2D images and 3D videos. [28] combines the strengths of S4 and self-attention to build TranS4mer model, achieving state-of-the-art performance for movie scene detection. [64] introduces a novel selectivity mechanism to S4, largely improving the performance of S4 on long-form video understanding with a much lower memory footprint. [73] supplants attention mechanisms with a more scalable SSM-based backbone to generate high-resolution images and process fine-grained representation under affordable computation. [45] proposes U-Mamba, a hybrid CNN-SSM architecture, to handle the long-range dependencies in biomedical image segmentation. The above works either apply SSM to specific visual applications or build a hybrid architecture by combining SSM with convolution or attention. Different from them, we build a pure-SSM-based model, which can be adopted as a generic vision backbone.
之前有很多视觉上的空间状态建模的应用了,本文是一种纯SSM模型,因此可以用作通用视觉backbone。
Method
The goal of Vision Mamba (Vim) is to introduce the advanced state space model (SSM), i.e., Mamba [20], to computer vision. This section begins with a description of the preliminaries of SSM. It is followed by an overview of Vim.We then detail how the Vim block processes input token sequences and proceed to illustrate the architecture details of Vim. The section concludes with an analysis of the efficiency of the proposed Vim.
Vision Mamba(Vim)的目标是将状态空间模型(SSM)[20]引入计算机视觉。本节首先描述SSM的准备工作。接下来是对Vim的概述。然后详细介绍Vim块如何处理输入令牌序列,并继续说明Vim的体系结构细节。本节最后分析了所提出的Vim的效率。
Preliminaries
原文呢?太难贴了,不写了,看论文得了(可恶啊
基于ssm的模型,即结构化状态空间序列模型(S4)和Mamba的灵感来自连续系统,连续系统通过隐藏状态h(t)∈
R
N
R^N
RN映射一个一维函数或序列x(t)∈R→y(t)∈R。该系统使用A∈
R
(
N
×
N
)
R^{(N×N)}
R(N×N)作为进化参数,B∈
R
N
×
1
R^{N×1}
RN×1, C∈
R
1
×
N
R^{1×N}
R1×N作为投影参数。

S4和Mamba是连续系统的离散版本,其中包含一个时间标度参数∆,将连续参数A、B变换为离散参数
A
‾
\overline{A}
A、
B
‾
\overline{B}
B,常用的变换方法是零阶保持器(zero-order保持器,ZOH),定义如下:

在对
A
‾
\overline{A}
A、
B
‾
\overline{B}
B进行离散化后,采用步长∆的方程(1)的离散化版本可以改写为:

最后,模型通过全局卷积计算输出.

式中,M为输入序列x的长度,
K
‾
\overline{K}
K∈R M为结构化卷积核。
Vision Mamba
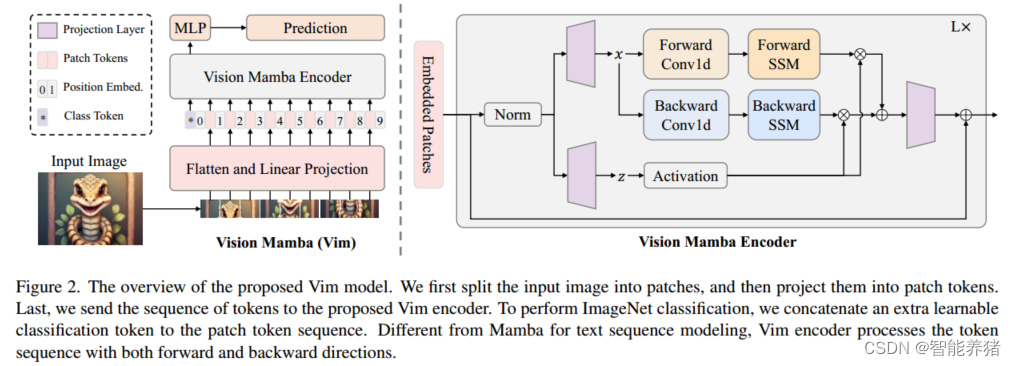
所提出的Vim的概述如图2所示。标准Mamba是为一维序列设计的。为了处理视觉任务,我们首先将二维图像t∈
R
H
×
W
×
C
R^{H×W×C}
RH×W×C变换为平面化的二维patch
x
p
∈
R
J
∗
(
p
2
⋅
C
)
x_p∈R ^{J * (p^2·C)}
xp∈RJ∗(p2⋅C),其中(H, W)为输入图像的大小,C为通道数,P为图像patch的大小。接下来,我们将
x
p
x_p
xp线性投影到大小为D的向量上,并添加位置嵌入
E
p
o
s
∈
R
(
J
+
1
)
∗
D
E_{pos}∈R ^{(J+1)*D}
Epos∈R(J+1)∗D,如下所示:

其中
t
p
j
t^j_p
tpj为t的第j块,
W
∈
R
(
p
2
⋅
C
)
∗
D
W∈R ^{ (p^2·C)*D}
W∈R(p2⋅C)∗D为可学习的投影矩阵。受ViT[14]和BERT[31]的启发,我们也使用类令牌来表示整个patch序列,记为
t
c
l
s
t_{cls}
tcls。然后,我们将令牌序列
(
T
l
−
1
)
(T_{l−1})
(Tl−1)发送到Vim编码器的第L层,得到输出Tl。最后,我们将输出的类令牌
T
L
0
T^0_L
TL0归一化,并将其馈送到多层感知器(MLP)头部,得到最终的预测
p
‾
\overline{p}
p,如下所示:

其中Vim为提议的Vision Mamba块,L为层数,Norm为正则化层。
Vim Block
原始的Mamba Block是为一维序列设计的,不适合需要空间感知理解的视觉任务。在本节中将介绍Vim块,它集成了用于视觉任务的双向序列建模。Vim模块如图2所示。
具体来说,给出了Vim block在算法1中的操作。输入符号序列
T
l
−
1
T_{l−1}
Tl−1首先由归一化层进行归一化。接下来,我们对归一化后的序列进行线性投影,转换为维度为E的x和z。然后分别从向前和向后两个方向处理x。对于每个方向,我们首先对x进行一维卷积得到x ’ 0。然后我们分别将x ’ o线性投影到Bo, Co,∆o。然后分别用∆o变换
A
o
‾
\overline{A_o}
Ao、
B
o
‾
\overline{B_o}
Bo。最后,我们通过SSM计算yf和yb。然后,yf和yb通过z进行门控,并将它们加在一起以得到输出标记序列T.

Architecture Details
综上所述,我们的架构的超参数如下:

继ViT[14]和DeiT[61]之后,我们首先采用16×16核大小投影层,得到1-D序列的无重叠补丁嵌入。随后,我们直接堆叠L个Vim块。默认情况下,我们将块数L设置为24,SSM维度N设置为16。为了和Deit系列对齐,我们将隐藏状态维D设置为192,将扩展状态维E设置为384。对于小尺寸的变体,我们将D设置为384,将E设置为768。
Experiment
Image Classification


简单说就是图像识别涨点了,并且在高分辨率推理节省空间,效率很高。
Semantic Segmentation

Object Detection and Instance Segmentation

Ablation Study

We ablate the key bidirectional design of Vim, using ImageNet-1K classification and Segmenter [54] on ADE20K semantic segmentation. To fully evaluate the power of learned representation on ImageNet, we use a simple Segmenter head with only 2 layers to perform transfer learning on semantic segmentation. We study these bidirectional strategies:
- None. We directly adopt Mamba block to process visual sequence with only the forward direction.
- Bidirectional Sequence. During training, we randomly flip the visual sequence. This works like data augmentation.
- Bidirectional Block. We pair the stacked blocks. The first block of each pair processes visual sequence in the forward direction, and the second block of each pair processes in the backward direction.
- Bidirectional SSM. We add an extra SSM for each block to process the visual sequence in the backward direction.
- Bidirectional SSM + Conv1d. Based on Bidirectional SSM, we further add a backward Conv1d before the backward SSM (Fig. 2).
我们去掉了Vim的关键双向设计,在ADE20K语义分割上使用ImageNet-1K分类和分割器[54]。为了充分评估ImageNet上学习表征的能力,我们使用一个只有2层的简单分割头来执行语义分割的迁移学习。我们研究了这些双向策略:
- None: 直接采用曼巴块处理视觉序列,只有向前的方向。
- Bidirectional Sequence: 在训练过程中,我们随机翻转视觉序列。这类似于数据增强。
- Bidirectional Block: 将堆叠的积木配对。每对的第一块按正向处理视觉序列,每对的第二块按逆向处理视觉序列。
- Bidirectional SSM: 为每个块添加一个额外的SSM,以反向处理视觉序列。
- Bidirectional SSM + Conv1d: 在双向SSM的基础上,进一步在反向SSM之前添加一个反向Conv1d(图2)。
As shown in Tab. 4, directly adopting Mamba block achieves good performance in classification. However, the unnatural unidirectional manner poses challenges in downstream dense prediction. Specifically, the preliminary bidirectional strategy of using Bidirectional Block achieves 7 points lower top-1 accuracy on classification. Yet, it outperforms the vanilla unidirectional Mamba block by 1.3 mIoU on semantic segmentation. By adding extra backward SSM and Conv1d, we achieve similar classification accuracy (73.1 top-1 acc vs. 73.2 top-1 acc) and exceptional segmentation superiority (34.8 mIoU vs. 32.3 mIoU). We use the strategy of Bidirectional SSM + Conv1d as the default setting in our Vim block.
如表4所示,直接采用Mamba block分类效果较好。然而,非自然的单向方式给下游密度预测带来了挑战。具体而言,使用Bidirectional Block的初步双向策略在分类上的top-1准确率降低了7分。然而,在语义分割上,它比普通的单向Mamba块高出1.3 mIoU。通过添加额外的后向SSM和Conv1d,我们获得了相似的分类精度(73.1 top-1 acc vs. 73.2 top-1 acc)和卓越的分割优势(34.8 mIoU vs. 32.3 mIoU)。我们在Vim块中使用双向SSM + Conv1d策略作为默认设置。
Conclusion and Future Work
Conclusion:参照Intro部分
In future works, Vim with the bidirectional SSM modeling with position embeddings is suitable for unsupervised tasks such as mask image modeling pretraining and the similar architecture with Mamba enables multimodal tasks such as CLIP-style pretraining. Based on the pretrained Vim weights, exploring the usefulness of Vim for analyzing high-resolution medical images, remote sensing images, and long videos, which can be regarded as downstream tasks, is very straightforward.
在未来的工作中,带有位置嵌入的双向SSM建模的Vim适用于无监督任务,如掩模图像建模预训练,而与Mamba相似的架构可以实现多模态任务,如clip风格的预训练。基于预训练的Vim权值,探索Vim在分析高分辨率医学图像、遥感图像和长视频(可视为下游任务)方面的有用性非常简单。

















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









