






【10大专题,2.8w字详解】:从张量开始到GPT的《动手学深度学习》要点笔记
线性回归

线性回归是一种单层神经网络。
线性回归方法的四个关键式子:
-
线性模型的预测公式:
y ^ = X w + b \hat{y} = Xw + b y^=Xw+b
这个公式表示向量 y ^ \hat{y} y^(预测值)是矩阵 X X X(特征)和向量 w w w(权重)的乘积加上偏置项 b b b。这里, X ∈ R n × d X \in R^{n \times d} X∈Rn×d,其中 n n n 是样本数量, d d d 是特征数量。 -
每个样本的平方误差损失:
l ( i ) ( w , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 l^{(i)}(w, b) = \frac{1}{2} (\hat{y}^{(i)} - y^{(i)})^2 l(i)(w,b)=21(y^(i)−y(i))2 -
整个数据集的平均损失:
L ( w , b ) = 1 n ∑ i = 1 n l ( i ) ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w T x ( i ) + b − y ( i ) ) 2 L(w, b) = \frac{1}{n} \sum_{i=1}^{n} l^{(i)}(w, b) = \frac{1}{n} \sum_{i=1}^{n} \frac{1}{2} (w^T x^{(i)} + b - y^{(i)})^2 L(w,b)=n1i=1∑nl(i)(w,b)=n1i=1∑n21(wTx(i)+b−y(i))2 -
最优参数的求解:
( w ∗ , b ∗ ) = arg min w , b L ( w , b ) (w^*, b^*) = \arg \min_{w,b} L(w, b) (w∗,b∗)=argw,bminL(w,b)
随机梯度下降方法求解线性回归问题:
- 指定超参数,本问题中是批量大小和学习率。
- 初始化模型参数的值,如从均值为0、标准差为0.01的正态分布中随机采样,偏置参数初始化为零。
- 从数据集中随机抽取小批量样本且在负梯度的方向上更新参数,并不断迭代这一步骤。
w ← w − η ∣ B ∣ ∑ i ∈ B ∂ l ( i ) ( w , b ) ∂ w = w − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w T x ( i ) + b − y ( i ) ) w \leftarrow w - \frac{\eta}{|B|} \sum_{i \in B} \frac{\partial l^{(i)}(w, b)}{\partial w} = w - \frac{\eta}{|B|} \sum_{i \in B} x^{(i)} \left( w^T x^{(i)} + b - y^{(i)} \right) w←w−∣B∣ηi∈B∑∂w∂l(i)(w,b)=w−∣B∣ηi∈B∑x(i)(wTx(i)+b−y(i))
b ← b − η ∣ B ∣ ∑ i ∈ B ∂ l ( i ) ( w , b ) ∂ b = b − η ∣ B ∣ ∑ i ∈ B ( w T x ( i ) + b − y ( i ) ) b \leftarrow b - \frac{\eta}{|B|} \sum_{i \in B} \frac{\partial l^{(i)}(w, b)}{\partial b} = b - \frac{\eta}{|B|} \sum_{i \in B} \left( w^T x^{(i)} + b - y^{(i)} \right) b←b−∣B∣ηi∈B∑∂b∂l(i)(w,b)=b−∣B∣ηi∈B∑(wTx(i)+b−y(i))
Softmax回归

softmax回归是一种单层神经网络。
softmax回归方法的四个关键式子:
-
Softmax函数的定义:softmax函数将一个实数向量转换为概率分布。对于每个元素,它计算该元素的指数与所有元素的指数之和的比值。这样可以确保输出向量的所有元素都是非负的,并且总和为1,因此可以被视为概率分布。
y ^ = softmax ( o ) 其中 y ^ j = exp ( o j ) ∑ k exp ( o k ) \hat{y} = \text{softmax}(o) \quad \text{其中} \quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)} y^=softmax(o)其中y^j=∑kexp(ok)exp(oj) -
输出就是选择最有可能的类别:尽管softmax函数改变了输出向量的值,但它不改变元素之间的顺序。
arg max j y ^ j = arg max j o j \arg \max_j \hat{y}_j = \arg \max_j o_j argjmaxy^j=argjmaxoj -
交叉熵损失:在多分类问题中,模型预测的概率分布为 y ^ \hat{y} y^,而真实的标签分布为 y y y。交叉熵损失函数用于度量这两个分布之间的差异。公式如下:
l ( y , y ^ ) = − ∑ j = 1 q y j log y ^ j l(y, \hat{y}) = -\sum_{j=1}^{q} y_j \log \hat{y}_j l(y,y^)=−j=1∑qyjlogy^j -
交叉熵损失的导数:损失函数的梯度是模型预测的概率与真实标签之间的差异。
∂ ∂ o j l ( y , y ^ ) = softmax ( o ) j − y j \frac{\partial}{\partial o_j} l(y, \hat{y}) = \text{softmax}(o)_j - y_j ∂oj∂l(y,y^)=softmax(o)j−yj
多层感知机

一个单隐藏层的多层感知机,具有5个隐藏单元。
从线性到非线性
如果我们只是将输入通过仿射变换(线性变换和偏置)传递给隐藏层,然后再将隐藏层的输出通过仿射变换传递给输出层,那么整个模型仍然是一个仿射函数,这并没有比单层模型提供更多的表达能力。
为了使多层模型能够表达更复杂的函数,我们需要在隐藏层的仿射变换后应用一个非线性的激活函数
σ
\sigma
σ。这样,模型的计算公式变为:
H
=
σ
(
X
W
(
1
)
+
b
(
1
)
)
H = \sigma(XW^{(1)} + b^{(1)})
H=σ(XW(1)+b(1))
O
=
H
W
(
2
)
+
b
(
2
)
O = HW^{(2)} + b^{(2)}
O=HW(2)+b(2)
常用的激活函数
-
ReLU 的求导表现特别好:要么让参数消失,要么让参数通过。当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题。其数学定义如下:
ReLU ( x ) = max ( x , 0 ) \text{ReLU}(x) = \max(x, 0) ReLU(x)=max(x,0)

-
Sigmoid函数 是一种常用的激活函数,它将实数输入映射到(0, 1)的范围内,因此也被称为挤压函数。sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。它的数学定义如下:
sigmoid ( x ) = 1 1 + exp ( − x ) \text{sigmoid}(x) = \frac{1}{1 + \exp(-x)} sigmoid(x)=1+exp(−x)1

-
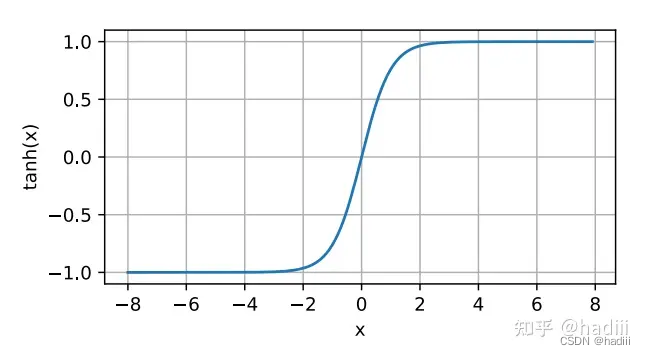
双曲正切函数(tanh) 是另一种常用的激活函数,它将实数输入映射到(-1, 1)的范围内。tanh函数是关于原点对称的。它的数学定义如下:
tanh ( x ) = 1 − exp ( − 2 x ) 1 + exp ( − 2 x ) \text{tanh}(x) = \frac{1 - \exp(-2x)}{1 + \exp(-2x)} tanh(x)=1+exp(−2x)1−exp(−2x)
















 2313
2313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









