






 PDBbind数据库2020版收录了23,496个生物分子复合物的结合亲和力数据,涵盖蛋白质-配体、蛋白质-蛋白质等复合物类型。数据来自约40,500篇原始文献。数据库分为通用集、精炼集等层级,为药物设计等领域提供重要资源。
PDBbind数据库2020版收录了23,496个生物分子复合物的结合亲和力数据,涵盖蛋白质-配体、蛋白质-蛋白质等复合物类型。数据来自约40,500篇原始文献。数据库分为通用集、精炼集等层级,为药物设计等领域提供重要资源。
目前的版本是2020版,这个版本提供了23496个生物分子复合物的结合亲和力数据,包括蛋白质-配体(19443)、蛋白质-蛋白质(2852)、蛋白质-核酸(1052)、核酸-配体复合物(149)。与上一个版本(v.2019)相比,这个版本中包含的结合数据增加了~10%。所有的结合数据都是从~40,500个原始参考文献中整理出来的。
PDBbind的主要价值在于收集与PDB中生物分子复合物结构相匹配的实验测量的结合亲和力数据(以Kd、Ki或IC50值的形式)。最初,PDBbind只包括蛋白质和小分子配体之间形成的复合物。自2008年以来,PDBbind已经涵盖了其他类型的复合物。
PDBbind还提供了经过处理的 "干净 "的 的结构文件,这些文件可以被大多数分子建模软件所用。每个复合物都被分成一个蛋白质分子(以PDB格式保存)和一个配体分子(以Mol2和SDF格式保存)。配体分子上的原子/键类型由专门的计算机程序进行分配,然后进行人工检查和校正。
PDBbind数据集的分层结构
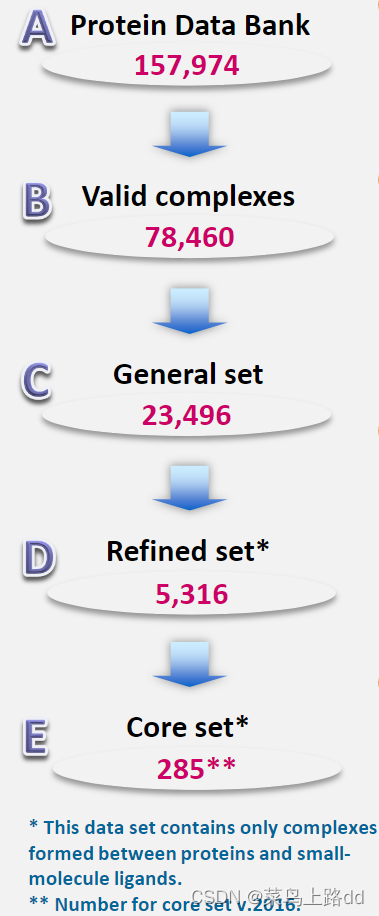
(B) PDB数据库中结构数据由一组计算机程序进行筛选,以识别四大类分子复合物:蛋白质-小配体,核酸-小配体、蛋白-核酸和蛋白-蛋白。这一步骤共识别出了78,460个PDB结构作为有效的复合物结构。
(C) 对每个复合物的主要参考文献进行检查,收集实验确定的结合亲和力数据 (Kd, Ki or IC50)。通过这种方式收集了23,496个复合物的结合数据,它们构成了PDBbind数据库的主要内容。被称为 "通用集"(General set)。
(D) 从通用集中选择质量更好的蛋白质-配体复合物,从而组成"精炼集 "(Refined set)。精炼集包含5,316个蛋白质-配体复合物。
(E) 汇总出PDBbind核心集(core set)的目的是提供一个相对较小的高质量的蛋白质-配体复合物数据集,用于验证对接/打分方法。特别是,这个数据集已经成为流行的 Comparative Assessment of Scoring Functions(CASF)中的主要测试集。PDBbind核心数据集已经不包括在PDBbind数据包中了,因为它不再是像PDBbind本身那样每年更新。


















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









