






引言:3D目标检测在数据标注阶段会耗费大量的人力和物力。所以为了降低标注成本,半监督学习越来越受到人们的关注。半监督学习的特点在于,它可以依赖少量的标注数据和大量的未标注数据进行训练,大大缓解了注释大量数据集的压力。
半监督学习的基本流程:一般采用的是教师-学生模型,首先使用少量的标记数据对教师模型进行预训练,得到具有初步检测能力的模型。之后将未标记数据通过教师模型进行预测,得到大量伪标签数据。通过数据增强技术,增强输入数据的鲁棒性,输入到学生模型进行预测,计算模型的分类损失,并依据损失进行学生模型的权重更新,通过EMA进行教师模型的更新,循环往复,进行训练。总结来说,教师指导学生学习,学生给予教师反馈,进行更好的学习,提高检测能力,学生模型是主要的检测头。
Reliable Student,高效地解决了半监督3D目标检测中的噪声问题。半监督3D目标检测模型的好坏,与伪标签的质量好坏有很大关系。当然基于置信度的过滤来提高伪标签的质量是很好的研究方向。但是不可避免的总是存在噪声伪标签,即错误的伪标签。主要包括假阳性错误和假阴性错误。
假阳性错误:就是把无关的事物判断成为了正确的事物,举例来说,如果是行人检测,就是把人形玩偶判断成为了人类。
假阴性错误:简单讲是“漏报”,举例来说,如果是行人检测,就是没有把行人识别为人。
Reliable Student结合两种互补的方法来减轻误差,一是classs-aware target assignment strategy,二是Reliability Weight Assignment.
Reliable Student的结构图如下:
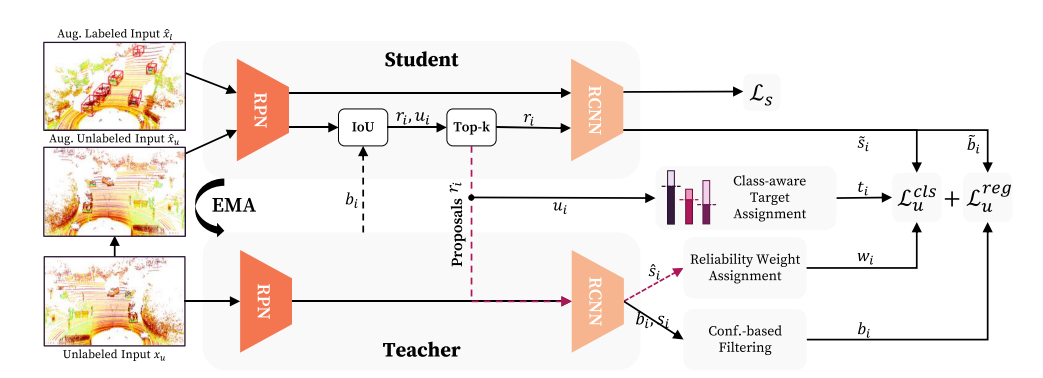
结构图介绍(系论文原文介绍):
框架包括一个教师网络和一个学生网络。教师网络接收基于当前数据集的未标记数据生成预测结果(高质量伪标签)bi ,随后计算教师网络生成的伪标签边界框bi与学生网络处理后的候选边界框ri之间的交并比(IOU)ui,基于IOU值ui,对学生网络的候选边界框ri进行Top-k采样,选择IOU值最高的k个边界框。这一步骤的目的是选取与教师网络最为接近的候选边界框,以便更有效地进行后续的学习和优化。
将采样后的边界框ri(proposals ri)注入到学生网络和教师网络的RCNN头部,分别预测这些边界框的物体性得分(objectness socres)^si。
学生网络的物体性得分objectness scores则直接被用作RCNN分类损失Lcls_u的输入,来优化学生网络的分类能力。
教师网络的objectness scores被转换为可靠性权重wi,用于调整RCNN分类损失Lcls_u中的样本权重。进一步使得框架能偶关注更可靠的伪标签,减少噪声对训练过程的影响。
Class-aware Target Assignment(类感知的目标分配模块):
针对不同的类别,设定不同的IOU阈值,利用这些阈值与IOU值ui来为学生网络的候选框分配物体性目标ti(就是正确的类别标签)。目的是为了更加精细化的目标分配,提高训练的效率和效果。 具体来说,对于每个预测框ri,会根据其计算的IOU值以及所属类别,使用对应的类别阈值来判定其是否被标记为前景(FG)或者背景(BG).每个类别的预测框会根据其自身特性来设定更合适的阈值,提高目标分配的准确性。
IOU:
只有IOU值达到一定阈值的候选框才会被视为正样本,用于分类损失计算。有助于增强学生网络对不同类别目标的识别能力。
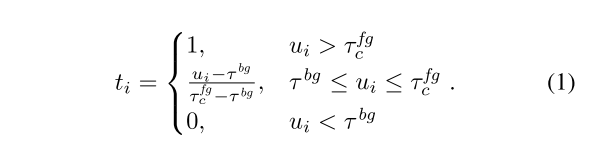
Tbg 指的是背景预测框,ui就是指预测框与真实框的交并比(IOU),Tfgc是指局部前景阈值,如果ri与真实框的IOU值大于tfgc,则ri被视为前景(FG),否则被视为背景(BG).
在实现了特定于类别的局部阈值后,仍然不可避免地会导致假阴性(FN)和假阳性(FP)错误的发生。
为了研究FG、UC(不确定)、BG类别中的预测框如何受到FP和FN错误的影响,文章中给出了密度图,显示了区域兴趣ROI与预测标签(Predicted Labels PLs)和真实标签(Ground Truths,GTS)之间的交并比(IOU)分布。从右到左将图分为三列,FG、UC和BG部分。
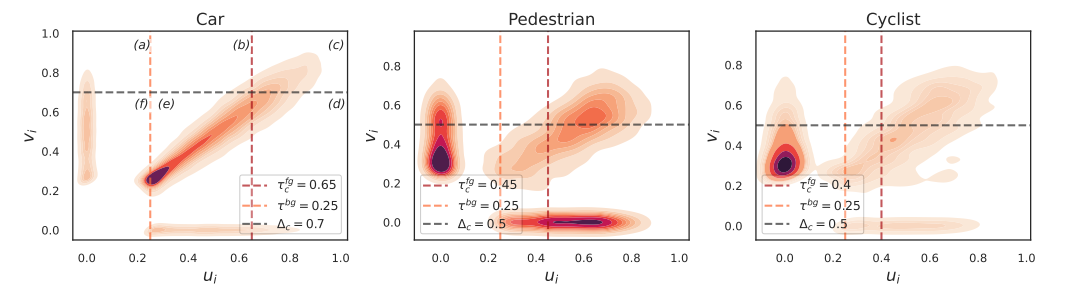
密度图解释:
- 提议:指的就是潜在的边界框。
- x轴和y轴:x轴表示提议与预测标签PL之间的IOU值,y轴表示提议与真实标签(GT)之间的IOU值。
- 颜色深浅:密度较高的区域用较深的颜色表示,这反映了在该IoU值范围内的提议数量较多
- 垂直线:
-
- 红色垂直线表示局部前景(FG)阈值(τfg_c),用于区分前景和不确定区域。
- 橙色垂直线表示局部背景(BG)阈值(τbg),用于区分不确定和背景区域。
- 水平黑线:表示评估模式下的前景阈值(Δc),它将图表分为六个子区域,用于进一步分析不同类型的提议。
子区域分析
- (a) 区域:表示假负例(FN)提议,即模型未能正确识别出真实前景对象,将其错误地分类为背景或不确定区域。
- (f) 区域:表示真负例(TN)提议,这些提议在真实标签中也是背景,且模型也正确地将其分类为背景。然而,在这个可视化中,通常不特别关注TN提议,因为它们对模型性能的提升没有直接影响。
- (b) 和 (e) 区域:表示位于不确定区域的提议,这些提议的IoU值既不过高也不过低,使得模型难以确定它们是否属于前景。这些提议在训练过程中可能会被赋予软目标(soft targets),以帮助模型更好地学习区分前景和背景。
- (c) 区域:表示真正例(TP)提议,即模型正确地识别出前景对象。
- (d) 区域:表示假正例(FP)提议,即模型错误地将背景区域或不确定区域预测为前景。、
Reliability Weight Assignment 加权RCNN分类损失:
在训练过程中,教师网络的置信度评分被用来加权RCNN的分类损失。这意味着在计算损失时,模型会根据不同提案的置信度来调整损失的影响力。
**前景(FG)**提案:这类提案是指真实目标,通常会被赋予较高的权重,以确保模型更关注于正确识别目标。
**不确定(UC)**提案:这些提案的置信度较低,可能会对模型产生负面影响,因此可以选择降低其权重,以减少对模型训练的干扰。
**背景(BG)**提案:这些提案通常是错误的或不相关的,权重也会相应降低,以避免模型学习到不必要的信息。
作者引入了Soft Teacher方法提出的可靠性评分,利用教师模型的预测来指导学生模型的训练,通过一种软标签(soft label)机制来处理不确定的预测。它能够为每个提议分配一个介于0和1之间的分数,表示该提议作为前景或者背景的置信度。
具体来说,在学生模型的提议发送到教师模型之前,首先对学生提议应用一种逆增强操作h,以此来消除训练学生模型时可能应用的数据增强效果,教师模型然后利用ROI池化模块对每个学生提议ri进行细化,并预测出一个细化的边界框bi和一个置信度分数^si。这里的置信度分数^si代表了细化的边界框提议作为前景目标的概率, 用于学生提议ri的可靠性评分。基于教师模型的置信度分数^si,对未标记样本的RCNN分类损失进行加权。















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









