






题目:Unsupervised Multi-Target Domain Adaptation for Acoustic Scene Classification 无监督多目标域自适应声场景分类
地址: http://arxiv.org/abs/2105.10340
源码:https://github.com/yangdongchao/ interspeech2021_MTDA
发表时间 InterSpeech 2021
摘要
众所周知,训练(源)和测试(目标)数据分布之间的不匹配将显著降低声场景分类(ASC)系统的性能。为了解决这一问题,域适应(domain adaptation, DA)是一种解决方案,许多无监督的域适应方法被提出。这些方法侧重于单源域到单目标域的场景。然而,我们将面临测试数据来自多个目标域的问题。这个问题可以通过为每个目标域生成一个模型来解决,但是这个解决方案成本太高。本文提出了一种新的无监督多目标域适应(MTDA)方法,该方法可以同时适应多个目标域,并利用了多个域之间的潜在关系。具体来说,我们的方法将传统的对抗适应与两个新的鉴别器任务相结合,学习所有域共享的公共子空间。此外,我们提出将目标域划分为易于适应域和难以适应域,使系统在训练中更加关注难以适应域。在DCASE 2020 Task 1-A数据集和DCASE 2019 Task 1-B数据集上的实验结果表明,我们提出的方法显著优于之前的无监督DA方法。
1.引言
声场景分类(ASC)是将场景标签(如“有轨电车”,“公园”)分配给音频记录的任务。ASC最近已经被许多深度学习方法所解决[1,2,3,4,5]。然而,当训练音频和测试音频由不同的设备记录时,许多ASC系统往往容易受到域移位(domain shift)的影响。图1显示了不同的记录设备导致数据分布的变化。为了解决记录设备不匹配的问题,人们提出了许多方法,如数据增强[6,7]、频谱校正[8,9]和域自适应(DA)[10]。虽然这些方法获得了良好的性能,但它们同时使用标记的源域和目标域样本进行训练。在本文中,我们研究了无监督域适应(UDA)场景,即在适应过程中目标域的声场景标签是未知的。在计算机视觉领域已经提出了许多UDA方法[11,12,13],但只有少数研究(如[14,15,16,17,18])将UDA技术应用于ASC模型。在[17]中,作者遵循无监督域自适应神经网络[19],并引入它来学习ASC问题的公共子空间。在[16]中,作者遵循最大分类器差异[20],它可以适当地考虑各个类在域内的分布。

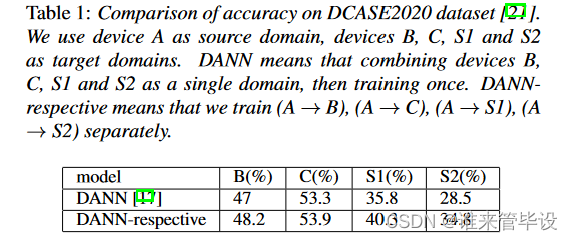
但这些方法都集中在从单源域到单目标域的成对自适应设置上。然而,在现实中,测试数据可能来自多个目标域,例如音频数据由多个设备记录。当测试数据由多个目标域组成时,有两种常见的解决方案。一种是将所有目标域组合为单个目标域[14,15,16,17],然后进行一次成对自适应。另一种是分别对每个目标域进行成对自适应。如表1所示,实验结果表明,将所有目标域合并为单个目标域会降低性能,在第2节中我们也给出了理论证明。尽管我们可以为每个目标域生成一个模型,但是这种方法在目标域数量不断增长的应用程序中变得昂贵且不切实际。此外,应用成对自适应方法可能是次优的,因为它忽略了多个域之间的潜在关系。
本文提出了一种新的无监督多目标域适应(MTDA)方法,该方法可以同时适应多个目标域,并利用了多个域之间的潜在关系。我们的方法基于两个技术点。第一,学习一个由源域和目标域共享的公共子空间,这使得所有域在特征空间中具有相同的数据分布。具体而言,受GAN[22]和DANN[17]的启发,我们利用模块Feature (F)和Discriminator (D)之间的对抗关系,学习特征空间中的域不变特征。与以往的方法[14,17]在二元分类任务中应用D不同,我们在多分类或回归任务中使用D。第二,将目标域划分为易适应域和难适应域。直观地说,如果目标域与源域足够接近,从自身提取的特征往往会导致准确的分类。此外,我们注意到不同的设备引起的域漂移程度不同,域漂移严重的目标域性能较差,难以适应。因此,在培训过程中,我们应该更多地关注这些难以适应的领域。我们的贡献如下:
(1)我们从理论上证明了为什么成对自适应方法在将所有目标域组合为单个域时性能不佳。
(2)我们建议将目标领域分为易适应领域和难适应领域。
(3)提出了一种基于ASC的无监督多目标域自适应方法,较之前的SOTA方法提高了ASC无监督DA的性能。
2.一般方法(原文叫vanilla method!)
在本节中,我们将从理论上说明为什么成对自适应方法在将不同设备数据组合为单个数据时性能欠佳。下面以DANN[17]为例进行说明。
在DANN中,作者提出学习一个编码器E和一个预测器C,这样来自目标和源域的编码z = E(x)的分布(其中x表示音频的梅尔频谱)是对齐的,以便所有场景标签都可以由共享预测器C准确预测。(这一段没太看懂)这是通过E和鉴别器D之间的对抗关系来实现的。D能预测来自源域或目标域的编码z,域标签定义为(表示源域)或
(表示目标域)

其中Ld表示鉴别器D的域分类损失,Ly表示预测器C的场景分类损失,y表示音频的场景,Le表示训练目标函数,它使场景分类损失最小化,同时使领域分类损失最大化。参数用于控制Ly和Ld之间的trade-off.为了简化我们的证明,我们只考虑D和E之间的关系。形式上,DANN用值函数Vd(E, D)进行极大极小优化。
![]()
其中花体E表示数学期望。当E固定时,最优的D如下公式所示:

等式4等价于最小化如下式子:

假设D总是达到最优,式(3)中的极大值优化可以重新表述为使Cd(E)最大,其中

当D达到最优时,固定D然后更新E以最大化Cd(E)。接下来考虑有一个源域和两个目标域的场景。如图2所示,两个样本(a和b)在不同的目标域上,样本a更接近源域,更容易适应。但是当用梯度下降法更新E的参数θ时,我们发现两个样本的梯度都是,因为Ed∼p(d|z)[d]是一个常数,它们的域标签d是一样的。实际上,目标域离源域很远,需要更大的梯度。因此,当将所有目标域组合为一个单一域时,一些难适应域不能很好地适应。
3.提出方法
在本节中,我们形式化了多目标域之间的自适应问题,并描述了我们解决该问题的方法。具体来说,我们将在第3.2节中介绍域距离和域索引,然后在第3.3节和第3.4节中提出两个基于域索引的新的鉴别器任务。
3.1 问题提出
考虑K-class分类的ASC任务。设(X, Y, D) =是M个域(一个标记的源域和M−1个未标记的目标域)的集合(没懂)。xi表示第i个音频,yi表示第i个音频场景标签,
,di表示第i个音频的域标签,
.场景标签yi和领域标签di都是one-hot向量。Yi只用于源样本,di用于所有样本,因为domain label是我们自己生成的。图3显示了所提出的方法的示意图。对于任意xi,使用Feature (F)提取其特征zi, zi = F (xi), Classifier (C)尝试预测场景标签,Discriminator (D)尝试预测领域标签。F旨在将来自不同域的声学特征投射到一个子空间中,该子空间中的特征具有场景辨别性和域不变性。D尝试区分输入音频记录来自哪个域。
3.2 域距离和域索引
域距离 通过分析图1和表1,我们可以发现(1)不同设备引起的domain shift程度不同;(2)目标域的域移越大,目标域获得的性能越差,越难适应,如设备S1和S2。基于这两个事实,我们引入域距离来描述目标域漂移的程度。域距离定义为目标域与源域之间的距离。为了计算域距离,使用并行数据(这意味着这些音频同时记录在同一个环境中,但使用不同的设备)。我们假设并行样本包含相同的声音场景信息,仅因设备特性而不同。为了方便地计算域距离,我们使用t-SNE算法[23]降低音频数据(x)的mel-频谱的维数。我们定义a为降维数据,a = tSN E(x)。然后用公式(7)求区域距离。

其中Distance_i表示第i个目标域到源域的距离。Ai,j表示第i个目标域的第j个数据,a * i,j是平行于Ai,j的源域的数据。N为并行数据数。我们根据目标域的距离对目标域进行排序。如果目标域的排名很高,则很难适应。
域索引 域索引用于量化域距离,表示目标域与源域之间的相对距离。因此,将目标域的排名作为他们的域索引。源域索引设置为0。
3.3 多分类任务
根据以往的方法[14,15,17],很容易考虑让discriminator去做一个多分类的任务。前馈过程总结如式(8)所示。

更新过程采用反向传播算法。对于分类器和鉴别器,损失函数是交叉熵函数。对于Feature,损失函数定义如式(9)所示,其中Ly和Ld分别表示场景分类和领域分类的误差。λd是一个超参数。

以focal loss[24]为灵感,根据域指数对鉴别器的交叉熵函数进行了修正。我们的动机是更加关注难以适应的领域。改进后的损失函数定义如式(10)所示。其中ui表示第i个样本的域索引,N表示数据的数量。Di和′Di分别表示第i个样本的域标签和预测结果。T是一个超参数,在我们的实验中,我们设T = 10。

3.4 回归任务
我们注意到,域索引起着距离度量的作用,即它捕获目标域和源域之间的相似距离。因此,域索引也可以看作域标签,我们考虑让判别器使用基于距离的损失(如L2损失)来回归域索引。前馈过程和更新过程与3.3节中的多分类任务类似,不同之处在于Discriminator只需要预测域索引(记为u), Discriminator的损失函数定义为
4.实验
4.1 数据集和评价指标
Datasets DCASE2019task1B数据集和2020task1A数据集包含10类的48kHz的10s片段。
Evaluation metrics 使用分类准确率作为评价指标,这是音频分类[26]中最常用的指标之一。
4.2 Experiments on DCASE2019 dataset
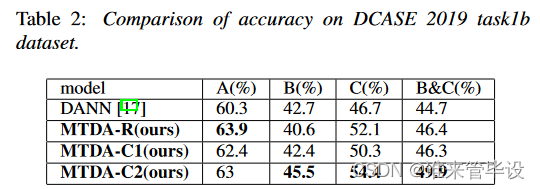
我们的第一个实验在DCASE 2019 task1B上进行评估。在DCASE2019 task1B数据集中,所有数据由设备A、设备B和设备C记录。将设备A的数据作为源域,将设备B和设备C的数据作为两个目标域。为了比较公平,我们使用了与DANN相同的模型结构和实验设置。有关DANN的详细信息,请参阅[17]。表2展示了我们提出的方法和DANN在DCASE 2019 task1B数据集上的性能。我们为MTDA设置了三个不同的实验。MTDA-R表示我们让Discriminator做回归任务。MTDA-C1表示使Discriminator执行多分类任务,并选择交叉熵作为损失函数。MTDA-C2表示损失函数根据式(10)改进。我们的三个实验都优于DANN,这证实了MTDA的有效性。MTDA-C2的性能优于MTDA-C1,说明将目标域分为易适应域和难适应域是非常有用的。
4.3 Experiments on DCASE2020 dataset
我们的第二个实验评估DCASE 2020task1a。在实验中,以设备A的数据为源域,以设备B、C、S1、S2、S3的数据为目标域。此外,我们将设备S4, S5和S6的数据设置为未知域,这些数据仅在测试阶段可用。对于设备A,使用10215段音频进行训练。对于设备B, C, S1-S3,使用750段音频进行适配,这些音频视为未标记的数据。在测试集中,每个设备使用330段音频。
Previous methods 我们将我们的方法与以前最先进的ASC无监督DA方法进行比较,包括DANN [17], UADA [14], W-UADA [15], MCD [16], MMD[27]。为了与这些方法进行比较,我们选择了两个基线模型。一是DCASE模型[28],由8层CNN组成。另一个是Resnet14模型[29]。所有的方法都是基于这两个基线实现的。
Preprocessing 所有原始音频都被重新采样到32kHz,并固定为10s的特定长度。然后对音频信号进行短时傅里叶变换(STFT)计算频谱图,窗口大小为32ms,跳长为15.6ms。在谱图上应用64个MEL滤波器组,然后进行对数运算以提取对数MEL谱图。
Experiment setting 在训练阶段,对于UADA和WUADA,使用RMSProp[30]优化器。对于其他方法,采用Adam算法[31]作为优化器。所有模型的初始学习率为0.002。批大小设置为32,训练epoch为200。λd为{0.2,0.5,1.0,2.0,5.0,8.0,10.0}。在我们的实验中,我们从未使用任何数据增强方法。
Experimental results and analysis 表3和表4展示了我们提出的MTDA和其他SOTA的性能。对于基础模型[28,29],我们只在源数据上训练模型,不使用任何领域自适应。由于采集设备的差异极大地影响了音频信号的特性,没有域自适应的测试数据很难在源域训练的分类器上获得良好的性能。DANN-respective表示我们分别为每个目标域应用DANN。对于方法[27,14,15,17,16],我们将设备B, C, S1-S3的数据合并为一个目标域。虽然DANN和MCD在设备B、C等易适应域上性能较好,但在设备S1-S3等难适应域上性能不佳。相反,我们的方法可以在设备S1-S3上获得更好的性能。我们的方法比dan各自的方法性能更好,这表明MTDA可以更好地利用多个域之间的潜在关系。此外,我们的方法在不可见区域(设备S4-S6)上有更好的性能,这表明我们的方法具有良好的泛化能力。我们注意到,与基线相比,之前的方法[27,14,15,16]无法成功地对源样本(设备A)进行分类。这意味着源域信息的丢失受到自适应过程的影响。虽然我们的方法不能完全克服这个问题,但我们的方法也产生了与基线相当的结果。

Comparison between MTDA-C1 and MTDA-C2 MTDA-C1与MTDA-C2的比较MTDA-C2的精度高于MTDA-C1,这是因为MTDA-C2更关注难以适应的域。
Comparison between MTDA-C and MTDA-R MTDA-C与MTDA-R的比较MTDA-R也得到了较好的性能,验证了Discriminator回归域索引的有效性。MTDA-R可以得到与MTDA-C2相似的结果,这是因为域索引起着距离度量的作用,这意味着通过Discriminator回归域索引也有利于难以适应的域。此外,MTDA-R比MTDA-C在未见域上具有更高的精度。
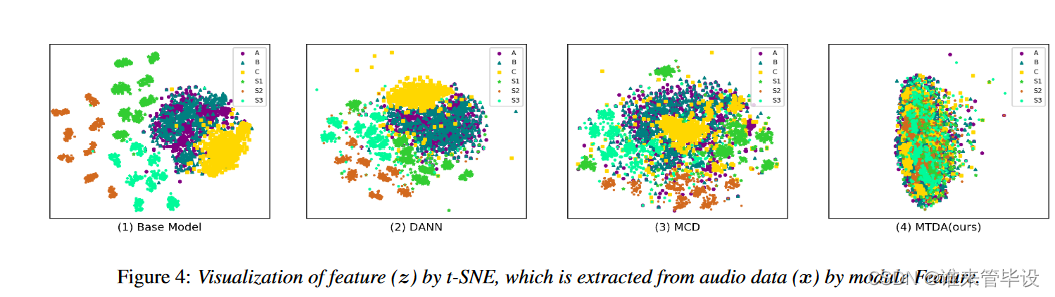
Feature visualization T-SNE[23]用于对不同方法的自适应结果进行可视化。图4 (a)显示了基础模型[28]的结果。图4 (b)和图4 (c)显示了DANN和MCD模型的适应结果,它们可以适应易于适应的领域,如设备b和c,但不能很好地适应难以适应的领域,如设备S1-S3。图4 (d)显示了MTDA-C2的自适应结果。我们可以发现,几乎所有目标域的分布都与源域一致。
5.结论
提出了一种新的多目标域自适应算法(MTDA)。该方法可以同时适应多个目标域,并利用域之间的潜在关系。ASC任务的实验结果和可视化分析验证了该方法的优越性。














 5308
5308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









