






论文:https://arxiv.org/abs/2401.09417
机构:华中科技大学&北京市人工智能研究院
摘要
近年来,具有高效硬件感知设计的状态空间模型(ssm),即Mamba深度学习模型,在长序列建模方面显示出巨大的潜力。同时,纯粹在ssm上构建高效和通用的视觉骨干是一个吸引人的方向。然而,由于视觉数据的位置敏感性和视觉理解对全局上下文的需求,表示视觉数据对ssm来说是具有挑战性的。本文表明,对视觉表示学习的自注意力的依赖是不必要的,并提出了一种新的双向Mamba块(Vim)的通用视觉骨干,用位置嵌入标记图像序列,用双向状态空间模型压缩视觉表示。在ImageNet分类、COCO目标检测和ADE20k语义分割任务中,与DeiT等公认的视觉transformer相比,Vim实现了更高的性能,同时也显示出显著提高的计算和内存效率。例如,Vim比DeiT快2.8倍,在对分辨率为1248×1248的图像进行批量推理提取特征时,Vim节省了86.8%的GPU内存。结果表明,Vim能够克服对高分辨率图像进行transformer式理解时的计算和内存限制,具有成为下一代视觉基础模型骨干的巨大潜力。
一、Introduce
1.1 SSM
近年来,状态空间模型(state space model, SSM)的研究进展引起了人们的极大兴趣。 现代ssm起源于经典的卡尔曼滤波模型,
一些基于ssm的方法:
- 线性状态空间层(LSSL):Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers
- 结构化状态空间序列模型(S4):Efficiently Modeling Long Sequences with Structured State Spaces
- 对角状态空间(DSS):Diagonal State Spaces are as Effective as Structured State Spaces
S4D:On the Parameterization and Initialization of Diagonal State Space Models
2- d数据:
- 2- d SSM:2-D SSM: A General Spatial Layer for Visual Transformers
- SGConvNeXt:What Makes Convolutional Models Great on Long Sequence Modeling?
- ConvSSM:Convolutional State Space Models for Long-Range Spatiotemporal Modeling
最近的工作Mamba[Mamba: Linear-Time Sequence Modeling with Selective State Spaces]将时变参数纳入SSM,并提出了一种硬件感知算法,以实现非常有效的训练和推理。
地位:Mamba优越的扩展性能表明,它是语言建模中很有前途的Transformer替代品。 然而,一个通用的基于纯ssm的骨干网络还没有被探索用于处理视觉数据,如图像和视频。
1.2 ViT
- 核心优势:在于ViT可以通过自注意力为每个图像块提供依赖于数据/块的全局上下文。
- 另一个优点是模态无关的建模,将图像视为无2D归纳偏差的补丁序列,这使其成为多模态应用的首选架构
- transformer中的自注意力机制在处理长程视觉依赖关系(例如处理高分辨率图像)时,在速度和内存使用方面提出了挑战。
1.3 ViM
受Mamba在语言建模方面的成功的激励,我们也可以将这种成功从语言转移到视觉,即用先进的SSM方法设计一个通用和有效的视觉骨干。
Mamba的挑战:
- 单向建模:Mamba原本用于语言处理,通常是单向的,这意味着它只能捕捉从前到后的序列依赖。
- 位置感知的缺失:Mamba在处理视觉数据时,需要对空间位置有所感知,这是它原本的设计中缺乏的。
解决方案:本文提出视觉Mamba (Vim)模型,包括用于数据依赖的全局视觉上下文建模的双向ssm和用于位置感知视觉识别的位置嵌入。
- 首先将输入图像分割成小块,并将它们作为向量线性投影到Vim。将图像块视为Vim块中的序列数据,利用双向选择状态空间有效地压缩了视觉表示。
- 此外,Vim块中的位置嵌入提供了对空间信息的感知,使Vim在密集预测任务中具有更强的鲁棒性。
优势:Vim可以在大规模无监督视觉数据上进行预训练,以获得更好的视觉表示。得益于Mamba较好的效率,Vim可以以较低的计算代价实现大规模的预训练。
地位:
- 与其他基于ssm的视觉任务模型相比,Vim是一种纯ssm方法,以序列方式对图像进行建模,是一种更有前途的通用和高效的骨干。
- 由于具有位置感知的双向压缩建模,Vim是第一个基于纯ssm的模型,可以处理密集预测任务。
- 与最令人信服的基于transformer的模型DeiT相比,Vim在ImageNet分类上取得了优越的性能。
- 此外,Vim在高分辨率图像的GPU内存和推理时间方面更有效。
- 在记忆和速度方面的效率使Vim能够直接进行顺序视觉表示学习,而不依赖2D先验(如ViTDet中的2D局部窗口)来进行高分辨率视觉理解任务,同时实现比DeiT更高的精度。
1.4 主要贡献
- 本文提出视觉Mamba (Vim),融合了双向SSM来进行数据依赖的全局视觉上下文建模,以及位置嵌入来进行位置感知的视觉理解。
- Vim具有与ViT相同的建模能力,且仅具有次二次计算时间和线性存储复杂度。在分辨率为12481248的图像上进行批量推理提取特征时,Vim比DeiT快2.8倍,节省了86.8%的GPU内存。
- 在ImageNet分类和密集预测下游任务上进行了广泛的实验。结果表明,与公认的、高度优化的普通视觉Transformer (DeiT)相比,Vim取得了优越的性能。
二、相关工作
2.1 通用视觉主干架构
视觉通用架构的发展:
- 早期:卷积神经网络(ConvNet)是计算机视觉的标准网络设计为各种视觉应用提供了视觉基础模型。随后,提出了多种卷积神经网络架构,以提高性能和效率。
- 开创性的工作Vision Transformer (ViT):直接应用纯Transformer架构。
- PVT:提出了金字塔结构的Transformer
- Swin Transformer:在shift窗口中应用自注意力。
- ConvNeXt:回顾了设计空间,并提出了纯ConvNets,可扩展为ViT及其变体。
- RepLKNet:建议通过扩大现有卷积网络的内核大小来带来改进。
- 随着大规模视觉预训练和多模态应用的激增,vanilla transformer风格的模型重新成为计算机视觉的中心舞台。更大的建模能力、统一的多模态表示、对自监督学习友好等优点使其成为首选架构。
Transformer的挑战:二次复杂度,视觉标记的数量有限。
本文从Mamba中获得灵感,探索在不使用注意力的情况下建立一个基于纯ssm的模型作为通用视觉骨干,同时保留了ViT的顺序、模态无关的建模优点。
2.2 长序列建模的状态空间模型
- Structured State-Space SequenceS4模型:一种新的替代传统CNN和Transformer的模型,能够模拟长距离依赖性。S4模型的一个重要特性是,其计算复杂度随序列长度线性增长,这一点对于长序列数据处理尤为重要。
- S5层:进一步的探索中,提出了S5层,通过引入多输入多输出(MIMO)SSM和高效的并行扫描技术到S4层,以增强模型的处理能力。
- H3层:另一个重要的发展是H3层的设计,该层几乎填补了SSM和Transformer注意力机制在语言模型中的性能差距,展示了SSM在捕获长距离依赖性方面的潜力。
- 门控状态空间层:通过在S4基础上引入更多的门控单元构建了门控状态空间层,以提高模型的表达能力。
- Mamba模型:最近,提出了依赖于数据的SSM层并构建了Mamba模型,这是一个通用的语言模型 backbone,它在处理大规模实际数据时能够超越各种大小的Transformer模型,并且同样享有随序列长度线性增长的计算复杂度。
这段讨论指出,虽然之前的工作要么将SSM应用于特定的视觉应用,要么通过结合SSM与卷积或注意力机制构建混合架构,但与之不同的是,作者构建了一个纯粹基于SSM的模型,旨在作为一个通用的视觉 backbone。这表示Vision Mamba(Vim)模型旨在不依赖于传统注意力机制的情况下,通过利用SSM的优势,提供一个能够高效处理图像和视频中长距离依赖关系的强大工具,这在视觉任务中是非常重要的。
三、方法
视觉曼巴(Vision Mamba, Vim)的目标是将高级状态空间模型(advanced state space model, SSM),即将曼巴引入计算机视觉。
3.1 前置知识
状态空间模型:SSM是一种将一维函数或序列 通过隐藏状态
映射到
的系统。连续系统利用微分方程表示如下:
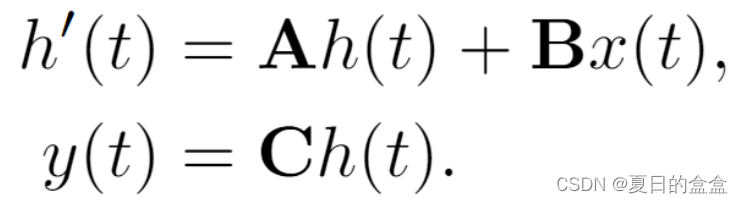
其中:
:演化参数
,
:投影参数
S4 和 Mamba 是连续系统的离散版本,其中包括一个时间尺度参数 Δ 将连续参数 A、B 转换为离散参数、
。常用的变换方法是零阶保持 (ZOH),定义如下:
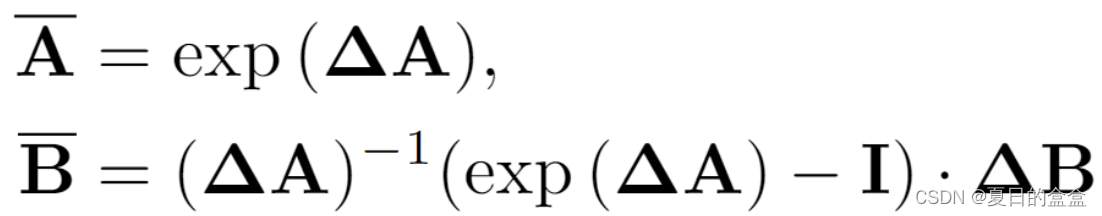
对 A、B进行离散化之后的公式(1)可写成:
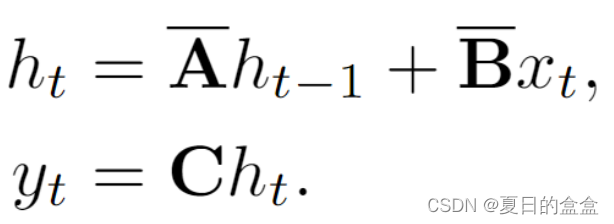
最后,模型通过全局卷积从状态空间模型(SSM)中计算输出:
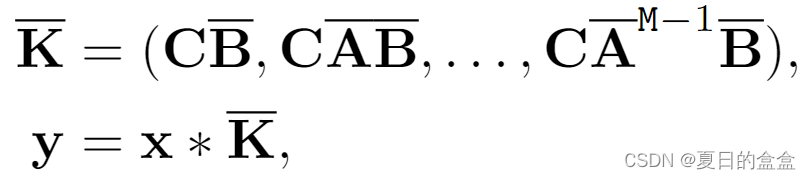
其中:
- M为输入序列x的长度
为结构化卷积核
3.2 ViM
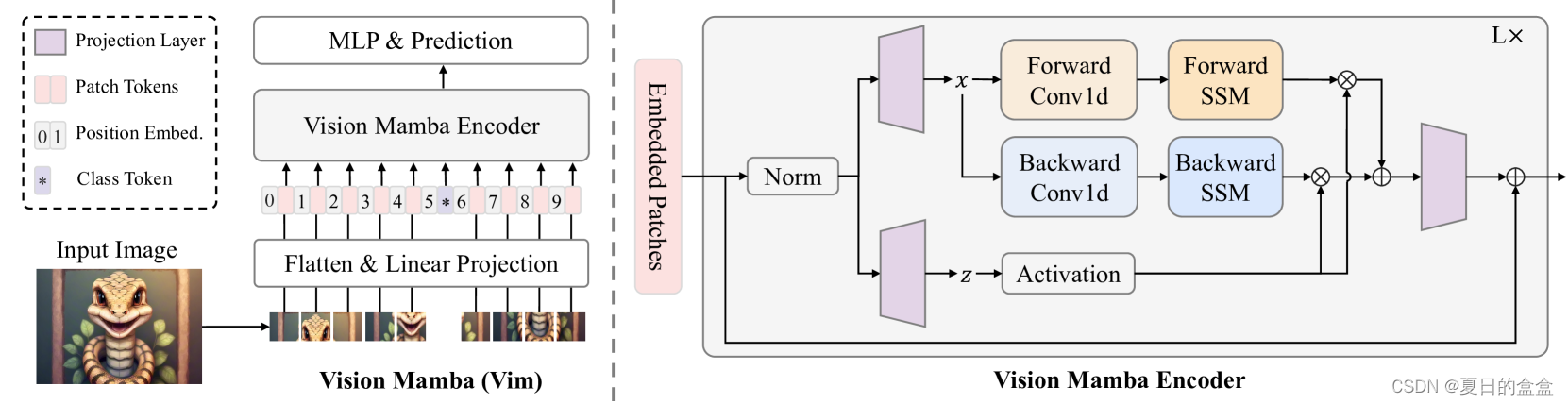
Vim概述如图:
标准的Mamba是为一维序列设计的。为了处理视觉任务,我们首先将二维图像转换为平坦的二维块
。其中(H, W)为输入图像的大小、C为通道数、P为图像补丁的大小、J为补丁数;接下来,我们将
线性投影到大小为D的向量中,并添加位置嵌入
:
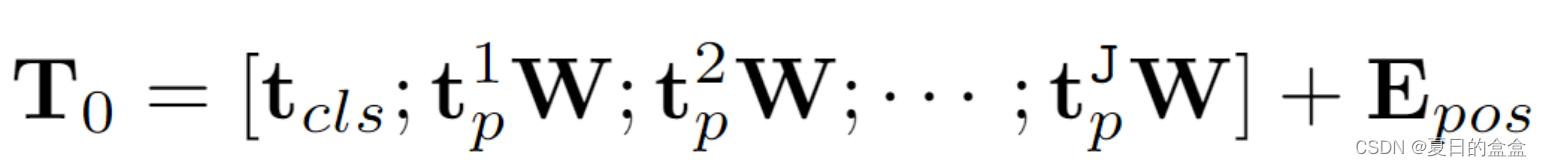
其中:
是 t 的第 j 个补丁
是可学习的投影矩阵
- 受ViT和BERT的启发,使用类标记来表示整个patch序列,记为
然后,我们将令牌序列 发送到 Vim 编码器的第 l 层,得到输出
。最后,我们对输出类标记
进行归一化并将其馈送到多层感知器 (MLP) 头以获得最终预测
,如下所示:

其中:
- Vim 是所提出的视觉 mamba 块
- L 是层数
- Norm 是归一化层
3.3 Vim Block
在本节中,我们介绍Vim模块,它包含了视觉任务的双向序列建模。Vim模块如下图所示。
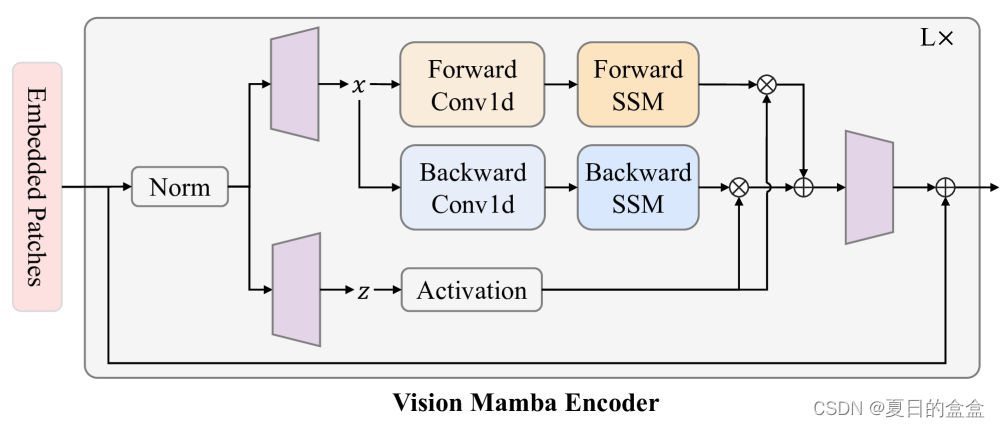
具体算法:

具体来说:
- 将输入token
序列进行归一化
- 将归一化序列线性投影到大小为e的x和z
- 从正向和逆向处理x:
对x应用1-D卷积得到
将线性投影到
、
、∆
利用∆分别对
、
进行线性变化
通过SSM计算向前和向后的y 和
由 z 门控并一起添加以获得输出标记序列
详细解释:

架构图的详细解释:
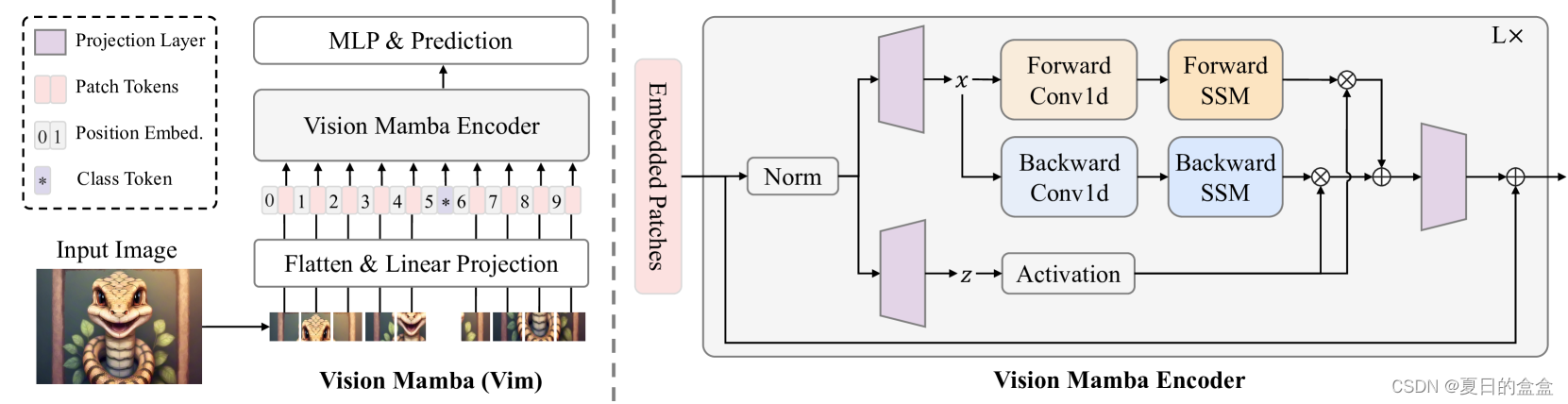

3.4 架构细节
架构的超参数如下:
- L:块的数量
- D:隐藏状态维度
- E:扩展状态维度
- N:SSM维度
遵循ViT和DeiT,首先采用16x16核大小的投影层来获得一个1-D的非重叠块嵌入序列。随后,我们直接堆叠L个Vim块。默认情况下,我们将块数设置为24,SSM维度N设置为16。为了与DeiT系列的模型尺寸一致,我们将微型变体的隐藏状态维度D设置为192,扩展状态维度E设置为384。对于小尺寸版本,我们设置D为384和E为768。















 2621
2621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









