






da亲和力通常用解离常数(Kd)、抑制常数(Ki)或半最大抑制浓度(IC50)等指标来表示。结合亲和力的测量可以通过多种生物实验方法进行,其中包括蛋白质微阵列和亲和层析两种常见的方法。
一.Prediction of protein–ligand binding affinity via deep learning models
通过深度学习模型预测蛋白质-配体结合亲和力 2024.3 二区 综述类型
1.模型
主要介绍深度学习模型。深度学习模型主要基于CNN和GNN。
根据模型的输入特征是否包含蛋白质-配体相互作用信息,这些模型可以分为两类,基于相互作用的模型和无相互作用的模型。基于深度学习模型预测蛋白质-配体相互作用的整体流程图如下:
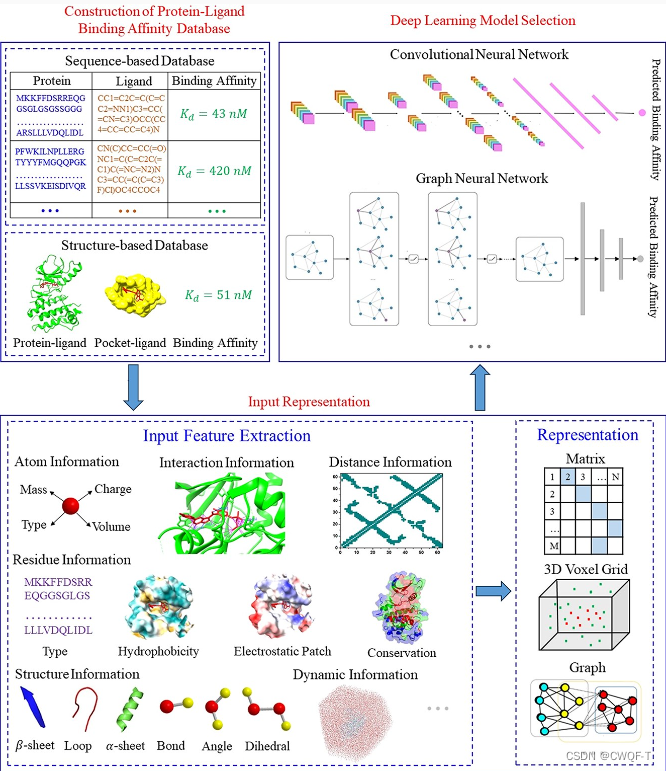
模型如下:(A) 基于交互的深度学习模型的工作流程。输入是口袋配体复合物结构及其特性。(B) 无交互深度学习模型的概念工作流程。无结构模型可以在没有蛋白质-配体相互作用信息的情况下预测蛋白质-配体结合亲和力。无相互作用模型的输入是配体、SMILES 串/蛋白质序列或配体/蛋白质单体、3D 结构及其特征。
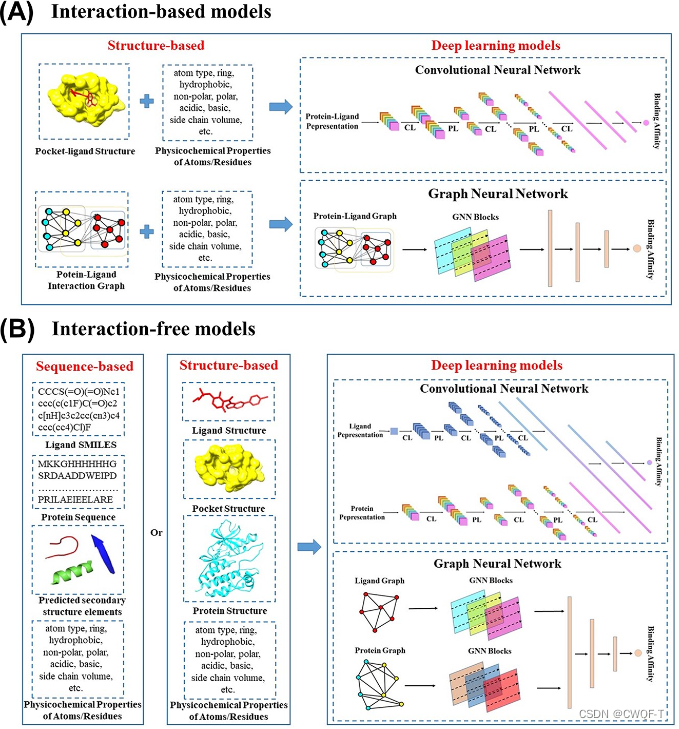
现在很多模型是基于交互的模型,一些模型采用3D体素网格来表示蛋白质-配体复合物的3D结构作为CNN的输入特征。不同的原子信息(氢键、疏水性、芳香性、排除体积等)被编码到 3D 网格的不同通道中。这些模型旨在通过CNN学习三维体素网格中原子的空间分布和特征信息,从而获得蛋白质-配体相互作用,如氢键和疏水相互作用,并最终预测蛋白质-配体结合亲和力。但是,3D 体素网格表示存在一些限制:由于计算成本的限制,这些网格大小通常围绕蛋白质的结合位点定义,导致缺乏长距离的相互作用。其次,CNN 使用 3D 卷积从 3D 体素网格中提取交互信息,效率较低,因为大多数体素不包含有用的拓扑信息。第三,有限的原子特征不足以提供所有非共价相互作用,这对于预测蛋白质-配体结合亲和力至关重要。此外,三维网格对旋转的敏感性对预测结果有负面影响。也有模型使用基于蛋白质和配体原子之间的接触,将其表示成具有矩阵或二维图形以预测蛋白质-配体结合亲和力。然而,基于相互作用的模型仅限于已知的蛋白质-配体复合物结构。
无相互作用模型的输入包括配体SMILES串/蛋白质序列和配体/蛋白质单体结构,或者口袋序列、预测的二级结构、蛋白质/口袋的原子和残余物理化学性质以及配体的生物活性性质为。尽管无相互作用模型不限于已知的蛋白质-配体复合物结构,但它们仍具有以下局限性。基于序列的模型需要高度的同源性样品。两个现有的基于序列的数据库中的样品都是激酶-配体对。此外,基于序列的模型的输入通常由其他计算方法进行预处理,例如多序列比对和二级结构预测方法。这些方法的计算精度会影响深度学习模型的预测精度。此外,无相互作用模型的输入缺乏有效的相互作用、拓扑和化学键信息,这使得准确预测蛋白质-配体结合亲和力变得困难。
2.表示
一些模型使用蛋白质单体和配体单体作为模型的输入,而另一些模型则使用蛋白质-配体复合物作为输入。前者不需要已知的蛋白质-配体结合姿势,因此其适用性更广。后者包含有关蛋白质-配体相互作用的直接信息,从而提高了预测准确性。
1.药物表示
一些数据库,如Davis和KIBA,提供了配体SMILES字符串,该字符串使用一系列字符来描述基于原子、键、环等的配体二维(2D)结构。这些配体 SMILES 字符串通常由整数编码为输入特征。例如,Öztürk等人扫描了大约2个M配体SMILES,并编译了64个编码为1-64的字符。为确保所有配体 SMILES 都以相同的长度编码,配体 SMILES 被截断或填充 0 秒至允许的最大长度 L。此外,配体SMILES可以进一步转换为2D基质或2D分子图
2.蛋白质表示
蛋白质序列由整数编码的氨基酸或基于氨基酸类型的单热载体编码为输入特征。 近年来,一些特征,如二级结构、位置特异性评分、相对溶剂可及性和二面角,通过现有的基于蛋白质序列的计算方法进行了预测。
此外,由于蛋白质的尺寸很大,DL模型直接将全局蛋白质结构编码为输入的成本是巨大的,并且配体直接结合到指定蛋白质内部或表面腔的局部口袋,所以常常使用局部口袋。配体和口袋之间稳定结合的条件是它们具有匹配的几何形状,并且口袋的原子与配体的原子具有很强的分子间相互作用。因此,口袋信息,包括序列、二级结构元素、三级结构和理化特征,通常表示为三维网格、隐式图或点云,然后在一些模型中用作输入特征来预测蛋白质-配体结合亲和力。
3.实验
1.数据集
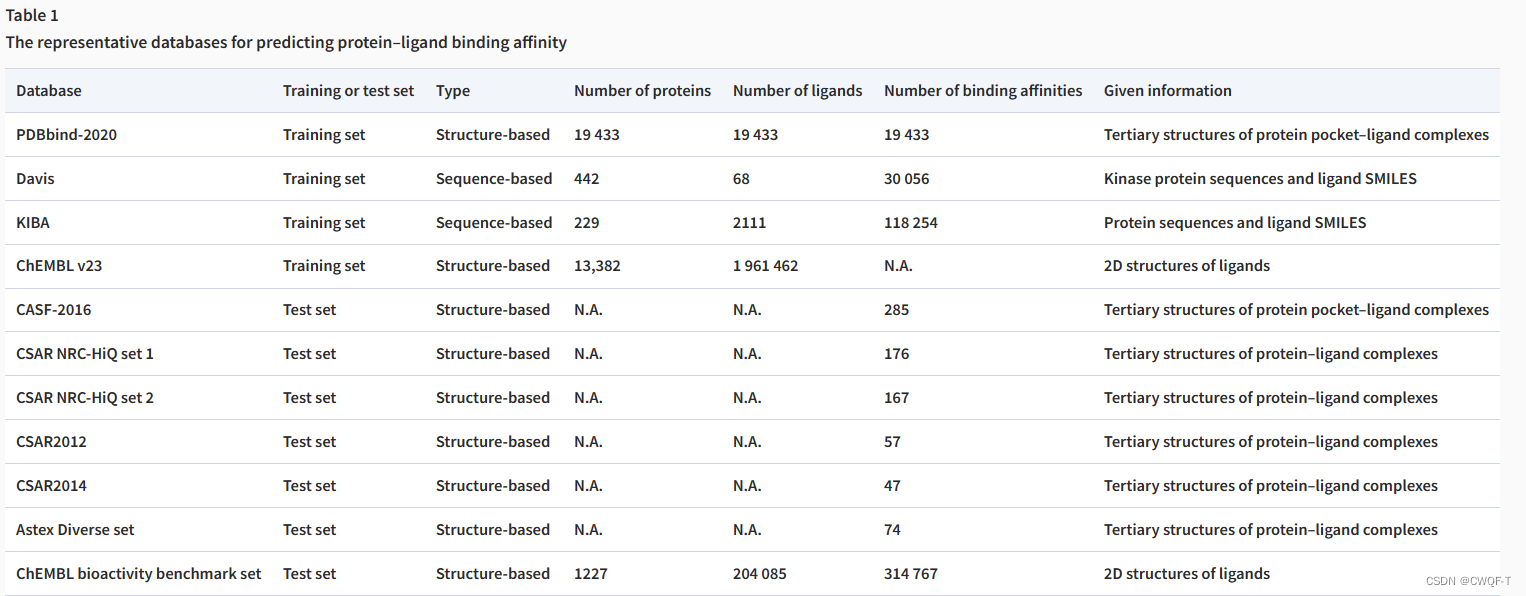
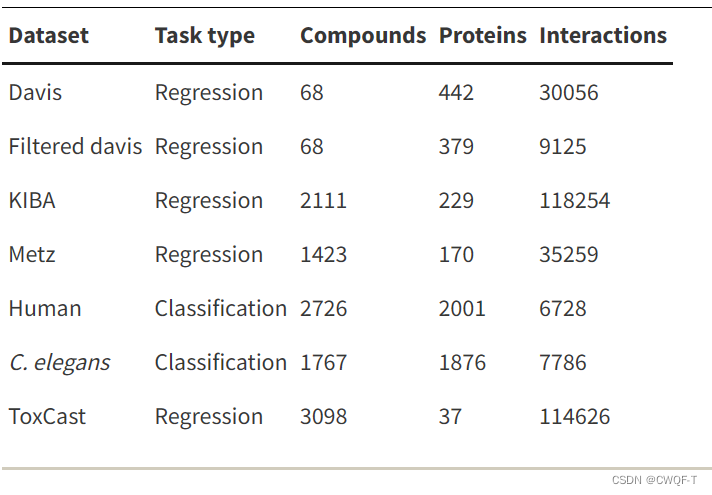
常见的是PDBbind数据库、Davis数据库、KIBA数据库和ChEMBL数据库。基准测试的代表性非冗余子集包含一组核心PDBbind数据库、评分函数比较评估(CASF)、群落结构-活动资源(CSAR)、Astex Diverse 集合和ChEMBL生物活性基准集。这些数据库总结在下表中,可分为两类:序列数据和结构数据。KIBA数据库是目前最好的基于序列的数据库。PDBbind数据库由于其样本量大和严格的过滤条件,是目前使用最广泛的数据库。
4.挑战
1.数据库方面: 一些数据库只包含数百种蛋白质甚至数十种配体,这可能导致欠拟合状态和不良的学习结果; 基于序列的数据集中经常存在严重的数据不平衡; 需要为其他蛋白质开发一个基于序列的数据库,因为现有的两个基于序列的大型数据库都只与激酶蛋白有关; 基于结构的数据库的样本量受到蛋白质数据库中蛋白质-配体复合物现有晶体结构的数量和质量的限制。
2.表征方法:现有的序列信息输入表示方法在表征突变残基对蛋白质-配体结合亲和力的影响方面仍面临挑战; 对于蛋白质序列的不同长度,可以通过多序列比对来统一所有序列的长度,这可能比简单地使用长度截断更好。
3.结构信息:现有的输入缺乏细胞环境信息和底物与靶蛋白结合。而且,配体与蛋白质的结合是一个动态过程。原子位置和结合姿态的变化可以为理解配体结合靶蛋白提供重要信息。将动态结构信息转换为动态图,并将其用作动态图神经网络的输入,以预测蛋白质-配体结合亲和力可能是一项很有前途的工作。
二.GraphATT-DTA: Attention-Based Novel Representation of Interaction to Predict Drug-Target Binding Affinity
GraphATT-DTA:基于注意力的交互新表示以预测药物靶标结合亲和力 2022.12 二区
1.模型
它考虑了用于 DTA 预测的局部到全局相互作用。化合物的分子图和蛋白质氨基酸序列是初始输入。 GNN 模型用于化合物表示,一维 CNN 用于蛋白质表示。通过捕获重要的子区域(即子结构和子序列),使用注意力机制对化合物和蛋白质之间的相互作用进行建模,以便全连接层可以预测化合物与其靶蛋白之间的结合亲和力。
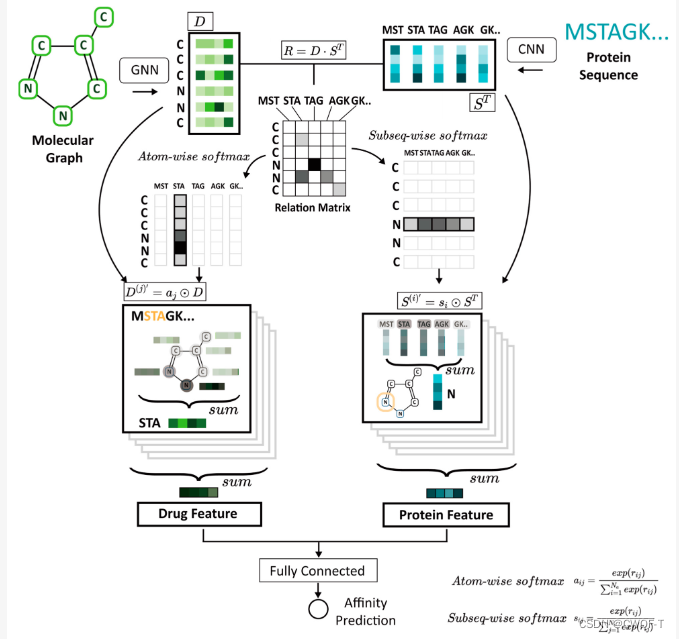
1.药物表示
分子的二维图结构


2.蛋白质表示
氨基酸序列类型都用整数编码,最大长度为 1000。如果序列短于最大长度,则用零填充它们。最大长度可以覆盖至少80%的蛋白质。
2.实验
1.数据集
Davis数据集使用五折交叉验证方法,而BindingDB不使用。
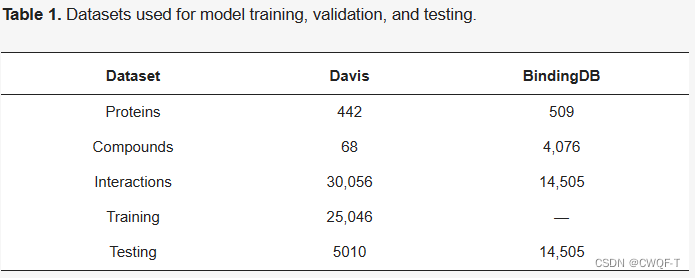
3.结果
1.用Davis数据库研究 使用不同的药物分子图模型(分别进行十次交叉验证)的结果,GIN的MSE最低最好,其次是GCN和MPNN。一致性指数CI的数值中,最高最好的是MPNN,为0.899。
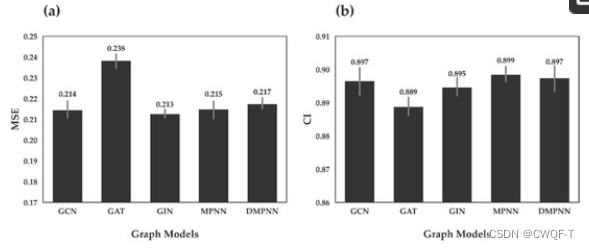
2.使用Davis数据库和BindingDB数据库进行结果比对:全局方法包括 DeepDTA 和 GraphDTA,局部方法包括 DeepAffinity、ML-DTI、HyperAttentionDTI 和 FusionDTA。Davis 数据集由六部分组成:五部分用于训练,一部分用于测试。最后,选择预测性能最佳的模型。
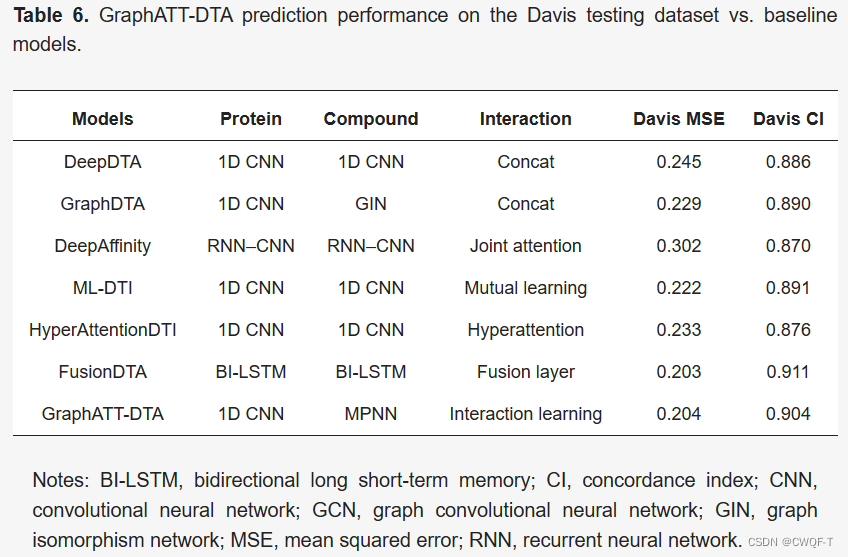
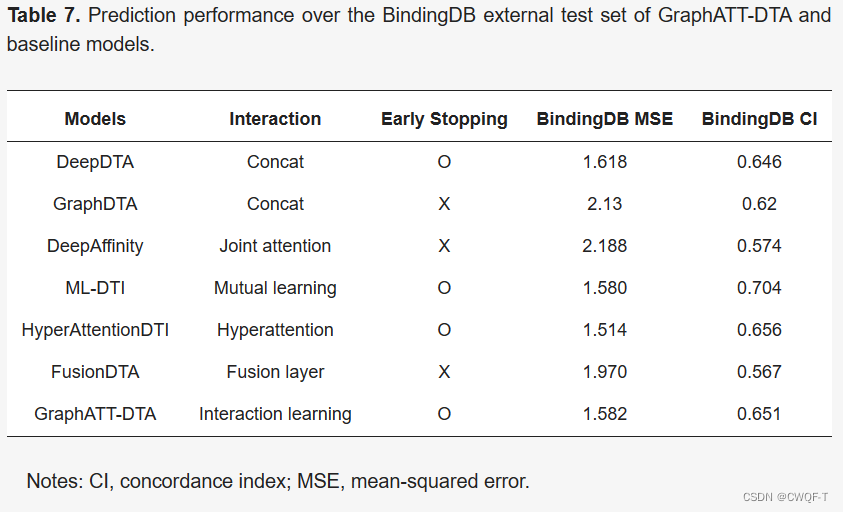
3.消融实验:在药物和蛋白质嵌入矩阵上使用最大池化,然后进行串联。全连接层预测了结合亲和力。

最后作者还进行了可视化与案例研究,在此不详细叙述。
三.Predicting drug–target binding affinity with cross-scale graph contrastive learning(后续需要再深入理解)
通过跨尺度图对比学习预测药物-靶标结合亲和力 2024.1 二区
1.模型
所提出的模型CSCo-DTA结合了从分子尺度和网络尺度上学到的特征,从局部和全局角度获取信息。由四个主要部分组成,包括分子尺度特征提取、网络尺度特征提取、分子和网络尺度的对比学习以及DTA预测。从DTI网络中特异地提取药物和蛋白质的网络尺度特征,以及从药物和靶分子网络中提取药物和蛋白质的分子尺度特征。接下来,CSCo-DTA利用分子尺度和网络尺度的特征表示,通过对比学习探索了两种视角之间的一致性。最后,设计了一个具有多任务训练策略的目标,以共同优化药物和靶点的表征,并预测DTA。
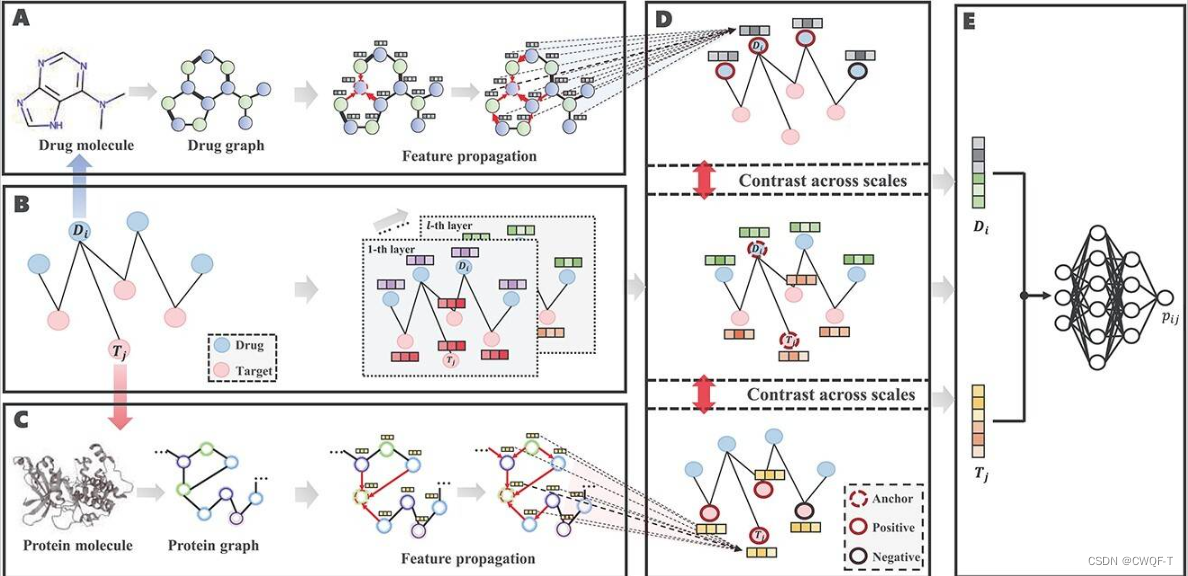
对比策略:(药物与靶标的策略是类似的)
利用图卷积网络(GCN)在DTI上执行特征提取操作。为了生成正样本,提出了一种新的采样策略,包括基于分子特征的采样和基于网络结构的采样。
(1)对于基于分子特征的采样,是从分子图得到的特征。其想法是具有相似分子结构的节点被认为是高度相关的,可以用作阳性样本对。具体来说,PubChem 结构聚类工具用于计算分子水平的药物-药物相似性,保存为矩阵 ,Smith-Waterman 算法用于计算蛋白质序列相似性,保存为矩阵。这都是分子水平的信息。
(2)对于基于网络结构的采样,其思路是网络中共享公共邻居的节点是相关的。提出了一种基于元路径的方法来计算药物之间的相似性。药物之间的相似性定义为药物-靶点网络中药物之间的元路径数量,即药物-靶点-药物(假设有一个药物-靶点网络,其中药物A和药物B之间存在以下元路径:A-1-B、A-2-B、A-3-B。那么药物A和药物B之间的元路径数量为3。这意味着这两个药物之间存在三种不同类型的路径,每种路径代表不同的关联方式)。药物相似性被归一化并保存为矩阵。
最后,根据分子水平和网络水平的观点为每种药物选择阳性样本:对两种采样策略生成的 药物-药物相似性矩阵 和 药物相似性矩阵 求和,然后按降序对样本进行排序。排名靠前的样本被选为阳性样本(也就是与这种药物有高亲和力的靶标??),其他样本被视为阴性样本。
对比损失函数如下:h表示药物和蛋白质的向量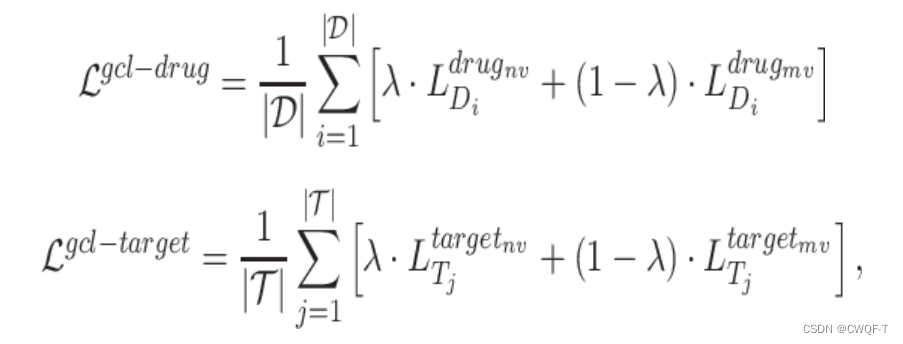
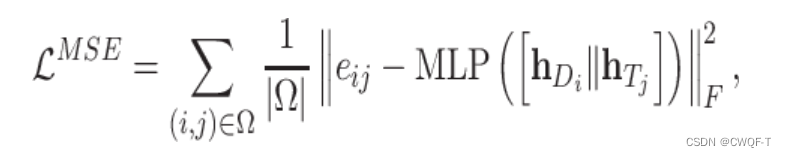
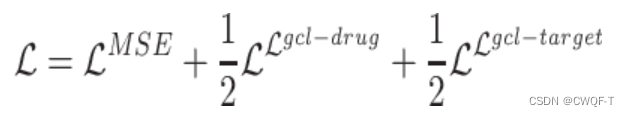
1.药物表示
分子图,用RDKit处理实现
2.蛋白质表示
蛋白质图(第一次见!!!)每个靶蛋白都可以看作是以氨基酸残基为节点的图,边表示氨基酸之间存在接触(文章中也使用了蛋白质接触图来确定哪些氨基酸之间相互接触)。用论文Drug-target affinity prediction using graph neural network and contact maps所提出的方法来生成接触图,并且进行处理。
2.实验
1.数据集
Davis和KIBA
3.结果
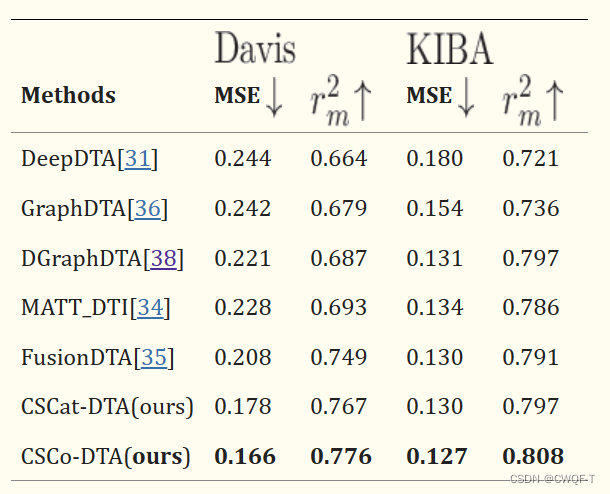
散点图表示结合亲和力之间的相关性。x 轴表示 CSCo-DTA 模型预测的分数,y 轴表示真实的测量值。红色虚线表示预测值和真实值之间的完全一致线,与该线越接近的数据点表示预测精度越高。
DAVIS数据集
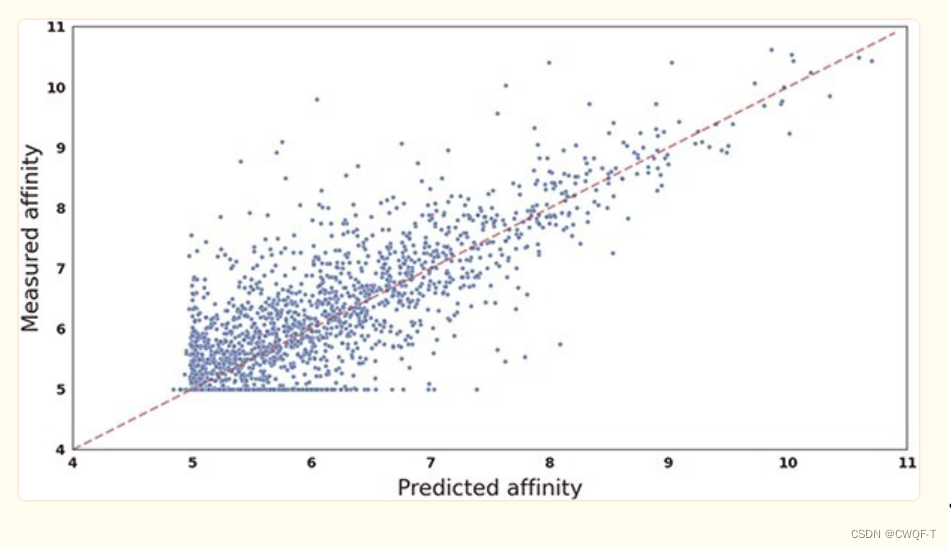
KIBA数据集
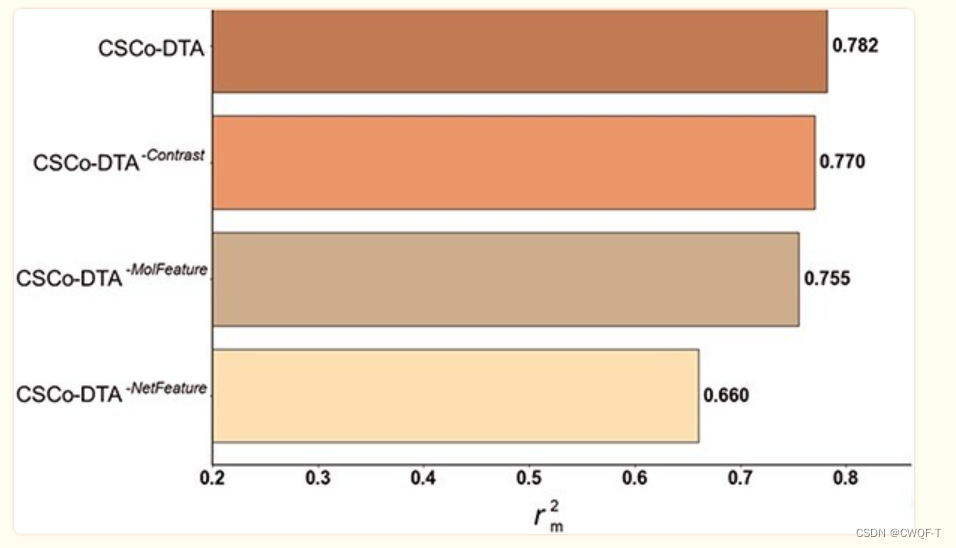
消融实验:仅使用分子尺度特征或网络尺度特征 ,以及没有跨尺度图对比分量
DAVIS数据集

KIBA数据集
四.MGraphDTA: deep multiscale graph neural network for explainable drug–target binding affinity prediction
用于可解释药物-靶标结合亲和力预测的深度多尺度图神经网络2022.1 一区
问题:浅层GNN不足以捕获化合物的全局结构,比如具有两层的GNN无法知道分子中是否存在环,并且将在不考虑有关环的信息的情况下生成图嵌入,太多层卷积层会导致过渡平滑和梯度消失问题;基于图的DTA模型的可解释性高度依赖于图注意力机制,无法揭示分子各原子之间的全局关系,并且计算成本大。
方法:构建了一个具有27个图形卷积层的MGNN,以同时捕获化合物的局部和全局结构;还开发了一种新颖的可视化解释方法,梯度加权亲和激活映射(Grad-AAM),从化学角度分析深度学习模型。并且作者认为基于GNN的方法优于PCM方法(基于特征的 DTA 预测建模方法也称为蛋白质化学计量学 (PCM),它依赖于显式配体和蛋白质描述符的组合)。
1.模型
采用27个图卷积层的MGNN用于处理药物信息,和多尺度卷积神经网络(MCNN)分别提取药物和靶点的多尺度特征。将提取的药物和靶标的多尺度特征分别融合,然后连接以获得给定药物-靶标对的组合描述符。将组合的描述符输入MLP以预测结合亲和力。
在GNN处理中有两个阶段:消息传递阶段会根据考虑相邻节点来更新此节点的信息;readout阶段会整合(sum)所有节点的向量再取平均值来得到分子的向量。
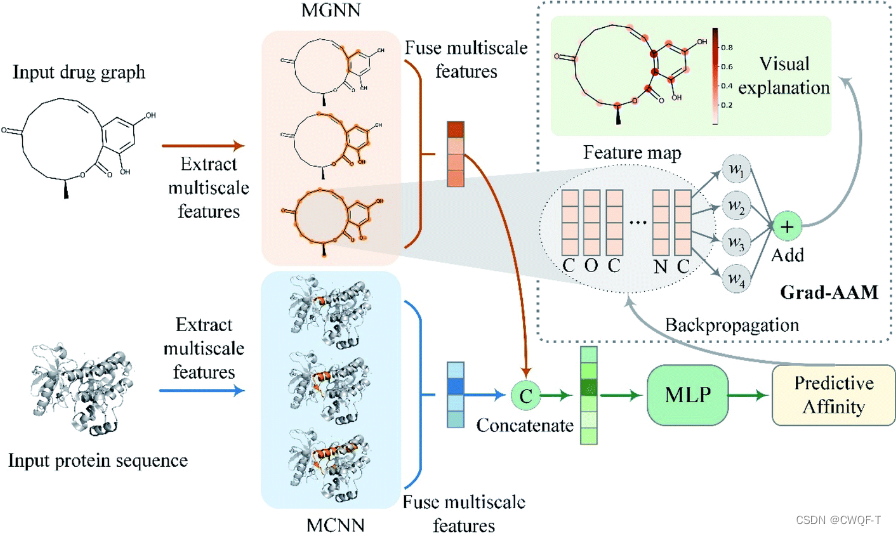
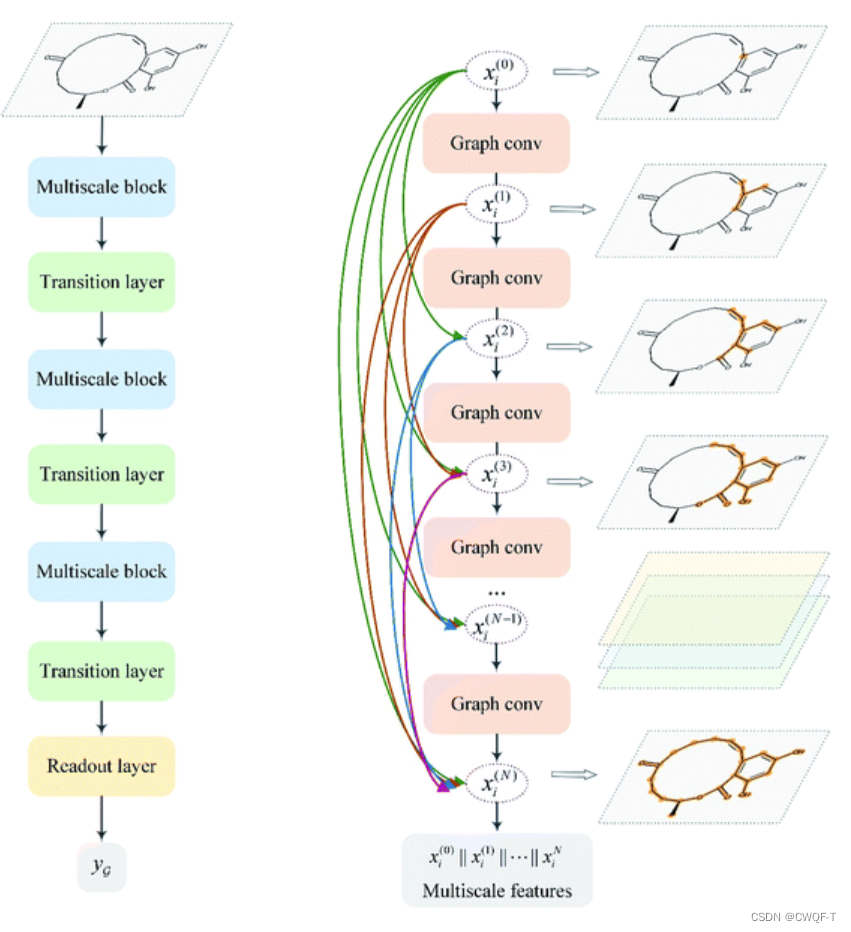
MGNN块:包括三个多尺度块(||表示连接),其中每个多尺度块后面跟着一个过渡层,过渡层旨在集成前一个多尺度块的多尺度特征,并减少特征图的通道数为之前的一半。并且GNN中引入了Dense连接,使得所有层都直接获取到损失函数对每个权重的梯度,从而避免了梯度消失问题,并且能够训练非常深的图神经网络。
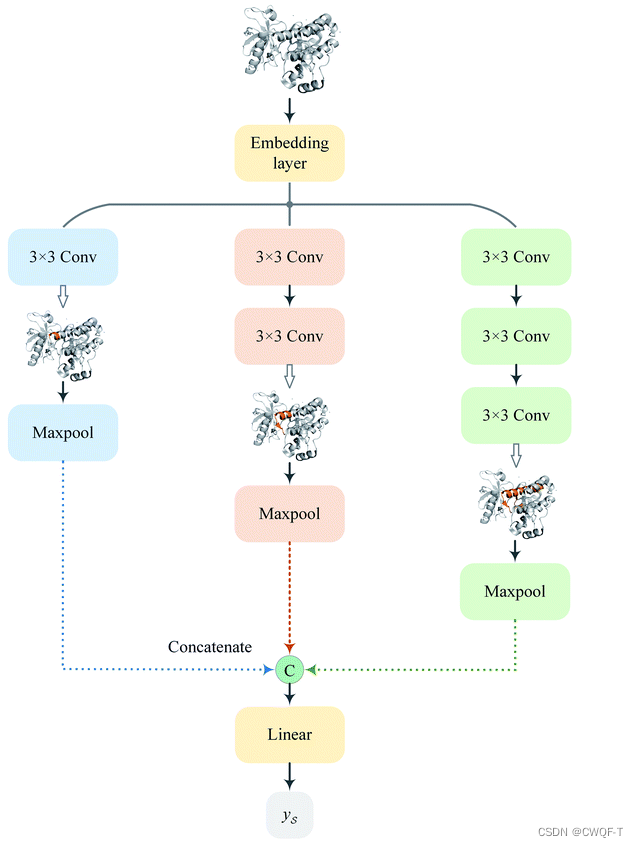
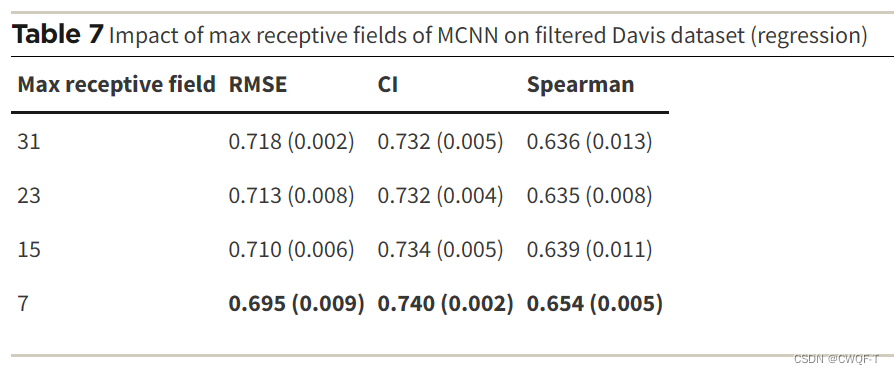
MCNN:由具有不同感受野的卷积层组成的三个分支的网络,三个分支的感受野分别为 3、5 和 7,以检测不同尺度上蛋白质的局部残基模式。(作者认为增大感受野以覆盖整个序列是不合适的,会引入很多噪声)
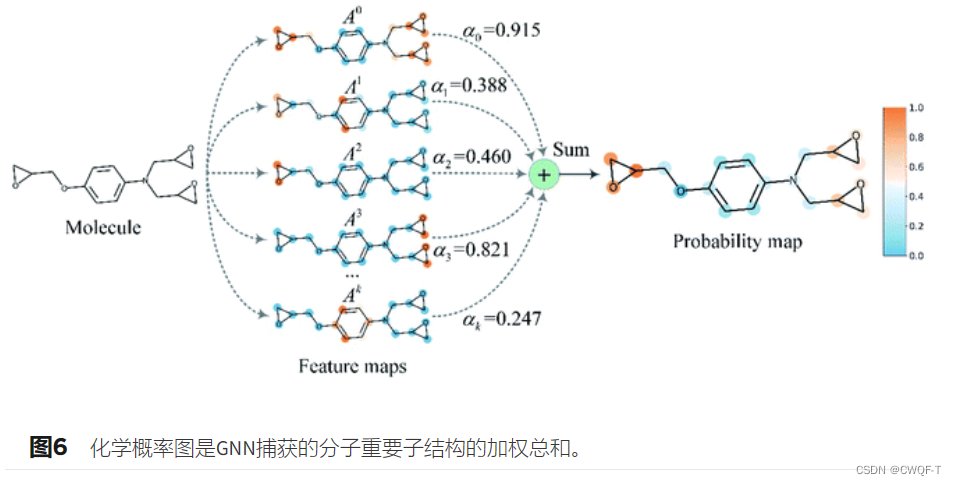
Grad-AAM使用流入MGNN最终图卷积层的亲和力梯度来生成概率图,突出显示对DTA贡献最大的重要原子。首先计算了亲和力分数 P 相对于神经元 A 的梯度,在 A 的第 k 个通道和第 v 个顶点处为 Avk,通道重要性为
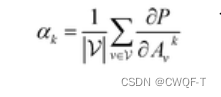
最后进行加权组合得到最终的概率:
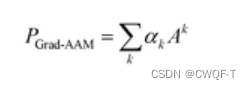
采用min–max归一化算法把这些值映射到0-1之间:
1.药物表示
SMILES生成分子图
2.蛋白质表示
先构建词汇表,将每个字符映射成整数,即将蛋白质表示为整数序列。固定长度为1200。再把每个氨基酸映射成128维的向量。
2.实验
1.数据集
回归任务的基准数据集是 Metz,DAVIS,KIBA,ToxCast数据。并且还评估了该模型在去除了具有10μM生物活性的数据点后的DAVIS数据集中的性能。
3.结果
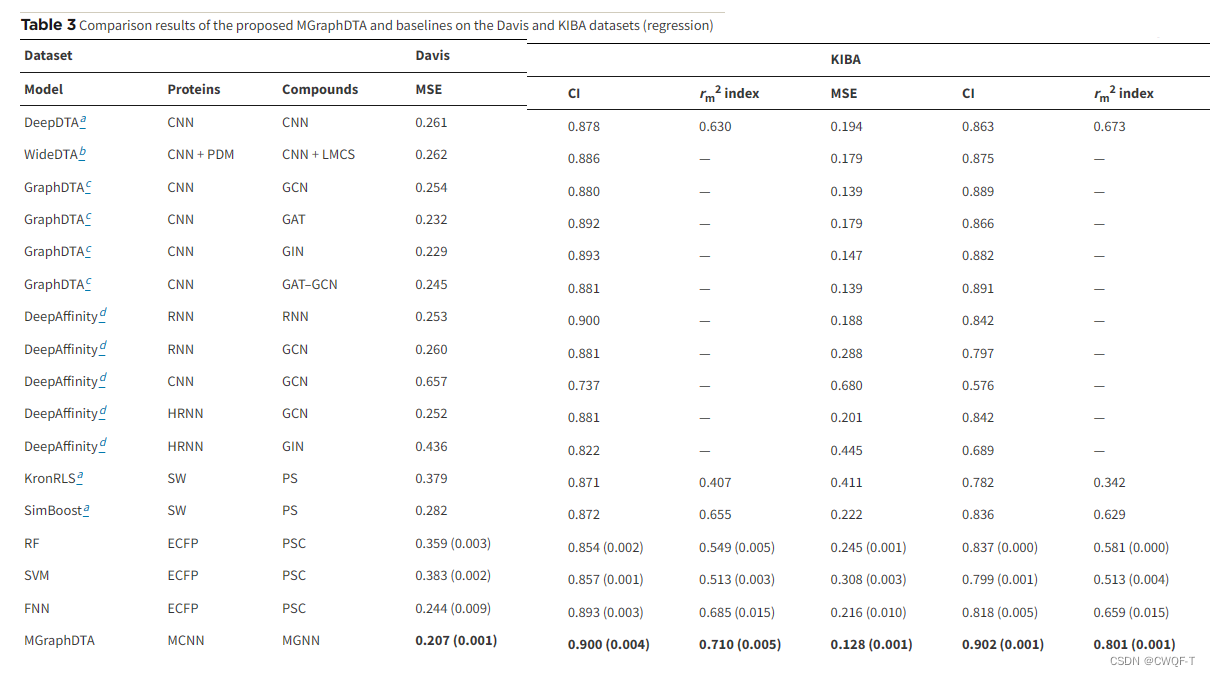
指标:MSE(越小越好)、一致性指数CI(越大越好)、rm2(越大越好)
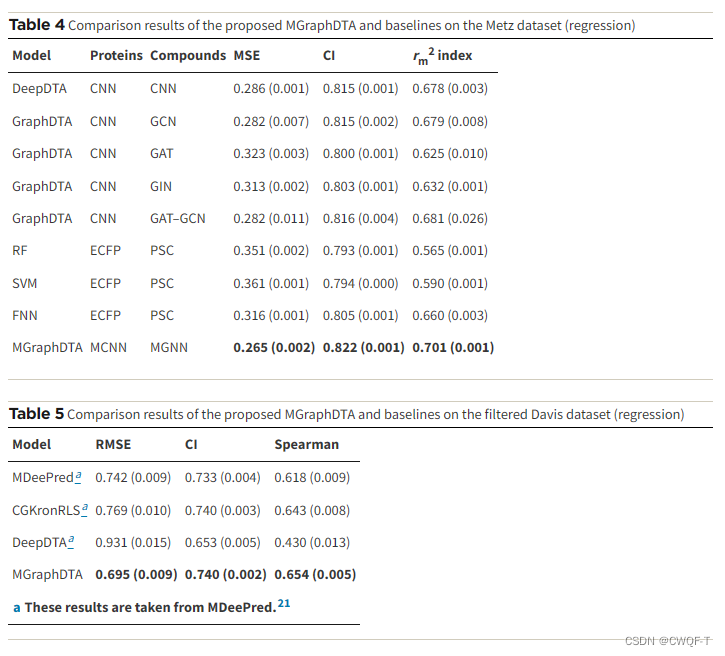
消融实验:
1.删除了Dense连接或者删除了批量规范化
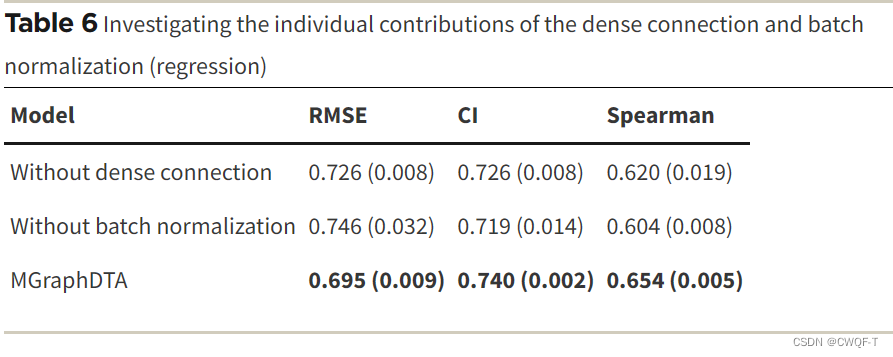
2.改变感受野

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









