






Adam算法
torch.optim.Adam()是PyTorch中的一种优化算法,它实现了自适应矩估计(Adaptive Moment Estimation,Adam)优化算法。Adam算法结合了动量法和RMSProp算法的优点,在处理非平稳目标函数和梯度稀疏的问题时表现良好。
Adam算法通过计算梯度的一阶矩估计(即梯度的平均值)和二阶矩估计(即梯度的平方的平均值),来对不同参数的学习率进行自适应调整。Adam算法通过维护一个动态的学习率来保证每个参数的更新都有适当的学习率,从而加速模型的收敛。
在PyTorch中,我们可以使用torch.optim.Adam()来构建Adam优化器。它的参数包括待优化参数组、学习率、权重衰减(可选)、梯度裁剪(可选)等。
Adam(Adaptive Moment Estimation)是一种常用的优化算法,它结合了Adagrad和RMSProp的优点,在不同的学习率情况下计算每个参数的自适应学习率,更加高效地更新参数。Adam算法使用了指数移动平均估计的梯度的一阶矩(即均值)和二阶矩(即方差),并且可以根据需要对偏差进行修正,有效地解决了Adagrad算法中学习率下降过快的问题。
Adam算法的主要优点是可以自适应地调整每个参数的学习率,对于大规模数据和高维参数空间的优化效果尤为明显。
代码思想
1.构造阶段
首先构造computez()方法来根据传入的x,y值来计算z值,本代码用到的公式为
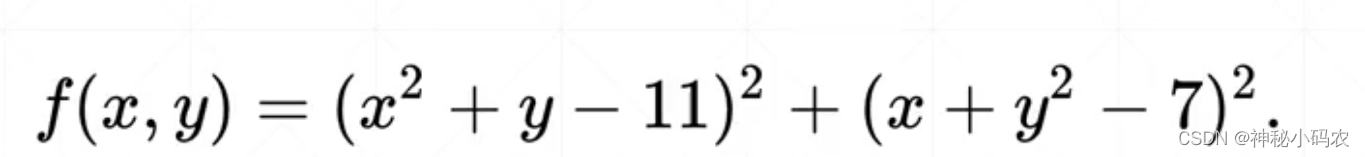
接着用numpy包中的meshgrid()方法将x,y转变为矩阵形式X,Y,调用computez()方法来将矩阵形式的横纵坐标数据传进去,得到矩阵形式的输出Z
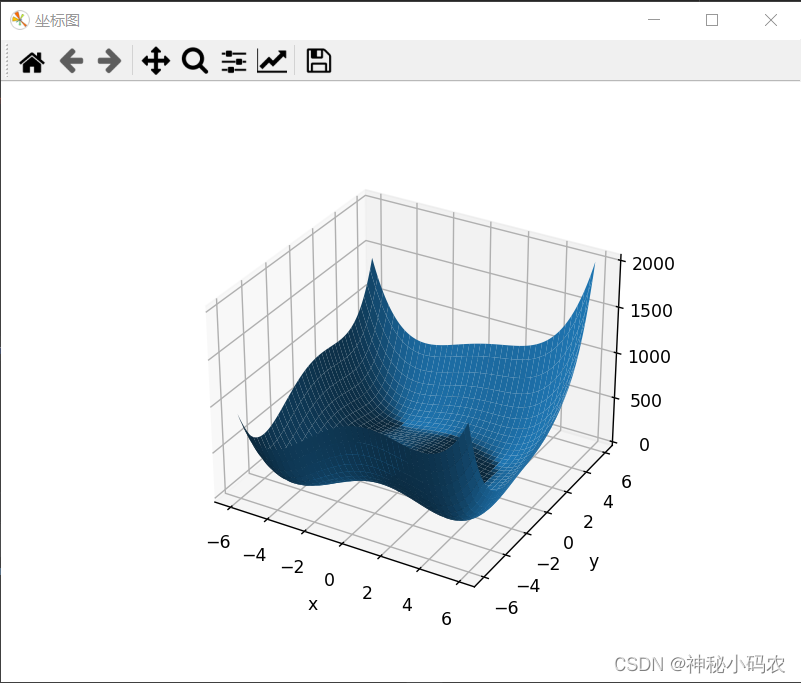
根据X,Y,Z调用matplotlib包中的方法输出对应的坐标图像并输出图像。
def computez(a):
return (a[0]**2+a[1]-11)**2+(a[0]+a[1]**2-7)**2
x=np.arange(-6,6,0.1)
y=np.arange(-6,6,0.1)
X,Y=np.meshgrid(x,y)
Z=computez([X,Y])
fig=plt.figure('坐标图')
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X,Y,Z)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
输出图像
2. 优化阶段
1.首先设置初始值x1,代码中设置为[0,0],这里注意初始值不能是整数形式,可以加上dtype=torch.float32或者将初始值设为[0.0,0.0]类似的小数形式
2. 用optimier=torch.optim.Adam([x1],lr=0.001)设置合适的学习率等信息,调用Adam方法来进行梯度优化
3. 构造一个循环来进行优化,查看输出是否收敛
x1=torch.tensor([0,0],dtype=torch.float32,requires_grad=True)
optimier=torch.optim.Adam([x1],lr=0.001)
for i in range(20000):
pre=computez(x1)
optimier.zero_grad()
#计算梯度
pre.backward()
#计算优化后的新预测值
optimier.step()
if i % 2000==0:
print('第{}步的{}的预测值为:{}'.format(i,x1.tolist(),pre.item()))
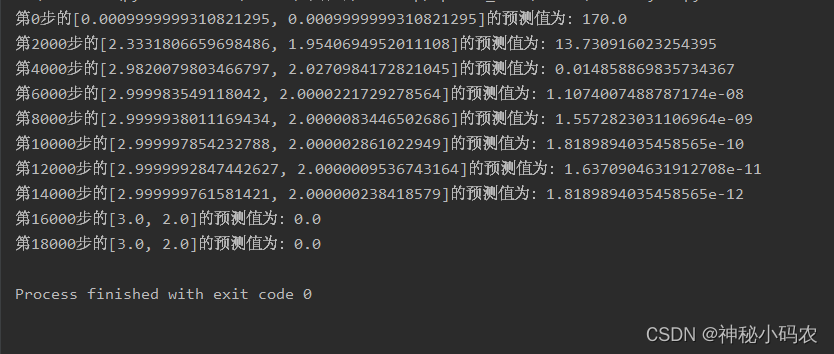
可以发现,在x,y取值[3.0,2.0]时,算法收敛,取得最小值0.
注意:初始值取值不同得到的优化结果也很有可能不同
完整代码实现
import numpy as np
import matplotlib.pyplot as plt
import torch
#构造阶段
def computez(a):
return (a[0]**2+a[1]-11)**2+(a[0]+a[1]**2-7)**2
x=np.arange(-6,6,0.1)
y=np.arange(-6,6,0.1)
X,Y=np.meshgrid(x,y)
Z=computez([X,Y])
fig=plt.figure('坐标图')
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X,Y,Z)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
##优化阶段
x1=torch.tensor([0,0],dtype=torch.float32,requires_grad=True)
optimier=torch.optim.Adam([x1],lr=0.001)
for i in range(20000):
pre=computez(x1)
optimier.zero_grad()
#计算梯度
pre.backward()
#计算优化后的新预测值
optimier.step()
if i % 2000==0:
print('第{}步的{}的预测值为:{}'.format(i,x1.tolist(),pre.item()))
代码实现参考哔哩哔哩:人工智能—小甲鱼















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









