






论文:Micro-YOLO: Exploring Efficient Methods to Compress CNN based Object Detection Model 基于CNN的目标检测模型压缩方法探究
论文地址:https://www.scitepress.org/Papers/2021/102344/102344.pdf
DOI: 10.5220/0010234401510158
发表时间:2021,ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
注:大部分是原文,但不全是,带色的是自己的理解
摘要
深度学习模型在目标检测性能方面取得了重大突破。然而,在传统模型如Faster R-CNN和YOLO中,由于计算资源有限和电力预算紧张,这些网络规模太大而很难部署在嵌入式移动设备上。为此,我们提出了一种新的基于CNN的轻量级目标检测模型——基于YOLOv3-Tiny的Micro-YOLO,该模型在保持检测性能的同时,显著降低了参数量和计算成本。我们提出用深度可分离卷积(DSConv)和挤压激励块移动反向瓶颈卷积(MBConv,机翻中文很诡异)替代YOLOv3-tiny网络中的卷积层,并设计了一种渐进式通道剪枝算法,以最小化参数量并最大化检测性能。与原始的YOLOv3-tiny相比,Micro-YOLO网络将参数数量减少了3.46倍,将乘法-累积操作(MAC)减少了2.55倍,在COCO数据集上的mAP只降低了0.7%。
1. 引言
深度学习领域的加速增长极大地促进了目标检测的发展,其在人脸检测、自动驾驶、机器人视觉和视频监控等方面的广泛应用。随着目标检测技术的蓬勃发展,近年来提出了几种深度卷积神经网络模型,如R-CNN, SSD,YOLO。然而,随着网络越来越复杂,这些模型的规模不断增加,在现实生活中将这些模型部署在嵌入式设备上越来越困难。因此,开发一种高效、快速的目标检测模型,在不影响目标检测质量的前提下减小参数大小显得至关重要。(老cliche了,总之是把已有技术(剪枝)应用到新领域(目标检测),也是一种写文章的方向)
物体检测的目标是在数字图像中检测出某一类物体(如人、动物或汽车)。最著名的目标检测网络之一是“You Only Look Once”(YOLO)架构。经过多年的改进,YOLO已经发展到第四代YOLOv4架构。在Tesla V100上,以每秒65帧(FPS)的实时速度,MS COCO数据集的平均精度(AP)达到43.5% (65.7% AP50) 。然而,它包含超过6000万个参数,在处理一张图像时需要执行超过1070亿次浮点数乘法。此外,还提出了YOLOv3(即YOLOv4的上一个版本)的更快版本,YOLOv3-tiny,其参数和乘法要求分别减少了7.5倍和13倍。新模型在Titan x上已实现了33.1%的mAP和220FPS(每秒传输帧数)。然而,在嵌入式设备上部署该模型仍然具有挑战性。
在这项工作中,我们提出了一种基于YOLOv3-tiny架构的目标检测模型的轻量级版本Micro-YOLO。我们提出了三种有效的方法来优化Micro-YOLO架构。主要工作成果如下:
(1)我们提出用深度可分离卷积(DSConv)和挤压激励块移动反向瓶颈卷积(MBConv)取代YOLOv3-tiny网络中的标准卷积层(Conv),在轻微降低检测精度的情况下降低权重参数。
(2)我们探索并确定了MBConv中的最佳卷积核大小,在Micro-YOLO架构上实现权重参数和检测精度之间的最佳权衡。(这个看起来很棒!)
(3)我们提出了一种渐进式剪枝算法,在DSConv和MBConv层上执行粗粒度剪枝,这进一步降低了权重参数,略微降低了检测精度。剪枝后,我们进一步将尺寸减小到1.92M参数量,计算量降低到0.87GMAC, mAP损失为3.1%。(剪枝,我关注的主要部分)
本文的其余部分组织如下。第2节提供了对最新模型压缩技术及其评估方法和问题陈述的理解。第3节详细介绍了我们提出的Micro-YOLO网络及其模型压缩方法。第4节讨论了实验装置和实验结果,并与现有研究成果进行比较。第5节中总结了我们的工作。
2. 前序工作
2.1. 目标检测网络的模型压缩技术
随着目标检测网络家族的复杂化,降低权值参数和计算成本显得尤为重要。模型压缩方法可分为低秩因子分解、知识蒸馏、剪枝和量化,其中剪枝已被证明是通过去除冗余参数来降低网络复杂性的有效方法。为了解决目标检测网络问题,有几种SOTA方法来减少YOLO体系结构中的参数量。(Huang等人,2018)开发了YOLO-lite网络,从YOLOv2-tiny中去除批量归一化层,以加快目标检测。该网络在PASCAL VOC 2007和COCO数据集上的mAP分别达到了33.81%和12.26%。(Wong et al., 2019)创建了一个高度紧凑的网络YOLO-nano,这是一个基于YOLO网络的8位量化模型,并在PASCAL VOC 2007数据集上进行了优化。该网络在PASCAL VOC 2007数据集上实现了3.18M的模型尺寸和69.1%的mAP。(可能因为作者就要做YOLO而且YOLO也是目标检测主力军,所以只关注YOLO这一体系)
2.2. 评价方法(没怎么在别的文献见过但其实很有说明意义的小部分)
我们从模型大小、计算成本和在COCO数据集上的精度性能三个方面评估了目标检测网络的有效性。(提前说明评价指标和应用数据集,这个好,虽然可能是用来填充文章的,但比较有意义)
定义1:模型大小(model size) 模型大小定义为神经网络中参数的数量,即每一层中可训练元素(可训练元素!trainable parameters!)的总和。它的表述如下:

其中表示第i层中可训练元素的个数,N表示神经网络的总层数。(倒也不用解释得这么仔细)
定义2:计算成本(computation cost) 我们将计算成本定义为乘法累加操作(mac)的数量,它是计算两个数字的乘积并将该乘积添加到累加器的操作单元的计数。(哦!我一直以为是乘法和加法)
定义3:平均精度的均值(mAP) 物体检测最常用的评价方法是“平均精度”(AP),它定义为不同召回率下的平均检测精度。精确度衡量的是模型预测的准确性。召回率衡量的是模型对所有积极因素的发现程度。mAP (mean average precision)是AP的平均值。对于COCO数据集,我们评估了80个类别的mAP。
2.3. 问题范式
根据上述定义,问题陈述如下:
[目标检测问题的模型压缩]
给定一个目标检测神经网络模型,目标是在保持网络mAP的同时,在模型上利用有效的压缩方案来实现较小的模型大小和计算成本。
(非要另起一部分来说吗……)
3. 方法
如图1所示,我们在YOLOv3-tiny网络上提出了三种方法,并得到了一个轻量级的网络,命名为Micro-YOLO:(1)为了减少YOLO网络中的卷积网络块,我们提出用两种卷积块取代标准卷积(Conv)层:(a) MobileNetv1中使用的深度可分离卷积(DSConv) 和(b) MobileNetv3中使用的具有挤压和激励块的移动反向瓶颈卷积(MBConv);(2)我们探索并确定MBConv中的最优核尺寸,以实现网络上权值参数和检测精度之间的最佳权衡;(3)我们提出了一种渐进结构化剪枝方法来进一步缩小模型尺寸。(同样的话又重复一遍)

3.1. MobileNets Block-based Network 基于块的MobileNet网络结构
为了减小网络大小,我们探索了轻量级卷积层来取代YOLO网络中的卷积层Conv。MobileNet中使用了两个轻量级卷积层——深度可分离卷积(DSConv)层和带挤压和激励块的可移动反向瓶颈卷积(MBConv)层。如图2(a)所示,DSConv层执行两种类型的卷积:深度卷积和点卷积,这可以显著降低模型大小和计算成本。如图2(b)所示,MBConv的结构是1×1信道展开卷积(英文是channel expansion convolution,不知道是什么),后接深度卷积和1×1信道约简层(英文是channel reduction layer,不知道是什么)。它利用了挤压和激励块——由深度卷积和通道约简层之间的挤压阶段的全局平均池化操作和激励阶段的两个小FC层(Hu et al., 2019)组成的分支(文字表述很麻烦,直接看网络结构就好)。由于输出通道数和输入通道数不相等,我们删除MBConv中的剩余连接(?这么粗暴?)。MBConv层在输入和输出处提供了紧凑表示,同时将输入扩展到内部的高维特征空间,以增加非线性转换的表现力。因此,与DSconv层相比,MBconv层提供了一个更好的压缩网络,而不会降低检测精度。
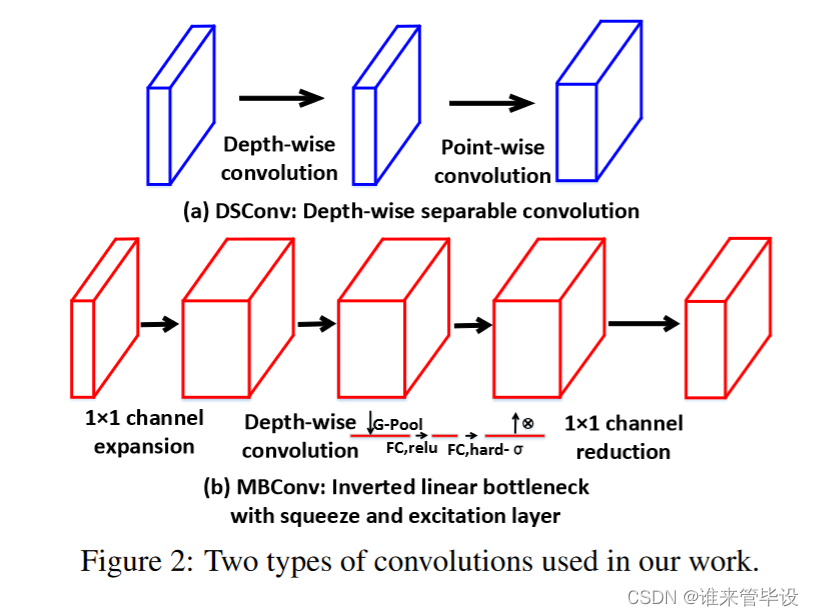
为了评估这些层之间的模型大小,可以分别用(2)(3)(4)式计算Conv (Ns)、DSConv (Nds)和MBConv (Nmb)中的参数量。

式中k为核大小,Cin为输入通道数,Cout为输出通道数,α和β分别为MBConv中的扩张因子和缩减因子。
这些层——即Conv层(Cs), DSConv层(Cds)和MBConv层(Cmb)——之间的计算成本可以分别用(5)(6)(7)表示。

其中k为核大小,Cin为输入通道数,Cout为输出通道数,W和H为特征图的宽度和高度,α和β分别为MBConv中的扩展因子和缩减因子。
3.2. Kernel Size Exploration 卷积核大小探究
为了在不影响精度的情况下进一步减少卷积层的权重参数,我们提出了一种内核大小优化技术。传统的卷积神经网络设计大多使用3×3卷积核。YOLOv3tiny网络在Conv层中也使用了3×3的卷积核大小。然而,网络架构搜索算法(NAS)的出现改变了这种情况。例如,(Cai et al., 2019)强调,前几个卷积层适宜用较小的内核,而深度卷积层适宜用较大的内核。此外,最近关于网络探索的工作也证明了类似的结果,即多个内核大小的组合可以带来更好的检测精度。因此,有必要探索使用不同卷积核大小与我们提出的Micro-YOLO网络mAP之间的优化空间。实验细节将在第4节讨论。
3.3. Progressive Channel Pruning 渐进式通道剪枝
在确定Micro-YOLO网络架构后,我们可以通过剪枝进一步降低权重参数。我们采用了粗粒度修剪,因为DSConv和MBConv层主要由1×1内核大小组成,这为细粒度修剪留下了很小的应用空间。(Liu et al., 2019)指出,剪枝后的结构本身,而不是一组继承的“重要”权重,对最终模型的效率更为关键,这表明在某些情况下,剪枝可以作为一种有效的结构搜索范式。因此,我们提出了一种渐进式剪枝方法,在改良后网络中搜索“更小”的结构。渐进式通道剪枝算法的细节如算法1所示。我们首先训练原始网络,并在剪枝前评估(行2-3)。记录当前剪枝的卷积层通道数量
(行4)。在修剪卷积层i时,每次将输出通道数量减少1/16,因为这一步平衡剪枝率和准确性(怎么平衡的不是很明白,因为每次都减少1/16吗?)。注意,当对第i层的输出通道进行修剪时,也需要对第i+1层对应的输入通道进行修剪。然后更新卷积层i的通道数,初始化剪枝后的新网络(行6-8)。重训练20个epoch来评估新的
(行9-11)。重复第i层的剪枝过程,直到
比
差0.5%,因为我们的实验表明阈值为0.5%(哇,这个阈值不知道怎么试验出来的),可以确保通道剪枝不会严重降低检测精度(行12)。然后,修剪下一个卷积层,直到所有的卷积层都被剪枝,返回剪枝后的网络。

4. 实验结果
我们使用Python语言和Pytorch库在2.50GHz 12核Xeon Intel Linux机器(128GB内存和2个Nvidia GTX 2080Ti显卡)上实现和评估了我们的Micro-YOLO网络。(说明好详实啊,写论文也要这样写)
4.1. Micro-YOLO 网络优化
在我们的Micro-YOLO网络中,每层卷积类型的选择和卷积核大小对检测精度有很大的影响。因此,我们通过实验来确定Micro-YOLO网络的架构。
4.1.1. 卷积类型的选择
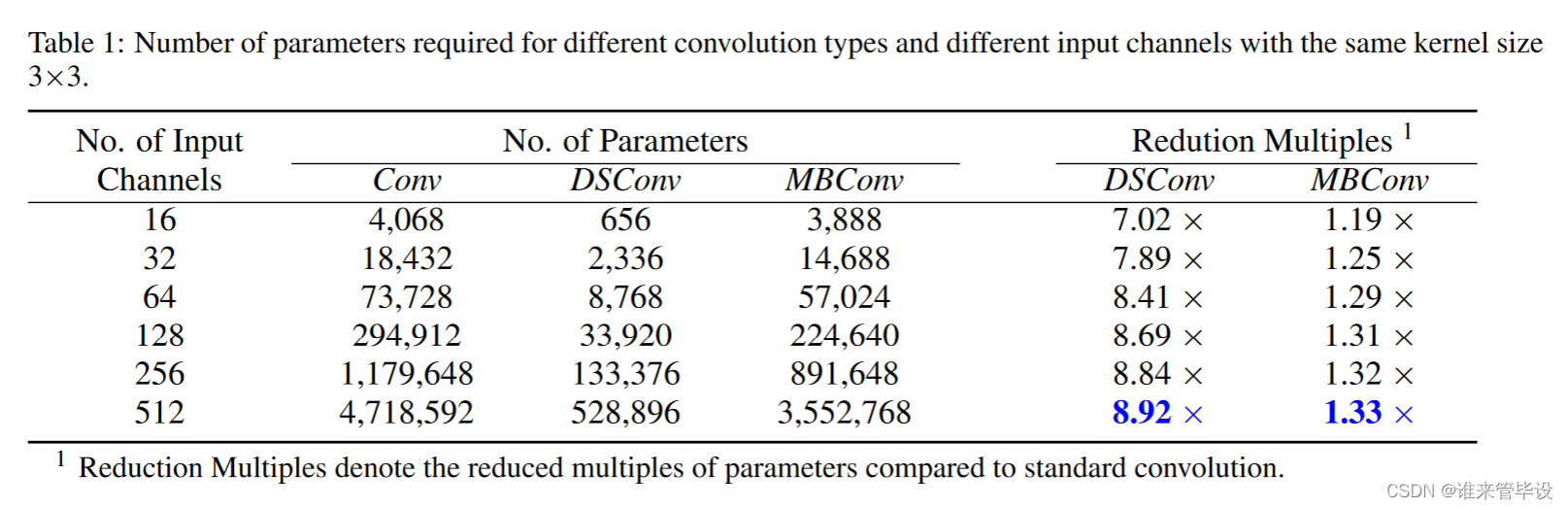
如3.1节所述,Conv层、DSConv层和MBConv层的参数数量存在很大差异。如表1所示,我们根据(2)-(7)计算不同层类型、相同内核大小的不同输入通道所需的参数量。注意,输出通道的数量是输入通道数量的两倍(还没仔细看,应该是网络结构特色)。如表的最后两列所示,MBConv和DSConv层使用的参数数量明显小于Conv层。
为了理解不同卷积类型对模型大小、计算成本和mAP的影响,我们用我们提出的策略替换YOLOv3-tiny的Conv。

表2给出了在COCO数据集上评估由不同卷积类型组成的网络的模型大小、计算成本和mAP。如表所示,只有DSConv层的网络比只有MBConv层的网络具有更小的模型大小和计算成本。然而,使用MBConv层更有效地维护mAP,而DSConv可以应用来减少参数的数量。因此,有必要在网络的模型大小和mAP之间选择一个最优的平衡点(实验中好像没体现出怎么找的)。如表1和表2所示,输入通道和卷积层数的增加导致模型大小的增加。例如YOLOv3-tiny模型中,第10层、第12层和第14层的总权重参数为6.63M,占整个网络的74.95%。我们在第12层中使用DSConv,在其余层中使用MBConv,因为第12层包含最多的参数。这导致模型尺寸减小3.46倍,而mAP仅退化1.7%。因此,我们提出的MicroYOLO网络的最终形式如图3所示。

4.1.2. 卷积核大小探究
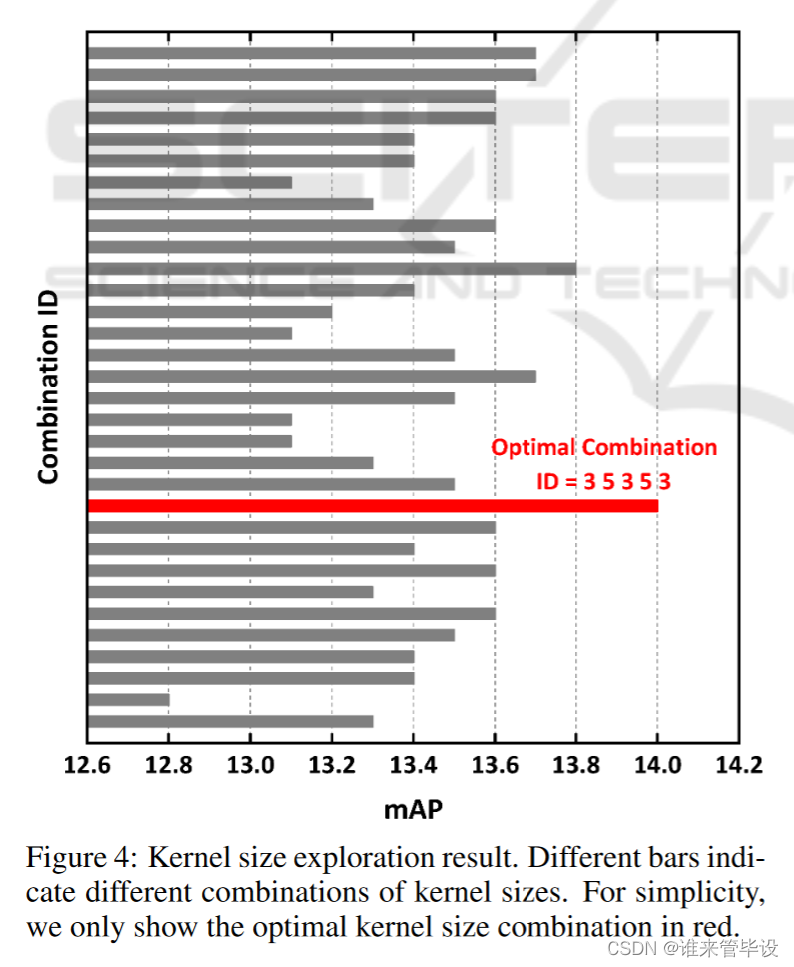
如3.2节所述,核大小的选择对于提高mAP是非常重要的。因此,我们选择YOLOv3-tiny检测部分之前的第3、5、7、9、11层,来探索不同内核大小对这些层的影响。对于每一层,我们从3×3和5×5中选择内核大小,从而导致25=32不同的排列和组合。为了节省我们的训练时间,我们从头开始训练每个实验20个epoch,并找到这些排列和组合的最佳组合。如图4所示,在32种组合中,交织3×3和5×5内核大小的网络质量最好。由此可见,在第3层、第5层、第7层、第9层、第11层分别使用大小为3、5、3、5、3的卷积核,可以获得最好的mAP。(纯靠实验得到的结果,解释性可能较差)
4.2. 剪枝结果
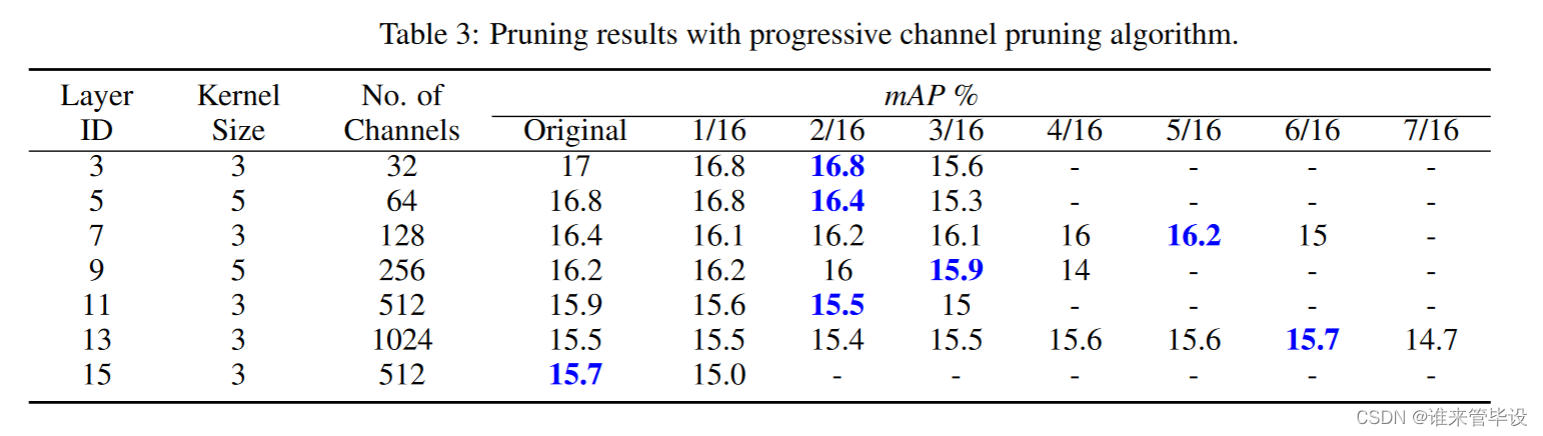
为了进一步压缩模型,我们对前7个卷积层应用了渐进式剪枝。剪枝结果如表3所示,其中x/16表示每一层的剪枝步骤。例如,第3层包含32个通道,我们首先根据初始通道数的1/16计算修剪2个通道。在第二步,我们修剪4个通道,即32个通道中的2/16。当剪枝初始通道数的3/16时,mAP与初始值相比下降1.4%,大于0.5%,此时我们停止剪枝这一层,进入下一层。
如表3所示,当我们对通道数的2/16进行剪枝时,大部分卷积层无法进一步剪枝。如果继续修剪,mAP开始显著降低。因此,表3所示的结果也证实了我们的猜想:随着网络深度和卷积层通道数量的增加,卷积层对剪枝的“容忍度”逐渐增加,使我们能够在更深的层(如第11层和第13层)剪掉更多的通道(这个规律有意义)。特别是在第13层,我们甚至在不减少mAP的情况下,修剪了6/16的通道数,即384个通道。然而,在第15层中,我们观察到一个异常情况,即使1/16的通道数量也不能被修剪。我们怀疑原因可能是这一层离检测层太近了。
4.3. 基准和比较
将我们提出的Micro-YOLO与YOLO-nano、YOLO-lite和YOLOv3tiny进行比较。我们从头开始训练所有网络500200batches,类似于YOLOv3-tiny中使用的训练方法。表4给出了YOLOv3-tiny、YOLO-lite、YOLO-nano和Micro-YOLO的模型大小、计算成本、COCO数据集上的mAP和FPS。
与YOLOv3-tiny网络相比,我们的Micro-YOLO初始版本已经在COCO数据集上实现了参数显著减少3.46倍,运算次数显著减少2.55倍, mAP略微减少0.7%。应用粗粒度剪枝后,Micro-YOLO的权值参数比YOLOv3-tiny减少了4.61倍,计算成本减少了3.23倍, mAP比YOLOv3-tiny减少了3.8%。YOLO-lite模型参数大小为0.46M,计算成本为0.93GMAC,在COCO数据集上的mAP达到12.3%。YOLOnano模型参数大小为3.18M,计算成本为3.49GMAC,在COCO和PASCAL VOC 2007数据集上分别实现了14.5%和69.1%的mAP,这是因为YOLOnano是在PASCAL VOC 2007数据集上进行优化的,在COCO数据集上表现不佳。至于延迟,我们重新评估了单个Nvidia GTX 2080Ti显卡上所有网络的FPS。我们的Micro-YOLO和pruned MicroYOLO分别达到328和357 FPS,仅次于yolo lite。由于YOLO-nano是基于PASCAL VOC 2007数据集进行优化的,因此它在COCO数据集上的性能不太好。

5. 结论
在本文中,我们探索了几种模型压缩方法,并提出了一种改进的基于YOLOv3tiny的目标检测体系结构Micro-YOLO。我们分析了几种类型的卷积层,如深度可分离卷积(DSConv)和带有挤压和激励块的反向瓶颈卷积(MBConv),以确定我们的Micro-YOLO网络的最佳层。我们还探讨了这些卷积层中不同内核大小对Micro-YOLO性能的影响。在此基础上,我们提出了一种新的渐进式通道剪枝方法,以减少原始网络的参数数量和计算成本。Micro-YOLO只需要2.56M参数和1.10GMAC的计算成本,就可以实现32.4%的mAP和328帧的帧数,略低于原来的YOLOv3tiny网络。应用剪枝技术后,我们可以进一步将参数数量和计算成本降低到1.92M和0.87GMAC, mAP为29.3%,FPS为357。我们还将我们的工作与其他各种基于yo的网络进行了比较,并取得了令人满意的结果。我们相信,我们压缩YOLOv3tiny的方法可以高度适用于未来版本的YOLO或其他物体检测模型。
设老师锐评:
感觉是把不同小点做到一起因此能发出paper,单独拿卷积层替换(用的卷积层都是前人提出的,怎么替换得到最优结构也是纯实验得出的)和新剪枝方法(起名渐进式剪枝,其实是一种逐层迭代剪枝)好像都不是很amazing,但文章整体写得很流畅,文章组织逻辑和语法读起来都很舒服,是值得学习的地方。
另外:看得出来做了很多实验,把文章填满了……














 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









