






 本文提出了在AudioSet数据集上训练的预训练音频神经网络(PANNs),用于音频模式识别任务,如音频标注、声场景分类等。研究了不同架构的CNN、ResNets和MobileNets,以及数据增强技术如mixup和SpecAugment对性能的影响。PANNs在AudioSet上的平均平均精度达到0.439,优于之前系统,并能成功迁移到其他音频识别任务中。
本文提出了在AudioSet数据集上训练的预训练音频神经网络(PANNs),用于音频模式识别任务,如音频标注、声场景分类等。研究了不同架构的CNN、ResNets和MobileNets,以及数据增强技术如mixup和SpecAugment对性能的影响。PANNs在AudioSet上的平均平均精度达到0.439,优于之前系统,并能成功迁移到其他音频识别任务中。
论文题目:PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition,用于音频模式识别的大规模预训练音频神经网络
论文代码:GitHub - qiuqiangkong/audioset_tagging_cnn
摘要
音频模式识别是机器学习领域的一个重要研究课题,包括音频标注、声场景分类、音乐分类、语音情绪分类和声音事件检测等任务。近年来,神经网络已被应用于解决音频模式识别问题。然而,以前的系统是建立在特定的数据集上的,持续时间有限。最近,在计算机视觉和自然语言处理中,在大规模数据集上预训练的系统已经很好地泛化了一些任务。然而,针对大规模音频模式识别数据集的预训练系统的研究还很有限。在本文中,我们提出了在大规模AudioSet数据集上训练的预训练音频神经网络(pann)。这些pann被转移到其他音频相关任务。我们研究了由各种卷积神经网络建模的pann的性能和计算复杂性。我们提出了一种名为Wavegram-Logmel-CNN的架构,使用log-mel谱图和波形作为输入特征。我们最好的PANN系统在AudioSet标签上实现了最先进的平均平均精度(mAP) 0.439,超过了之前最好的0.392系统。我们将PANNs转移到六个音频模式识别任务中,并在其中几个任务中演示了最先进的性能。
1.引言
音频模式识别是机器学习领域的一个重要研究课题,在我们的生活中扮演着重要的角色。我们被声音所包围,这些声音包含了我们所处的位置以及周围正在发生的事情的丰富信息。音频模式识别包括音频标记[1]、声场景分类[2]、音乐分类[3]、语音情绪分类、声音事件检测[4]等任务。
近年来,音频模式识别引起了越来越多的研究兴趣。早期的音频模式识别工作主要集中在个人研究人员收集的私人数据集上。例如,Woodard[5]运用隐马尔可夫模型(HMM)对木门打开和关闭、金属掉落和倒水的三种声音进行了分类。最近,声场景与事件检测与分类(DCASE)挑战系列[7][8][9][2]已经提供了公开的数据集,如声场景分类和声音事件检测数据集。DCASE挑战吸引了越来越多的研究兴趣在音频模式识别。例如,最近的DCASE 2019挑战在五个子任务[10]中收到了311个条目。
然而,音频模式识别系统在大规模数据集上训练时的表现如何仍然是一个悬而未决的问题。在计算机视觉中,已经用大规模ImageNet数据集[11]建立了多个图像分类系统。在自然语言处理中,利用Wikipedia[12]等大规模文本数据集建立了多种语言模型。然而,在大规模音频数据集上训练的系统更加有限[1][13][14][15]。
音频模式识别的一个里程碑是AudioSet[1]的发布,该数据集包含超过5000小时的音频记录和527个声音类别。AudioSet没有发布原始音频记录,而是发布了从预先训练的卷积神经网络[13]中提取的音频片段的嵌入特征。一些研究人员研究了具有这些嵌入特征的建筑系统[13][16][17][18][19][20]。然而,嵌入特征可能不是音频记录的最佳表示,这可能会限制这些系统的性能。
在本文中,我们提出了使用广泛的神经网络在原始AudioSet录音上训练的预训练音频神经网络(PANNs)。我们展示了几个PANN系统优于以前最先进的音频标记系统。我们还研究了pann的音频标记性能和计算复杂度。我们提出PANNs可以转移到其他音频模式识别任务。之前的研究人员研究了音频标记的迁移学习。例如,[21]中提出了在百万歌曲数据集上预训练的音频标记系统,从预训练的卷积神经网络(cnn)中提取的嵌入特征被用作神经网络或支持向量机(svm)[14][22]等第二阶段分类器的输入。在MagnaTagATune[23]和声学场景[24]数据集上预训练的系统在其他音频标记任务[25][26]上进行微调。这些迁移学习系统主要使用音乐数据集进行训练,并且仅限于比AudioSet更小的数据集。
我们的贡献包括:(1)引入在AudioSet上训练的pann,拥有190万音频剪辑和527个声音类的本体;(2)研究了各种pann的音频标记性能和计算复杂度之间的权衡;(3)提出了一种称为waveogram - logmel - cnn的系统,该系统在AudioSet标记上的平均平均精度(mAP)为0.439,优于之前最先进的mAP 0.392系统和谷歌的mAP 0.314系统;(4)我们表明,PANNs可以转移到其他音频模式识别任务,优于几个最先进的系统;(5)发布了源代码和预训练的PANN模型。
本文的组织结构如下:第二节介绍了各种卷积神经网络的音频标记;第三部分介绍了我们提出的Wavegram-CNN系统;第四部分介绍了我们的数据处理技术,包括AudioSet标签的数据平衡和数据增强;第六节给出实验结果,第七节总结本文的工作。
2.音频标签系统
音频标签是音频模式识别的一项重要任务,其目标是预测音频剪辑中是否存在音频标签。音频标签的早期工作包括使用手动设计的特征作为输入,如音频能量、过零率和梅尔频率倒频谱系数(MFCCs)[27]。生成模型,包括高斯混合模型(GMMs)[28][29],隐马尔可夫模型(hmm)和判别支持向量机(svm)[30]已被用作分类器。最近,基于神经网络的方法,如卷积神经网络(cnn)已被用于预测音频记录的标签。基于cnn的系统在几个DCASE挑战任务中取得了最先进的性能,包括声场景分类[2]和声音事件检测[4]。然而,其中许多作品都专注于具有有限数量的声音类别的特定任务,并没有设计用于识别广泛的声音类别。在本文中,我们专注于在AudioSet[1]上训练大规模的pann来解决一般的音频标记问题。
A.CNNs
(1)Conventional cnn: cnn已成功应用于图像分类等计算机视觉任务。CNN由几个卷积层组成。每个卷积层包含几个与输入特征映射进行卷积的内核,以捕获它们的局部模式。用于音频标记[3][20]的cnn通常使用log mel谱图作为的输入。将短时傅里叶变换(STFTs)应用于时域波形,计算频谱图。然后,将mel滤波器组应用于谱图,然后进行对数运算,提取log mel谱图。
(2)Adapting CNNs for AudioSet tagging:我们使用的pann是基于我们之前为DCASE 2019提出的跨任务CNN系统,在CNN的倒数第二层添加了一个额外的全连接层,以进一步提高表示能力。我们研究了6层、10层和14层的cnn。6层CNN由4个卷积层组成,内核大小为5 × 5,基于AlexNet[34]。10层和14层的cnn分别由4层和6层卷积组成,灵感来自于类vgg的cnn[35]。每个卷积块由2个卷积层组成,核大小为3 × 3。在每个卷积层之间应用批量归一化[36],并使用ReLU来加速和稳定训练。我们对每个卷积块应用2 × 2大小的平均池化进行下采样,因为2 × 2平均池化已被证明优于2 × 2最大池化[33]。
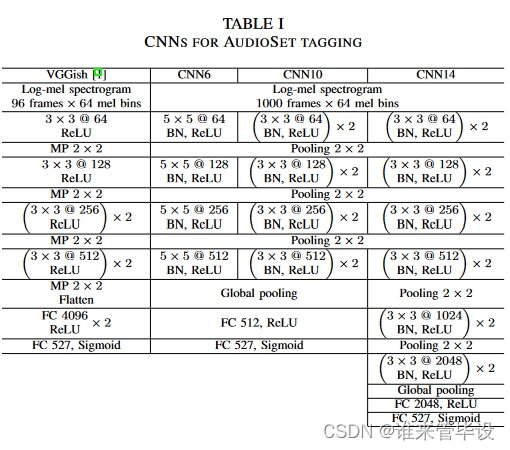
在最后一个卷积层之后应用全局池化,将特征映射总结为固定长度的向量。在[15]中,使用最大和平均操作进行全局池化。为了结合它们的优点,我们将平均向量和最大化向量相加。在我们之前的工作[33]中,这些固定长度向量被用作音频剪辑的嵌入特征。在这项工作中,我们在固定长度向量的基础上增加了一个额外的全连通层来提取嵌入特征,进一步提高了它们的表示能力。对于特定的音频模式识别任务,对嵌入特征应用线性分类器,然后对分类任务使用softmax非线性,对标记任务使用sigmoid非线性。在每次下采样操作和全连接层之后应用Dropout[38],以防止系统过拟合。表一总结了我们提出的CNN系统。符号“@”后面的数字表示特征映射的数量。第一列是[13]提出的VGGish网络。MP是最大池化的缩写。表一中的Pooling 2×2是大小为2×2的平均Pooling。在[13]中,音频片段被分割为1秒的片段,[13]也假设每个片段都继承了音频片段的标签,这可能会导致标签不正确。相比之下,我们的系统从表I的第二列到第四列应用整个音频剪辑进行训练,而不将音频剪辑切割成片段。
我们将音频剪辑的波形表示为xn,其中n是音频剪辑的索引,f (xn)∈[0,1]K是表示K个声音类别存在概率的PANN的输出。xn的标记记为yn∈{0,1}K。二元交叉熵损失函数l用于训练PANN:
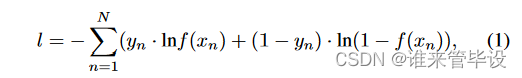
其中N为AudioSet中训练片段的个数。在训练中,利用梯度下降法对f(·)的参数进行优化,使损失函数l最小。
B.ResNets
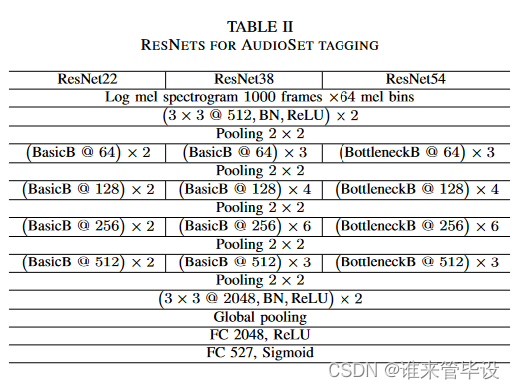
(1)Conventional residual networks:对于音频分类,较深的cnn已被证明比较浅的cnn具有更好的性能。非常深的传统cnn的一个挑战是梯度不能正确地从顶层传播到底层[32]。为了解决这个问题,ResNets[32]在卷积层之间引入了shortcut。这样,向前和向后信号可以直接从一层传播到任何另一层。快捷连接只引入了少量额外的参数和一点额外的计算复杂度。ResNet由几个块组成,每个块由两个卷积层组成,内核大小为3 × 3,输入和输出之间有一个快捷连接。每个瓶颈块由三个具有网中网架构[39]的卷积层组成,可以代替ResNet[32]中的基本块。
(2)Adapting ResNets for AudioSet tagging:我们调整ResNet如下。首先,在log mel谱图上应用了两个卷积层和一个下采样层,以减少输入log mel谱图的大小。我们实现了三种不同深度的ResNet:一个22层的ResNet,有8个基本块;38层ResNet, 16个基本块,54层ResNet, 16个剩余块。表二显示了适用于AudioSet标记的ResNet系统的体系结构。BasicB是基础块的缩写,瓶颈块是瓶颈块的缩写。
C.MobileNets
(1) Conventional MobileNets:当系统在便携式设备上实现时,计算复杂性是一个重要的问题。与CNN和ResNets相比,MobileNets旨在减少CNN中的参数和乘法-加法操作的数量。mobilenet基于深度可分离卷积[40],通过将标准卷积分解为深度卷积和1 × 1点卷积[40]。
(2)Adapting MobileNets for AudioSet tagging:我们将MobileNetV1[40]和MobileNetV2[41]做出的改进表III所示。V1Blocks和V2Blocks是MobileNet卷积块[40][41],每个分别由两个和三个卷积层组成。

D. One-dimensional CNNs
以前的音频标签系统是基于log mel谱图这一人工提取的特征。为了提高性能,一些研究人员提出了建立直接作用于时域波形的一维cnn。例如Dai et al.[31]提出了一维CNN用于声场景分类,Lee et al.[42]提出了一维CNN,后来被Pons et al.[15]用于音乐标签。
(1)DaiNet:DaiNet[31]将长度为80,stride为4的核应用于音频记录的输入波形。kernels在训练中是可学习的。首先,对第一卷积层进行极大值运算,使系统对输入信号的相移具有鲁棒性。然后,利用核大小为3、步幅为4的一维卷积块提取高级特征;一个18层的DaiNet,每个卷积块中有4个卷积层,在UrbanSound8K[43]分类[31]中取得了最好的结果。
(2)LeeNet:与DaiNet在第一层使用大内核不同,LeeNet[42]在波形上使用长度为3的小内核来代替STFT进行谱图提取。LeeNet由几个一维卷积层组成,每个层后面都有一个大小为2的下采样层。最初的LeeNet由11层组成。
(3)Adapting one-dimensional CNNs for AudioSet tagging:我们通过将LeeNet扩展到24层的更深架构来修改它,将每个卷积层替换为由两个卷积层组成的卷积块。为了进一步增加一维cnn的层数,我们提出了一个核小到3的一维残差网络(Res1dNet)。我们将LeeNet中的卷积块替换为残差块,其中每个残差块由两个核大小为3的卷积层组成。卷积块的第一和第二卷积层分别有1和2的扩张,以增加相应残差块的接受野。在每个残差块之后应用下采样。通过使用14和24个残差块,我们分别获得了31层和51层的Res1dNet31和Res1dNet51。
3.WAVEGRAM-CNN系统
之前的一维CNN系统[31][42][15]的性能并没有超过用log mel谱图作为输入训练的系统。以前的时域CNN系统[31][42]的一个特点是,它们不是被设计来捕捉频率信息的,因为一维CNN系统中没有频率轴,所以它们不能捕捉不同音调变化的声音事件的频率模式。
A.Wavegram-CNN systems
在本节中,我们提出了用于AudioSet标记的Wavegram-CNN和Wavegram-Logmel-CNN架构。本文提出的Wavegram-CNN是一种时域音频标记系统。Wavegram(波形图)是我们提出的类似于log mel波谱图的特征,但是使用神经网络学习的。波谱图设计用于学习时频表示,即傅里叶变换的修改。波形图有一个时间轴和一个频率轴。频率模式对于音频模式识别很重要,例如,音调变化不同的声音属于同一类。波形图被设计用来学习一维CNN系统中可能缺乏的频率信息。通过从数据中学习一种新的时频变换,波形图也可以比手工制作的log mel谱图更好。然后,波形图可以取代log mel谱图作为输入特征,从而形成我们的WavegramCNN系统。我们还结合了Wavegram和log mel谱图作为一个新特征来构建Wavegram- logmelcnn系统,如图1所示。
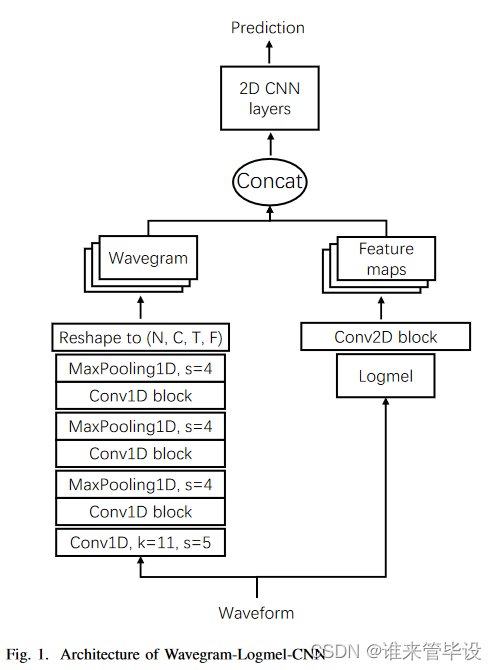
为了构建波形图,我们首先将一维CNN应用于时域波形。一维CNN从一个卷积层开始,滤波长度为11,stride为5,以减少输入的大小。这会立即将输入长度减少到原来的1/5,从而减少内存使用。接下来是三个卷积块,其中每个卷积块由两个卷积层组成,分别膨胀为1和2,旨在增加卷积层的接受场。每个卷积块后面跟着一个步长为4的下采样层。通过使用步幅和三次降采样,我们将一个32 kHz的音频记录降采样到每秒32,000 /5/4/4/4 = 100帧特征。我们将一维CNN层的输出大小表示为T × C,其中T是帧数,C是通道数。通过将C通道分割为C/F组,我们将这个输出重塑为一个大小为T × F × C/F的张量,其中每组都有F个频率箱。我们称这个张量为波图。波形图通过在每个C/F信道中引入F频率箱来学习频率信息。我们应用第二- a节中描述的CNN14作为提取的波谱图的骨干架构,这样我们就可以公平地比较基于波谱图和log mel波谱图的系统。像CNN14这样的二维cnn可以捕获波形图上的时频不变模式,因为核在波形图中沿着时间轴和频率轴进行卷积。
B.Wavegram-Logmel-CNN
此外,我们还可以将波谱图和对数梅尔谱图结合成一种新的表示形式。这样,我们可以同时利用时域波形和对数谱图的信息。组合是沿着通道维度进行的。波形图为音频标记提供了额外的信息,补充了log mel谱图。图1显示了Wavegram-Logmel-CNN的架构。
4.数据处理
在本节中,我们将介绍AudioSet标记的数据处理,包括数据平衡和数据增强。数据平衡是一种在高度不平衡的数据集上训练神经网络的技术。数据增强是一种用于增强数据集的技术,以防止系统在训练期间过拟合。
A. 数据平衡
可用于训练的音频片段的数量因声音类的不同而不同。例如,有超过90万音频片段属于“演讲”和“音乐”类别。另一方面,只有几十个音频片段属于“牙刷”类别。不同声音类别的音频剪辑数量呈长尾分布。训练数据在训练过程中分批输入PANN。如果没有数据平衡策略,音频片段将从AudioSet中统一采样。因此,像“Speech”这样训练片段较多的声音类更容易在训练过程中被采样。在极端情况下,一个迷你批处理中的所有数据可能属于同一个声音类。这将导致PANN对训练片段较多的声音类过拟合,而对训练片段较少的声音类过拟合。为了解决这一问题,我们设计了一种平衡抽样策略来训练pann。也就是说,音频片段从所有声音类别中大致均等地采样,以构成一个小批量。我们使用术语“大约”是因为音频片段可能包含多个标签。
B. 数据增强
数据增强是防止系统过拟合的有效方法。AudioSet中的一些声音类只包含少量(例如,数百个)的训练剪辑,这可能会限制pan的性能。我们应用mixup和SpecAugment来增强训练期间的数据。
(1)mixup:Mixup[44]是一种通过内插数据集中两个音频剪辑的输入和目标来增强数据集的方法。例如,我们将两个音频片段的输入分别表示为x1、x2,将它们的目标分别表示为y1、y2。然后,增广的输入和目标分别由x = λx1 +(1−λ) x2和y = λy1 +(1−λ)y2得到,其中λ采样于Beta分布[44]。默认情况下,我们对logmel谱图应用mixup。我们将在第VI-C4节中比较mixup在对数梅尔谱图和时域波形上的性能。
(2)SpecAugment:针对语音识别问题,提出了SpecAugment[45]算法。SpecAugment使用频率掩蔽和时间掩蔽对音频片段的log mel谱图进行操作。应用频率屏蔽,使f个连续的mel频率区间[f0, f0 +f]被屏蔽,其中f从从0到频率掩码参数f'的均匀分布中选择,f0从[0,F−f]中选择,其中F是mel频率区间的数量[45]。在每个log - mel谱图中可以有多个频率掩码。频率掩码可以提高PANNs对[45]音频片段频率失真的鲁棒性。时间屏蔽类似于频率屏蔽,只是应用于时域。
5.迁移到其他任务
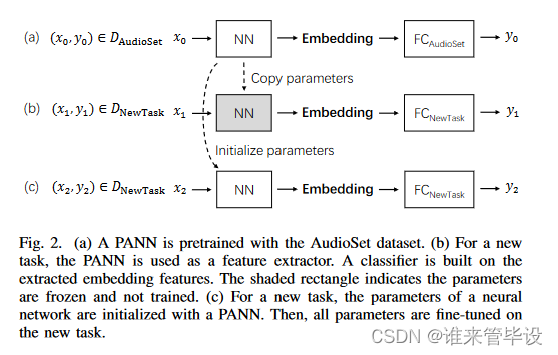
为了研究pann的泛化能力,我们将pann转移到一系列音频模式识别任务中。之前关于音频迁移学习的工作主要集中在音乐标记上,并且仅限于比AudioSet更小的数据集。首先,我们在图2(a)中演示了PANN的训练过程。其中DAudioSet为AudioSet数据集,x0、y0分别为训练输入和目标。FCAudioSet是AudioSet标签的全连接层。在本文中,我们提出比较以下迁移学习策略。
(1)从零开始训练系统。所有参数都随机初始化。系统类似于PANNs,除了最后的全连接层,它取决于任务相关的输出数量。该系统被用作基线系统,与其他迁移学习系统进行比较。
(2)使用PANN作为特征提取器。对于新任务,利用PANN算法计算音频片段的嵌入特征。然后,将嵌入特征用作分类器的输入,例如完全连接的神经网络。在对新任务进行训练时,PANN的参数被冻结,不进行训练。只训练建立在嵌入特征上的分类器参数。如图2(b),其中DNewTask是一个新的任务数据集,FCNewTask是一个新任务的全连接层。PANN被用作特征提取器。基于提取的嵌入特征建立分类器。阴影矩形表示冻结和未训练的参数。
(3)调优PANN。PANN用于新任务,除了最后的全连接层。所有参数都从PANN初始化,除了最后的全连接层是随机初始化的。所有参数都在DNewTask上进行了微调,如图2(c)。
6.实验
首先,我们评估了pann在AudioSet标记上的性能。然后,将pann转移到多个音频模式识别任务中,包括声场景分类、一般音频标记、音乐分类和语音情感分类。
A.AudioSet dataset
AudioSet是一个大型音频数据集,拥有527个声音类。AudioSet的音频片段是从YouTube视频中提取的。训练集由2,063,839个音频片段组成,其中包括一个由2,160个音频片段组成的“平衡子集”,其中每个声音类至少有50个音频片段。评估集由20371段音频片段组成。我们没有使用[1]提供的嵌入功能,而是使用[1]提供的链接在2018年12月下载了AudioSet的原始音频波形,并忽略了不再可下载的音频片段。我们成功下载了1934187个(94%)完整训练集的音频片段,包括20550个(93%)平衡训练集的音频片段。我们成功下载了18,887个评估数据集的音频片段。如果音频片段短于10秒,我们将其填充为10秒,并设置静默。考虑到YouTube上大量的音频片段都是单声道的,采样率较低,我们将所有的音频片段都转换为单声道,并重新采样到32khz。
对于基于log mel谱图的CNN系统,在汉明窗大小为1024[33],hop size为320个样本的波形上应用STFT。这种配置导致每秒100帧。在[33]之后,我们使用64mel滤波器组来计算log mel谱图。mel组的下限和上限截止频率设置为50 Hz和14 kHz,以消除低频噪声和混叠效应。我们使用torchlibrosa1,一个PyTorch实现的librosa[46]函数来构建log mel谱图提取到PANNs中。10秒音频片段的log - mel谱图的形状为1001 × 64。额外的一帧是由计算STFT时应用“中心”参数引起的。批处理大小为32,使用学习率为0.001的Adam[47]优化器进行训练。系统在特斯拉- v100r001 - pcie - 32gb单卡上进行训练。每个系统需要大约3天的时间从头开始训练600 k次迭代。
B.Evaluation metrics
平均平均精度(mAP)、平均曲线下面积(mAUC)和d-prime被用作AudioSet标记[20][1]的官方评估指标。平均精度(AP)是召回率和精度曲线下的面积。AP不依赖于真阴性的数量,因为精度和回忆都不依赖于真阴性的数量。另一方面,AUC是假阳性率和真阳性率(召回率)下的面积,反映了真阴性的影响。d-prime也被用作一个度量,可以直接从AUC[1]计算。所有指标都是在每个班级上计算的,然后在所有班级上平均。这些指标也称为宏观指标。
C. AudioSet tagging results
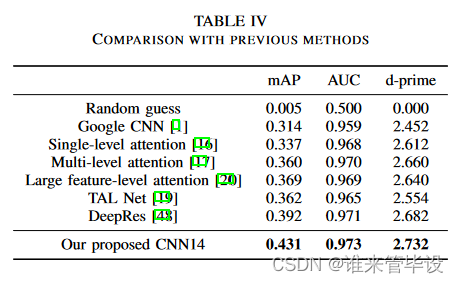
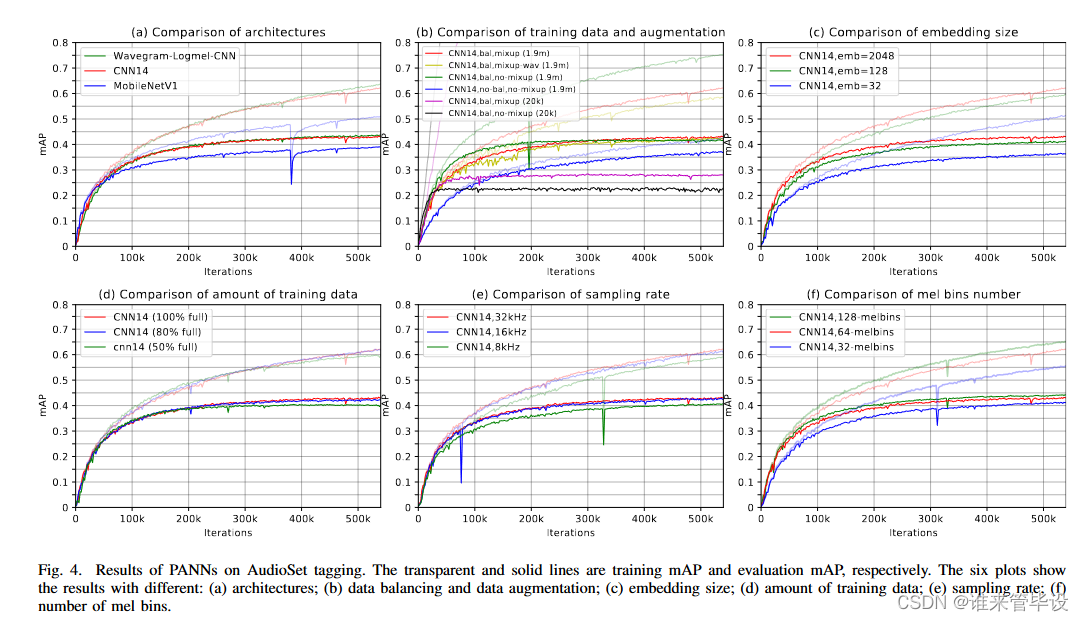
(1)Comparison with previous methods:表IV显示了我们提出的CNN14系统与以前的AudioSet标记系统的比较。我们选择CNN14作为基本模型来研究AudioSet标签的各种超参数配置,因为CNN14是一个标准的CNN,具有简单的架构,并且可以与以前的CNN系统进行比较。作为基线,随机猜测的mAP分别为0.005,AUC为0.500,d-prime为0.000。谷歌用[13]的嵌入特征训练后发布的结果mAP分别为0.314,AUC为0.959。单级注意和多级注意系统[16]、[17]的mAP分别为0.337和0.360,随后通过特征级注意神经网络进行改进,mAP达到0.369。Wang et al.[19]研究了五种不同类型的注意函数,得到的mAP为0.362。上述所有系统都是基于AudioSet[1]发布的嵌入特性构建的。最近的DeepRes系统[48]建立在从YouTube下载的波形上,并实现了0.392的mAP。从表IV的最下面几行可以看出,我们提出的CNN14系统的mAP达到了0.431,超过了以前最好的系统。我们使用CNN14作为骨干来构建Wavegram-Logmel-CNN,以便与CNN14系统进行比较。图4(a)显示,Wavegram-Logmel-CNN的性能优于CNN14系统和MobileNetV1系统。详细结果参看表XI。
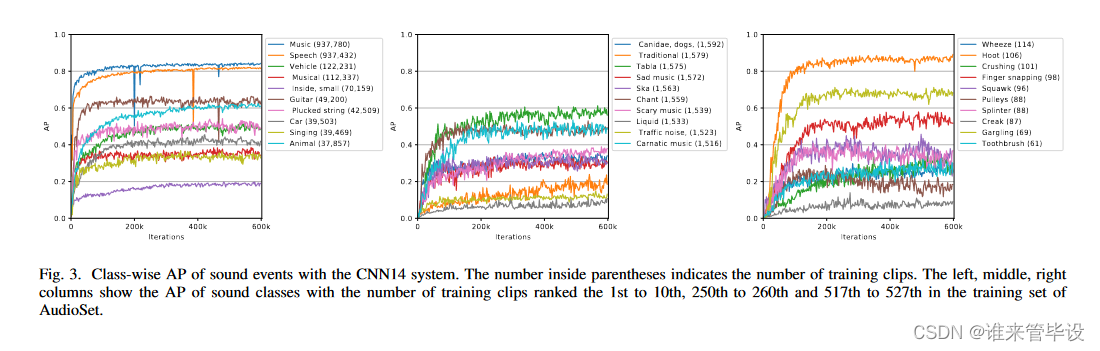
(2)Class-wise performance:图3显示了使用CNN14系统对不同声音类别的分类AP。左、中、右三列显示的是声音类的AP,训练片段数量在AudioSet的训练集中排名第1 ~ 10位,250 ~ 260位,517 ~ 527位。不同声音类别的表现可能非常不同。例如,“音乐”和“语音”的ap达到0.80以上。另一方面,一些声音类,如“Inside, small”,AP仅为0.19。图3显示ap通常与训练片段的数量不相关。例如,左列显示“Inside, small”包含70,159个训练片段,而其AP较低。相比之下,右列显示“Hoot”只有106个训练片段,但达到了0.86的AP,比许多其他声音类的训练片段更多。在本文的最后,我们在图12中绘制了所有527个声音类别的地图,其中显示了CNN14, MobileNetV1和Wavegram-Logmel-CNN系统与[1]发布的具有嵌入特征的之前最先进的音频标记系统[20]的类别比较。图12中的蓝色条形图显示了对数尺度下的训练片段数量。“+”符号表示标签质量在0到1之间,这是由专家[1]验证的正确标记音频片段的百分比衡量。不同声音类别的标签质量不同。−表示无法获得标签质量的声音类。图12显示了一些类别的平均精度比其他类别的高。例如,像“bagpipes”这样的声音类的平均精度为0.90,而像“mouse”这样的声音类的平均精度小于0.2。一种解释是不同声音类的音频标注难度不同。此外,音频标注性能并不总是与训练片段的数量和标注质量[20]相关。图12显示,所提出的系统在广泛的声音类别中优于之前最先进的系统[16],[17]。
(3)Data balancing:IV- a部分介绍用于训练音频集标记系统的数据平衡技术。图4(b)显示了有和没有数据平衡的CNN14系统的性能。蓝色曲线表明,在没有数据平衡的情况下,训练pann需要很长时间。绿色曲线表明,在数据平衡的情况下,系统在有限的训练迭代中收敛更快。此外,用完整的190万个训练片段训练的系统比用20k训练片段的平衡子集训练的系统表现更好。表V显示,CNN14系统在数据均衡情况下的mAP达到0.416,高于未使用数据均衡情况下的mAP(0.375)。
(4)Data augmentation:mixup数据增强在训练PANNs中发挥着重要作用。默认情况下,我们对log mel频谱图应用mixup。图4(b)和表V显示,使用mixup数据增强训练的CNN14系统实现了0.431的mAP,优于未使用mixup数据增强训练的系统(0.416)。当使用仅包含20k训练片段的平衡子集进行训练时,Mixup特别有用,与没有Mixup的训练(0.221)相比,产生0.278的mAP。在使用完整的训练数据进行训练时,在log mel频谱图上mixup实现了0.431的mAP,在时域波形上的mixup性能为0.425。这表明,与时域波形相比,与对数梅尔谱图一起使用mixup效果更好。
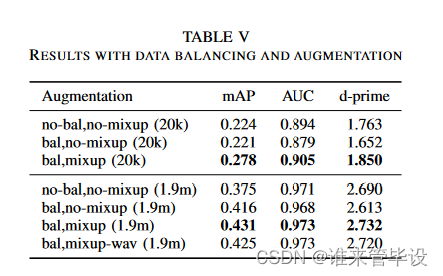
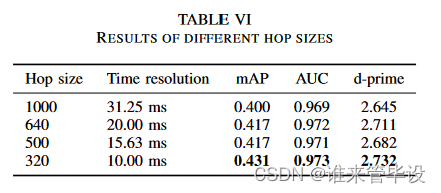
(5)hop sizes:hop sizes是相邻帧之间的样本数量。较小的hop sizes会导致较高的时域分辨率。本文用CNN14系统研究了不同跳数对音频集标注的影响。本文研究了1000、640、500和320的hop sizes:这些对应于相邻帧之间的时域分辨率分别为31.25 ms、20.00 ms、15.63 ms和10.00 ms。表VI显示,mAP得分随着hop sizes的减少而增加。当hop sizes为320时,CNN14系统实现了0.431的mAP,超过了hop sizes为500、640和1000时的mAP。
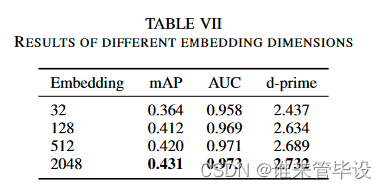
(6)Embedding dimensions:嵌入特征是总结音频片段的定长向量。默认情况下,CNN14的嵌入特征维度为2048。本文研究了嵌入维度为32、128、512和2048的一系列CNN14系统。图4(c)和表VII显示,随着嵌入维度的增加,mAP性能也会增加。
(7)Training with partial data:AudioSet的音频剪辑来自YouTube。同样的音频片段不再可以下载,其他的可能在未来被删除。为了更好地重现未来的工作,研究了用随机选择的部分数据(从下载数据的50%到100%)训练的系统的性能。图4(d)和表VIII显示,当CNN14系统用80%的全数据训练时,mAP略有下降,从0.431下降到0.426(下降了1.2%),当用50%的全数据训练时,mAP下降到0.406(下降了5.8%)。这一结果表明,训练数据量对训练PANNs的重要性。

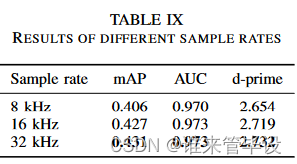
(8)sample rate:图4(e)和表IX显示了在不同采样率下训练的CNN14系统的性能。用16 kHz音频录音训练的CNN14系统的mAP达到0.427,与用32 kHz采样率训练的CNN14系统相似(在1.0%以内)。另一方面,用8 kHz音频录音训练的CNN14系统的mAP值较低,为0.406(低5.8%)。这表明4千赫- 8千赫范围内的信息对于音频标记是有用的。
(9)mel bins:图4(f)和表X显示了使用不同mel bin数量训练的CNN14系统的性能。使用32mel bins时,系统的mAP值为0.413,而使用64mel bins时为0.431,使用128mel bins时为0.442。这一结果表明,尽管计算复杂度随mel bin的数量线性增加,但使用更多mel bin的PANNs可以获得更好的性能。在整个本文中,我们采用64 mel bins提取log mel谱图,作为计算复杂度和系统性能之间的权衡。
(10)Number of CNN layers:我们研究了6层、10层和14层CNN系统的性能,如第II-A节所述。这一结果表明,具有较深CNN架构的pann比较浅CNN架构的性能更好。这一结果与之前在较小数据集上训练的音频标记系统形成对比,其中较浅的CNN(如9层CNN)比较深的CNN[33]表现得更好。一个可能的解释是,较小的数据集可能会受到过拟合的影响,而AudioSet足够大,可以训练更深层的cnn,至少可以达到我们研究的14层cnn。
(11)ResNets:我们应用ResNets来研究更深层次的pann的性能。ResNet38的mAP值为0.434,略优于其他系统。ResNet54的mAP值为0.429,这并没有进一步提高性能。
(12)MobileNets:上述系统表明,pann在AudioSet标记中取得了良好的性能。然而,这些系统在便携式设备上实现时没有考虑计算效率。我们将研究用第II-C节中描述的轻量级mobilenet构建pann。MobileNetV1系统的乘法和加法(multi- added)次数和参数分别仅为CNN14系统的8.6%和5.9%。MobileNetV2系统的mAP值为0.383,比CNN14低11.1%,计算效率比MobileNetV1更高,其中多添加和参数的数量仅为CNN14系统的6.7%和5.0%。
(13)One-dimensional CNNs:表XI显示了One-dimensional CNNs的性能。18层的DaiNet[31]的mAP值为0.295。11层的LeeNet11[42]的mAP值为0.266。我们改进的24层LeeNet将LeeNet11的mAP提高到0.336。我们提出的Res1dNet31和Res1dNet51在Section II-D3中分别实现了0.365和0.355的map,在一维CNN系统中达到了state-of-the-art性能。
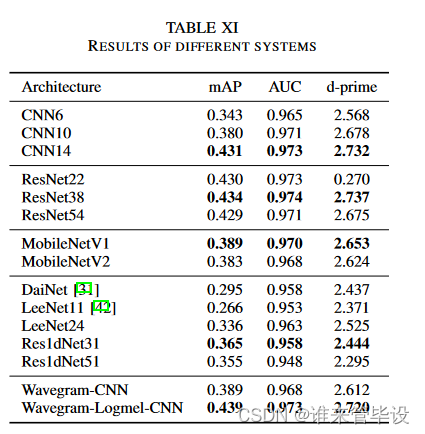
(14)Wavegram-Logmel-CNN:表XI底部显示了我们提出的Wavegram-CNN和Wavegram-Logmel-CNN系统的结果。Wavegram CNN系统的mAP为0.389,优于之前最好的一维CNN系统(Res1dNet31)。这表明Wavegram是一种有效的学习特征。此外,我们提出的Wavegram-Logmel-CNN系统在所有PANN中实现了0.439的SOTA的mAP。
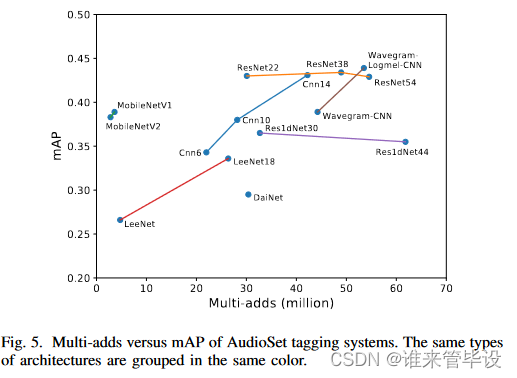
(15)Complexity analysis:我们分析了用于推理的PANN的计算复杂度。乘加运算量和参数量是复杂度分析的两个重要因素。表XII的中间列显示了用于推断10秒音频片段的乘加运算量。表十二的右栏显示了不同系统的参数量。CNN14系统的乘加运算量和参数分别为42.2×10^9和80.8 million,比CNN6和CNN10系统大。ResNets22和ResNet38系统的乘加运算量略少于CNN14系统。ResNet54系统包含最多的乘加运算量,为54.6×10^9。一维神经网络具有与二维神经网络有相似的计算成本。性能最好的一维系统Res1dNet31包含32.7×10^9个乘加运算和80.5 million参数。我们提出的Wavegram CNN系统包含44.2×109乘加运算和81.0 million个参数,与CNN14类似。Wavegram Logmel-CNN系统将乘加运算量略微增加到53.5×10^9,参数数量达到81.1million,与CNN14类似。为了减少乘加运算量和参数量,应用了MobileNets。MobileNetV1和MobileNetV2系统是轻量级神经网络,只有3.6×10^9和2.8×10^9的乘加运算,参数分别约为4.8 million和4.1 million。移动网络降低了计算成本和系统规模。图5总结了mAP与不同PANN的乘加运算的对比。相同类型的系统由相同颜色的线连接。mAP从下到上递增。右上角是我们提出的Wavegram Logmel CNN系统,该系统可实现最佳mAP。左上角是MobileNetV1和MobileNetV2,它们是计算效率最高的系统。
D.Transfer to other tasks
(只看DCASE相关)
在本节中,我们将研究PANN在一系列其他模式识别任务中的应用。对于只提供有限数量的训练片段的任务,PANN可以用于少样本学习。少样本学习是音频模式识别中的一个重要研究课题,因为收集标记数据可能很耗时。我们使用第五节中描述的方法将PANN转移到其他音频模式识别任务中。首先,我们将所有音频记录重新采样到32 kHz,并将其转换为单声道,以与在AudioSet上训练的PANN一致。我们为每项任务执行第五节中描述的以下策略:1)从头开始训练系统;2) 使用PANN作为特征提取器;3) 微调PANN。当使用PANN作为特征提取器时,我们在具有一个和三个完全连接层的嵌入特征上构建分类器,并分别称它们为“Freeze+1层”(Freeze_L1)和“Freeze+3层”(Freeze_L3)。我们采用CNN14系统进行迁移学习,以提供与其他基于CNN的音频模式识别系统的公平比较。我们还研究了在训练其他音频模式识别任务时,用不同次数的样本训练的PANN的性能。
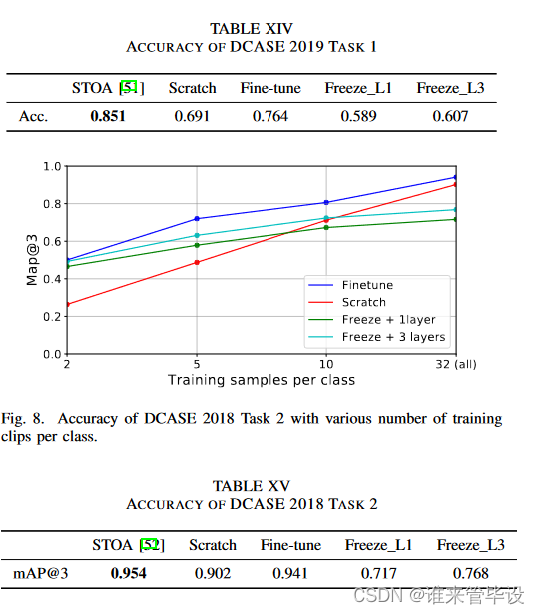
(2)DCASE 2019 Task 1:我们通过对立体声声道进行平均,将立体声录音转换为单声道。从头开始训练的CNN14实现了0.691的精度,而微调系统实现了0.764的精度。Freeze_L1和Freeze_L3分别达到0.689和0.607的精度,并且没有超过从头开始训练的CNN14。这种表现不佳的一个可能解释是,声场景分类的录音具有不同的AudioSet分布。因此,使用PANN作为特征提取器并不能胜过从零开始微调或训练系统。经过微调的系统比从头开始训练的系统获得了更好的性能。图7显示了每个类具有不同数量的训练片段的系统的分类精度。表十四显示了总体性能。Chen等人[51]的SOTA系统使用各种分类器和立体声记录的组合作为输入,实现了0.851的精度,而我们不使用任何集成方法和立体声记录。
(3)DCASE 2018 Task 2:在训练中,我们将录音片段分成4秒的音频片段。在推断中,我们对这些片段的预测进行平均,以获得音频记录的预测。表十五显示,Jeong和Lim[52]提出的最佳先前方法实现了mAP@3使用几个系统的集合,为0.954。相比之下,我们从头开始训练的CNN14系统的准确度达到了0.902。微调后的CNN14系统实现了mAP@3为0.941。Freeze_L1和Freeze_L3系统分别实现了0.717和0.768的精度。图8显示了mAP@3具有不同数量的训练剪辑。微调后的CNN14系统优于从头开始训练的系统和使用PANN作为特征提取器的系统。微调后的CNN14系统取得了与最先进的系统相当的结果。
E. Discussion
在本文中,我们研究了用于AudioSet标记的各种PANN。我们提出的几个PANN的性能优于以前最先进的AudioSet标记系统,包括CNN14的mAP为0.431,ResNet38的mAP达到0.434,优于谷歌0.314的基线。MobileNets是轻量级系统,具有较少的多次添加和参数数量。MobileNetV1的mAP达到0.389。我们的自适应一维系统Res1dNet31实现了0.365的mAP,优于之前的一维CNN,包括0.295的DaiNet[31]和0.266的LeeNet11[42]。我们提出的Wavegram Logmel-CNN系统在所有PANN中实现了0.439的最高mAP。PANN可以用作新的音频模式识别任务的预训练模型。
在AudioSet数据集上训练的PANN被转移到六个音频模式识别任务中。我们表明,经过微调的PANN在ESC-50、MSOS和RAVDESS分类任务中实现了最先进的性能,并在DCASE 2018任务2和GTZAN分类任务中接近了最先进性能。在PANN系统中,微调后的PANN在新任务上总是优于从头开始训练的PANN。实验表明,在训练数据数量有限的情况下,PANN已经成功地推广到其他音频模式识别任务。
7.结论
我们提出了在AudioSet上训练的用于音频模式识别的预训练音频神经网络(PANNs)。研究了广泛的神经网络来构建PANNs。我们提出了从波形中学习的Wavegram特征,以及在AudioSet标记中实现最先进性能的Wavegram- logmel - cnn,存档mAP为0.439。我们还研究了pann的计算复杂度。我们表明,PANNs可以转移到广泛的音频模式识别任务,并优于以前的几个最先进的系统。在对新任务的少量数据进行微调时,PANNs可能很有用。在未来,我们将把PANNs扩展到更多的音频模式识别任务。

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









