






凌晨五点,Qwen3正式发布并开源了8款「混合推理模型」
两款MoE模型:
Qwen3-235B-A22B(2350多亿总参数、 220多亿激活参)
Qwen3-30B-A3B(300亿总参数、30亿激活参数)
六个Dense模型
Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B、Qwen3-0.6B
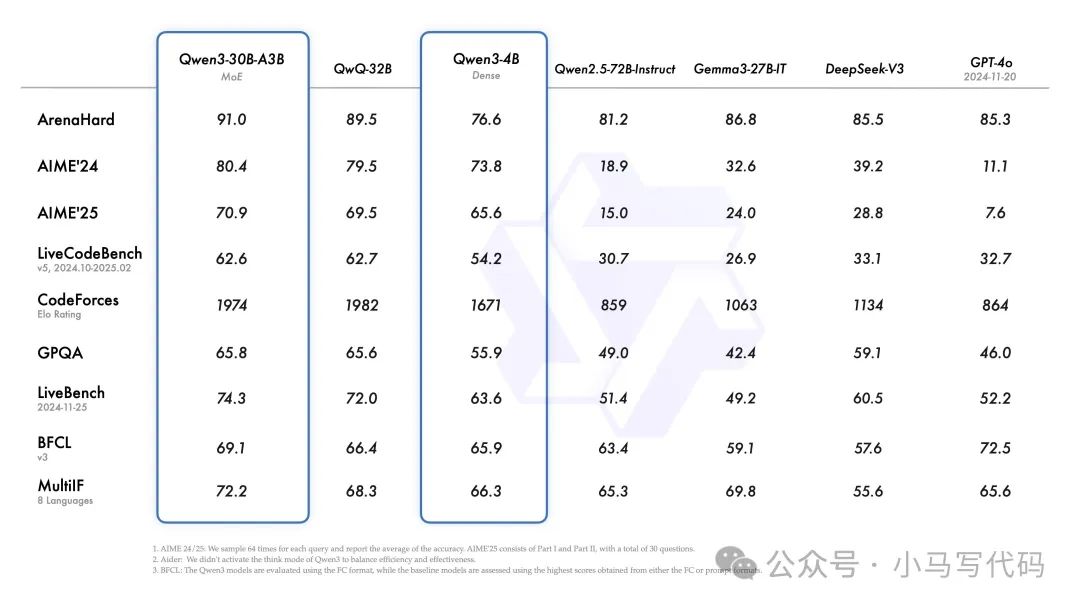
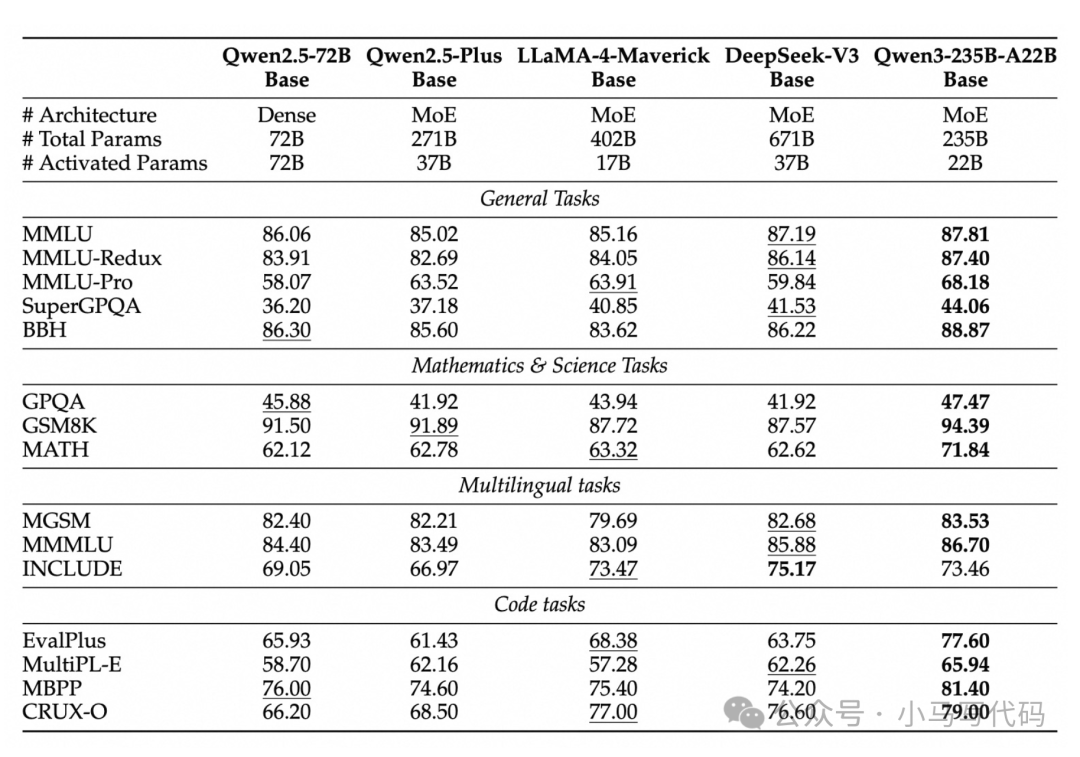
Qwen3-235B-A22B 在编码、数学、通用功能等方面的基准测试评估中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等其他顶级型号相比,取得了具有竞争力的结果。
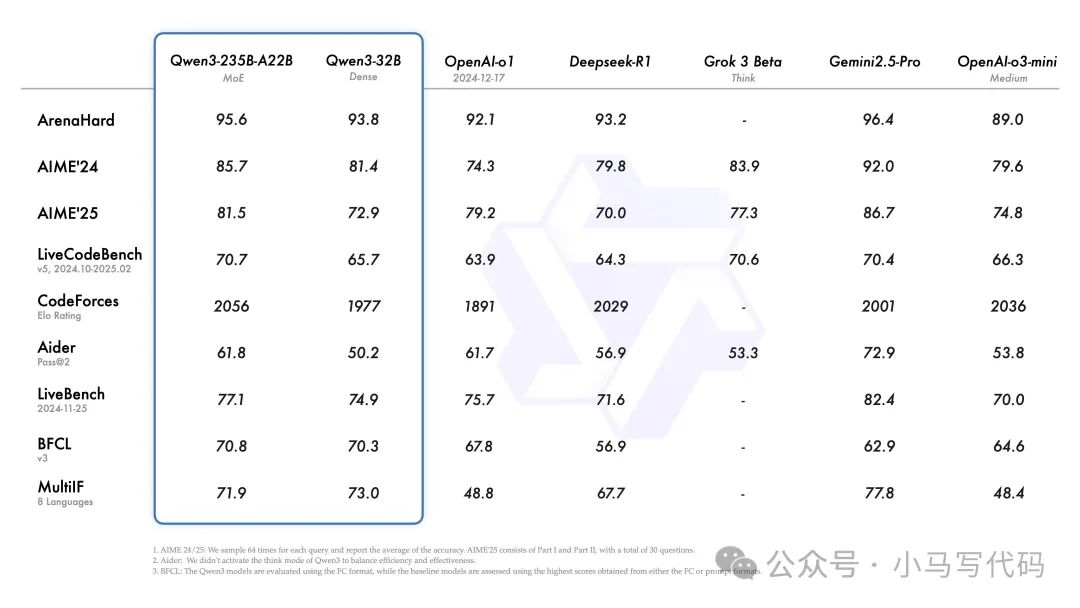
此外,小型 MoE 模型 Qwen3-30B-A3B
一、技术架构:混合推理与MoE架构的深度融合
1.混合推理模式:人类思维的AI映射
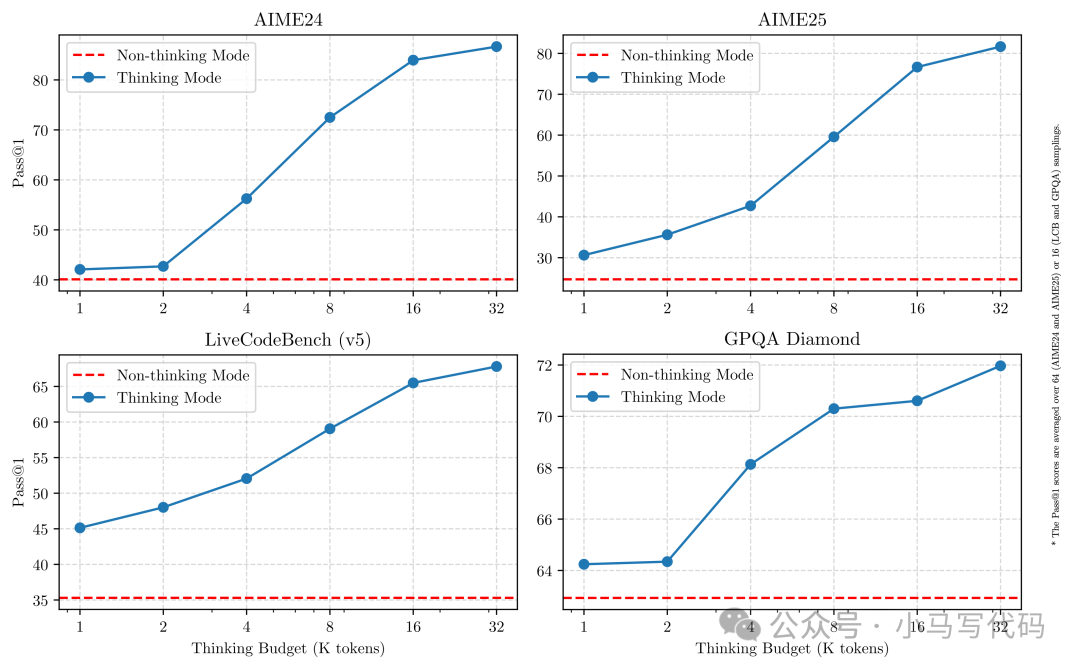
Qwen3首次实现“快思考”(直觉响应)与“慢思考”(深度推理)的动态切换,两种模式共享同一模型权重,用户可通过指令或参数实时调整:
- 深度思考模式(/think):模拟人类多步骤思维链,适用于数学证明、代码调试、逻辑分析等复杂任务。例如,在解决奥数题时,模型会分解问题、逐步推导并自我验证,最终生成详细解题过程。
- 极速响应模式(/no_think):针对简单问答、信息检索等场景,响应速度提升60%,算力消耗仅为深度模式的1/3。
- 技术实现:通过四阶段微调(长思维链冷启动→强化学习探索→模式融合→通用校准),确保两种输出分布的无缝整合。
- MoE架构革新:参数效率革命
采用“专家混合”(Mixture-of-Experts)架构,通过动态激活子网络实现性能与成本的平衡:
- 旗舰MoE模型Qwen3-235B-A22B:总参数2350亿,激活仅22亿(占总参数9.4%),性能超越DeepSeek-R1(671B参数),推理成本降低65%。
- 轻量MoE模型Qwen3-30B-A3B:激活参数3亿(Qwen2.5-32B的10%),性能反超前代32B模型,单张RTX 4090显卡即可部署。
- 36万亿Token三阶段训练
- 数据规模:训练数据量达Qwen2.5的2倍(18万亿→36万亿Token),涵盖119种语言、PDF文档提取内容及合成教科书级数学/代码数据。
- 训练策略:
◦ S1基础阶段:30万亿Token预训练,构建4K上下文语言基础;
◦ S2知识强化:5万亿Token侧重STEM、编程等高难度数据;
◦ S3长文本优化:扩展至32K上下文,支持长文档分析与报告生成。
二、模型家族:全场景覆盖的开源矩阵
Qwen3开源8款模型,包含MoE与Dense两大技术路线,适配从手机到数据中心的各类场景:
| 模型类型 | 代表型号 | 参数规模 | 核心优势 |
|---|---|---|---|
| 旗舰MoE | Qwen3-235B-A22B | 235B总/22B激活 | 企业级复杂任务(金融分析、代码生成) |
| 轻量MoE | Qwen3-30B-A3B | 30B总/3B激活 | 消费级显卡部署(RTX 4090) |
| 高性能Dense | Qwen3-32B/14B/8B | 32B-8B | 云端服务、中端设备(性能对标前代72B模型) |
| 端侧Dense | Qwen3-4B/1.7B/0.6B | ≤4B | 手机/IoT设备(Qwen3-4B性能匹敌Qwen2.5-72B) |
所有模型均基于Apache 2.0协议开源,支持商业用途。
三、性能评测:全方位碾压竞品
- 核心能力指标
- 数学推理:AIME25评测81.5分(开源模型最高),超越Gemini 2.5 Pro(74.8分)。
- 代码生成:LiveCodeBench突破70分,超过Grok-3(66.3分)。
- Agent能力:BFCL评测70.8分,工具调用准确率提升40%,支持MCP协议实现多工具协同。
- 多语言处理:119种语言覆盖(含爪哇语、粤语等),非英语任务准确率提升28%。
2.长文本与成本优势
- 支持128K上下文窗口(部分模型),32K长文档结构化提取准确率达92.7%。
- 旗舰模型部署成本仅为DeepSeek-R1的1/3,4张H20显卡即可本地运行满血版。
四、开发者生态:开源工具链与商业落地
- Qwen-Agent框架
• 内置工具调用模板与解析器,API调用代码量减少70%。
• 示例代码:
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
-
部署方案
• 云端:阿里云百炼API(即将上线)、Fireworks AI等平台支持;
• 本地:推荐使用Ollama、LM Studio、vLLM框架,最低0.6B模型可在树莓派运行。 -
开源社区爆发
• GitHub发布2小时Star数破16.9k,衍生模型超10万个,超越Llama成全球最大开源社区。
• 企业案例:夸克搜索、钉钉智能助理已接入Qwen3,处理效率提升3倍。
五、战略意义:通向AGI的关键跃迁
阿里将Qwen3定位为AGI(通用人工智能)道路上的里程碑,未来技术演进方向包括:
- 多模态扩展:集成图像、视频生成能力,2025年内推出Qwen3-VL多模态版本。
- 强化学习优化:通过环境反馈实现长周期推理,提升复杂任务规划能力。
- 全球语言覆盖:计划新增50种小语种支持,覆盖全球98%人口。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









