







OpenMix_ Reviving Known Knowledge for Discovering Novel Visual Categories in An Open World (CVPR 2021)
Abstract
在本文中,我们解决了在无标签的可视数据中发现新类的问题。现有的方法通常首先用有标签数据对模型进行预训练,然后通过无监督聚类在无标签数据中识别新的类。然而,在第二步中,提供基本知识的有标签数据往往被忽视。我、而挑战在于有标签数据和无标签数据都来自于没有重叠的类,这使得很难在它们之间建立学习关系。在本工作中,我们引入OpenMix来混合来自开放集合的无标签样本和已知类的有标签样本,其中它们的非重叠标签和伪标签同时混合到一个联合标签分布中。OpenMix以两种方式动态组合样本。首先,我们将有标签样本与有标签样本合并生成混合训练图像。在新的类发现中,由于具有独特的先验知识,生成的伪标签比原始的无标签预测更加可信。因此,OpenMix有助于防止模型对可能被分配了错误的伪标签的无标签样本进行过度拟合。第二,第一种方法鼓励具有高分类概率的无标签样本具有相当的准确性。我们引入这些样本作为可靠的锚点,并进一步将它们与无标签样本混合。这使我们能够在未标记的例子中生成更多的组合,并利用新类之间更好的对象关系。
Method
Baseline
该论文中依旧采用两阶段学习策略来设计Baseline。在第一阶段,我们用有标签数据训练CNN和针对已知类别的分类器,这可以使得模型生成有基本的可区分度的图像表征,以及准确区分已知类别中的样本。在第二阶段,我们在无标签数据集上,通过一个伪配对学习和伪标签学习,学习一个无标签聚类模型,使其具有区分新类样本的能力。
第一阶段:模型初始化 给定有标签数据
D
l
=
{
X
l
,
Y
l
}
D^l=\{X^l,Y^l\}
Dl={Xl,Yl},我们能够以监督学习的方式训练模型。具体来说就是,和传统监督分类一致,用交叉熵训练模型:
L
c
e
=
−
1
n
l
∑
i
=
1
n
l
log
[
SoftMax
(
z
i
l
)
]
⊤
⋅
y
^
i
l
\mathcal{L}_{c e}=-\frac{1}{n^{l}} \sum_{i=1}^{n^{l}} \log \left[\operatorname{SoftMax}\left(z_{i}^{l}\right)\right]^{\top} \cdot \hat{y}_{i}^{l}
Lce=−nl1i=1∑nllog[SoftMax(zil)]⊤⋅y^il
其中,
n
l
n^l
nl是小批量中有标签训练样本的数量,
z
i
l
∈
R
C
l
z^l_i \in \mathbb{R}^{C^l}
zil∈RCl是针对已知类别的分类器输出向量,
y
^
i
l
∈
R
C
l
\hat{y}^l_i \in \mathbb{R}^{C^l}
y^il∈RCl是由标签
y
i
l
y^l_i
yil转换的one-hot编码。
第二阶段:无监督聚类
伪配对学习(Pseudo-Pair Learning) 给定一个在有标签数据上预训练的模型,我们在CNN的头部再添加一个针对
C
u
C^u
Cu个新类的分类层。接着,我们专注于第二阶段,例如无标签数据上的无监督聚类。为了实现该目的,我们实现探索用于模型训练的两个样本之间的关系,受之前一些工作的启发,我们认为一对图像之之间的关系应该是一种二值关系。换种说法,每对图像之间的关系要么是属于同一类,要么是属于不同类。观察到这一点,我们将无监督聚类问题转变为一个二值分类问题,旨在区分一对图像是否属于同一类。
首先,我们获取新分类器在输入无标签数据后的输出,并计算余弦相似度矩阵:
S
i
,
j
=
(
z
^
i
u
)
⊤
⋅
z
^
j
u
∥
z
^
i
u
∥
2
∥
z
^
j
u
∥
2
,
z
^
i
u
=
SoftMax
(
z
i
u
)
\mathcal{S}_{i, j}=\frac{\left(\hat{z}_{i}^{u}\right)^{\top} \cdot \hat{z}_{j}^{u}}{\left\|\hat{z}_{i}^{u}\right\|_{2}\left\|\hat{z}_{j}^{u}\right\|_{2}}, \hat{z}_{i}^{u}=\operatorname{SoftMax}\left(z_{i}^{u}\right)
Si,j=∥z^iu∥2
z^ju
2(z^iu)⊤⋅z^ju,z^iu=SoftMax(ziu)
其中
z
i
u
∈
R
C
u
z^u_i \in \mathbb{R}^{C^u}
ziu∈RCu是新分类器的输出,
n
u
n^u
nu是小批量中有标签训练样本的数量。我们接着估计伪两两标签
W
\mathcal{W}
W通过在
S
\mathcal{S}
S上设置一个阈值
θ
1
\theta_1
θ1:
W
i
,
j
=
{
0
,
S
i
,
j
<
θ
1
1
,
S
i
,
j
≥
θ
1
\mathcal{W}_{i, j}=\left\{\begin{array}{ll}0, & \mathcal{S}_{i, j}<\theta_{1} \\1, & \mathcal{S}_{i, j} \geq \theta_{1}\end{array}\right.
Wi,j={0,1,Si,j<θ1Si,j≥θ1
通过上述操作,两张图片之间就可以被定义为一个积极对(positive pair)如果它们的余弦相似度大于
θ
1
\theta_1
θ1,否则,就是一个消极对(negetive pair)。给定两两监督,我们就可以用二元交叉熵训练模型:
L
p
p
l
=
−
1
(
n
u
)
2
∑
i
,
j
(
W
i
,
j
log
S
i
,
j
+
(
1
−
W
i
,
j
)
log
(
1
−
S
i
,
j
)
)
,
∀
i
,
j
∈
{
1
,
2
,
…
,
n
u
}
\begin{array}{l}\mathcal{L}_{p p l}=-\frac{1}{\left(n^{u}\right)^{2}} \sum_{i, j}\left(\mathcal{W}_{i, j} \log \mathcal{S}_{i, j}\right. \\\left.+\left(1-\mathcal{W}_{i, j}\right) \log \left(1-\mathcal{S}_{i, j}\right)\right), \forall i, j \in\left\{1,2, \ldots, n^{u}\right\}\end{array}
Lppl=−(nu)21∑i,j(Wi,jlogSi,j+(1−Wi,j)log(1−Si,j)),∀i,j∈{1,2,…,nu}
伪标签学习(Pseudo-Label Learning) 根据之前的文献证明,图像之间的约束矩阵
W
i
,
j
\mathcal{W}_{i,j}
Wi,j可以实现以下聚类属性:
如果上述二元交叉熵损失得到最优解,则
∀
i
,
j
,
z
^
u
∈
R
C
u
,
z
^
i
u
=
z
^
j
u
⇔
W
i
,
j
=
1
,
a
n
d
,
z
^
i
u
≠
z
^
j
u
⇔
W
i
,
j
=
0
\forall i, j, \hat{z}^{u} \in \mathbb{R}^{C^{u}}, \hat{z}_{i}^{u}=\hat{z}_{j}^{u} \Leftrightarrow \mathcal{W}_{i, j}=1 , and, \hat{z}_{i}^{u} \neq \hat{z}_{j}^{u} \Leftrightarrow \mathcal{W}_{i, j}=0
∀i,j,z^u∈RCu,z^iu=z^ju⇔Wi,j=1,and,z^iu=z^ju⇔Wi,j=0
该属性表明最优的新类分类器的预测向量恰好是
C
u
C^u
Cu多元独热编码。换句话说,无标签数据
D
u
D^u
Du可以自动分到
C
u
C^u
Cu个团中。
基于这一特性,对于未标记的样本,我们将新分类器的预测输出重新表述为一个onehot伪标签,从而进一步提高模型的性能。无标签数据
x
i
u
x^u_i
xiu的onehot伪标签
y
^
i
u
\hat{y}^u_i
y^iu可以通过设置阈值
θ
2
\theta_2
θ2得到:
y
^
i
u
[
j
]
=
{
0
,
z
^
i
u
[
j
]
<
θ
2
1
,
z
^
i
u
[
j
]
≥
θ
2
\hat{y}_{i}^{u}[j]=\left\{\begin{array}{ll}0, & \hat{z}_{i}^{u}[j]<\theta_{2} \\1, & \hat{z}_{i}^{u}[j] \geq \theta_{2}\end{array}\right.
y^iu[j]={0,1,z^iu[j]<θ2z^iu[j]≥θ2
在伪标签学习中,我们只用分配了伪标签的无标签数据训练模型。给定无标签样本的onehot伪标签,我们可以通过交叉熵训练模型:
L
p
l
l
=
−
1
n
^
u
∑
i
log
(
z
^
i
u
)
⊤
⋅
y
^
i
u
,
∀
i
∈
{
Max
(
y
^
i
u
)
=
1
}
\mathcal{L}_{p l l}=-\frac{1}{\hat{n}^{u}} \sum_{i} \log \left(\hat{z}_{i}^{u}\right)^{\top} \cdot \hat{y}_{i}^{u}, \quad \forall i \in\left\{\operatorname{Max}\left(\hat{y}_{i}^{u}\right)=1\right\}
Lpll=−n^u1i∑log(z^iu)⊤⋅y^iu,∀i∈{Max(y^iu)=1}
联合两个损失: 联合伪配对学习和伪标签学习,无监督聚类损失表述为:
L
u
c
=
L
p
p
l
+
λ
1
L
p
l
l
\mathcal{L}_{u c}=\mathcal{L}_{p p l}+\lambda_{1} \mathcal{L}_{p l l}
Luc=Lppl+λ1Lpll
其中
λ
1
\lambda_1
λ1是控制伪标签学习重要性的超参,到此,我们提出了新类发现的Baseline。

OpenMix
在上述baseline中,有标签数据只起到了模型初始化的作用。但是在第二阶段无监督聚类中没有用到有标签数据。这篇论文中,我们认为有标签数据可以提供用于提升无监督聚类性能的重要知识。该部分,我们提出OpenMix用于在无标签数据 D u D^u Du进行无监督聚类期间高效利用有标签数据 D l D^l Dl。简单来说,无监督聚类过程中,OpenMix以两种方式额外混合样本:
- 混合无标签样本和有标签样本;
- 混合无监督样本和可靠锚点。
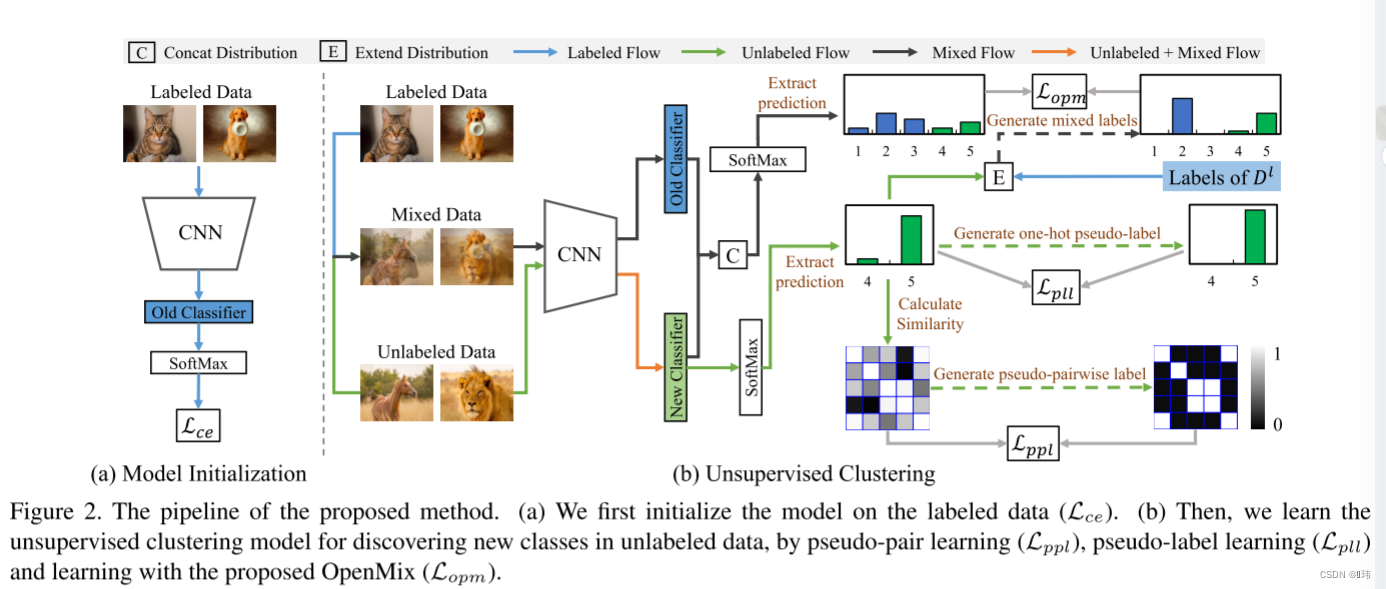
混合有标签样本 在第一种方式中,OpenMix将有标签样本和无标签样本混合,以及混合它们对应的标签和伪标签。首先利用有标签样本和无标签样本属于完全不同类别的先验知识,将有标签样本和无标签样本的标签分布扩展到相同的大小。细节上就是将
y
^
l
\hat{y}^l
y^l和一个
C
u
C^u
Cu维的零向量拼接,同时,将
z
^
l
\hat{z}^l
z^l和一个
C
l
C^l
Cl维的零向量拼接。这种拓展的标签/伪标签中,
y
ˉ
l
\bar{y}^l
yˉl和
y
ˉ
u
\bar{y}^u
yˉu分别表示有标签数据和无标签数据拓展后的标签。接着,我们就可以通过MixUp生成视觉样本:
η
∼
Beta
(
ϵ
,
ϵ
)
,
η
∗
=
Max
(
η
,
1
−
η
)
m
=
η
∗
x
l
+
(
1
−
η
∗
)
x
u
,
v
=
η
∗
y
ˉ
l
+
(
1
−
η
∗
)
y
ˉ
u
\begin{array}{l}\eta \sim \operatorname{Beta}(\epsilon, \epsilon), \eta^{*}=\operatorname{Max}(\eta, 1-\eta) \\m=\eta^{*} x^{l}+\left(1-\eta^{*}\right) x^{u}, \quad v=\eta^{*} \bar{y}^{l}+\left(1-\eta^{*}\right) \bar{y}^{u}\end{array}
η∼Beta(ϵ,ϵ),η∗=Max(η,1−η)m=η∗xl+(1−η∗)xu,v=η∗yˉl+(1−η∗)yˉu
其中
ϵ
\epsilon
ϵ为超参,
η
∈
[
0
,
1
]
\eta \in [0,1]
η∈[0,1]。
m
m
m表示生成样本,
v
v
v表示
m
m
m的伪标签。同时
η
∗
\eta^{*}
η∗使得生成样本更靠近
x
l
x^l
xl。这可以额缓解无标签样本的不可靠伪标签带来的负面影响。
混合样本在旧类别中具有完全真实的置信度,在新类别中具有中等置信度。这得益于先验知识,即有标签样本的标签完全正确,有标签样本与无标签样本的类别完全不同。因此,通过OpenMix将有标签样本与无标签样本进行混合,混合样品的伪标签会比无标签样本的伪标签更可靠。混合样本学习可以帮助防止模型对分配了错误伪标签的无标签样本进行过拟合。
**混合可靠锚点: ** 通过用第一阶段生成的样本训练,我们发现对于具有高分类概率的无标签样本,该模型保持了相当高的准确性。基于以上观察,在第二种方法中,我们选择具有高分类概率的无标签样本作为可靠锚点。接着,我们将这些锚点和无标签样本通过OpenMix混合,我们通过在上述生成混合样本中用一个可靠的锚替换有标签数据 x l x^l xl来执行这个操作。
**OpenMix损失: ** 给定混合样本
M
\mathcal{M}
M及对应的伪标签
V
\mathcal{V}
V,我们用2-范数损失训练模型:
L
opm
=
1
∣
M
∣
∑
1
C
l
+
C
u
∥
v
i
−
SoftMax
(
z
i
m
)
∥
2
\mathcal{L}_{\text {opm }}=\frac{1}{|\mathcal{M}|} \sum \frac{1}{C^{l}+C^{u}}\left\|v_{i}-\operatorname{SoftMax}\left(z_{i}^{m}\right)\right\|_{2}
Lopm =∣M∣1∑Cl+Cu1∥vi−SoftMax(zim)∥2
OpenMix具有以下优点:
- 通过混合有标签和无标签样本,混使得合伪标签在已知类和新类上至少包含一部分正确标签,从而有效地消除了未标签样本的不正确伪标签;
- 已知类和新类的联合分布在训练过程中注入了额外的弱监督,即标记/未标记数据不是新类/已知类,这可以抑制伪标签在新类上的错误。以上两个方面使我们的OpenMix能够提供更加稳定可靠的训练。
总体损失
通过联合baseline和所提出的OpenMix,总体损失表述为:
L
a
l
l
=
L
u
c
+
λ
2
L
o
p
m
\mathcal{L}_{a l l}=\mathcal{L}_{u c}+\lambda_{2} \mathcal{L}_{op m}
Lall=Luc+λ2Lopm
其中
l
a
m
b
d
a
2
lambda_2
lambda2平衡OpenMix的权重。
在我们的方法中还考虑了变换一致性的约束。这个约束假设对图像
x
x
x的预测和它的变换对应物
x
′
x '
x′应该是相同的。我们不是直接最小化
x
x
x和
x
′
x '
x′的预测之间的差异,而是遵循对转换后的对应对象
x
′
x '
x′额外执行我们的方法的约束。具体地说,在每次训练迭代中,我们对图像及其对应的变换使用相同的伪两两标签和一热伪标签。我们的方法的最终损失可以重新表述为:
L
a
l
l
=
L
u
c
+
λ
2
L
o
p
m
+
L
u
c
′
+
λ
2
L
opm
′
\mathcal{L}_{a l l}=\mathcal{L}_{u c}+\lambda_{2} \mathcal{L}_{o p m}+\mathcal{L}_{u c}^{\prime}+\lambda_{2} \mathcal{L}_{\text {opm }}^{\prime}
Lall=Luc+λ2Lopm+Luc′+λ2Lopm ′
式中,
L
u
c
′
\mathcal{L}_{u c}^{\prime}
Luc′和
L
opm
′
\mathcal{L}_{\text {opm }}^{\prime}
Lopm ′为变换后的未标记样本的损失。在测试过程中,我们使用新的分类器来预测无标签样本的类别。
















 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











