






目录
MDP(马儿可夫决策过程)Markov Decision Process
基础知识
MDP(马儿可夫决策过程)Markov Decision Process
MDP(Markov Decision Process)是一种数学框架,用于描述具有随机性和序列决策的问题。在MDP中,智能体(agent)通过与环境的交互,不断地采取行动和观察环境的反馈,从而学习在不同状态下采取最优行动的策略。MDP通常用于强化学习领域中。
MDP包含以下几个要素:
状态(state):智能体在某个时刻所处的状态。
行动(action):智能体在某个状态下采取的行动。
奖励(reward):智能体在某个状态下采取某个行动后获得的奖励或惩罚。
转移概率(transition probability):智能体从一个状态转移到另一个状态的概率。
折扣因子(discount factor):用来衡量未来奖励的价值,通常取值在0到1之间。
策略(policy):智能体在每个状态下采取行动的规则。

在MDP中,智能体的目标是找到一个最优策略,使得其在长期累计的奖励最大化。为了达到这个目标,智能体需要通过试错学习出不同状态下采取不同行动的价值,并根据这些价值来选择最佳行动。值函数(value function)和Q函数(Q function)是MDP中常用的表示价值的函数。
强化学习的要素与架构
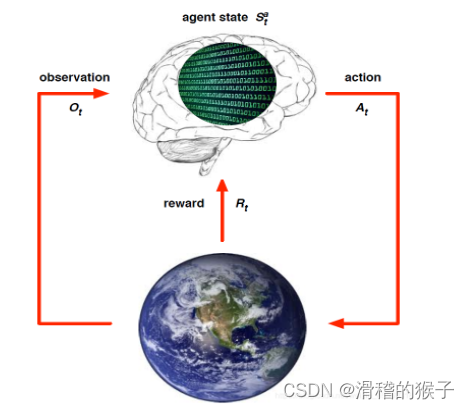
强化学习系统一般包括四个要素:策略(policy),奖励(reward),价值(value)以及环境或者说是模型(model)。
策略(Policy):策略定义了智能体对于给定状态所做出的行为
奖励(Reward):奖励信号定义了强化学习问题的目标
价值(Value):或者说价值函数,与奖励的即时性不同,价值函数是对长期收益的衡量
环境(模型):外界环境,也就是模型(Model),它是对环境的模拟
强化学习的架构

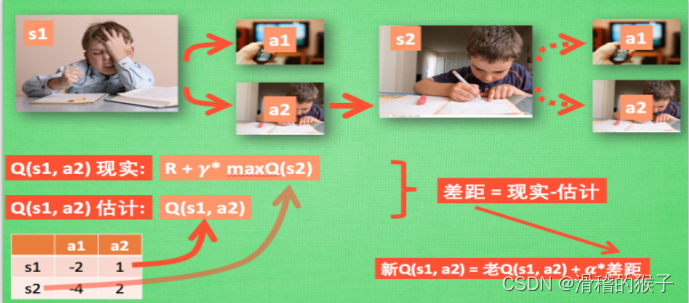
算法思想
Q-learning 算法是一种基于值迭代的强化学习算法,用于学习一个智能体与环境交互的最优策略。该算法的基本思想是通过学习一个 Q-value 函数来指导行动选择。Q-value 函数表示在某个状态下,采取某个行动所获得的期望回报。
在 Q-learning 算法中,智能体通过与环境交互,不断更新 Q-value 函数。具体地,智能体在每个时间步 t 时观察当前状态 s_t,根据当前状态和 Q-value 函数选择一个行动 a_t,执行行动后观察到下一个状态 s_{t+1} 和相应的奖励 r_{t+1},并根据 Q-learning 更新规则更新 Q-value 函数。更新规则如下:
Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
其中,Q(s,a) 表示在状态 s 采取行动 a 的 Q-value,表示当前行动的价值,α 是学习率,γ 是折扣因子,maxa′Q(s′,a′) 表示在下一个状态 s′ 采取最优行动所获得的最大 Q-value。
Q-learning 算法的核心思想是通过不断更新 Q-value 函数来指导行动选择,最终学习出一个最优策略。在实际应用中,该算法需要对状态空间和行动空间进行离散化,以便将其表示为一个 Q-value 表格。同时,为了增加算法的稳定性和收敛速度,可以采用经验回放和探索策略等技巧。

代码
更新规则
def get_update(row, col, action, reward, next_row, next_col):
#target为下一个格子的最高分数,这里的计算和下一步的动作无关
target = 0.9 * Q[next_row, next_col].max()
#加上本步的分数
target += reward
#value为当前state和action的分数
value = Q[row, col, action]
#根据时序差分算法,当前state,action的分数 = 下一个state,action的分数*gamma + reward
#此处是求两者的差,越接近0越好
update = target - value
#这个0.1相当于lr
update *= 0.1
return update
get_update(0, 0, 3, -1, 0, 1)训练
def train():
for epoch in range(1500):
#初始化当前位置
row = random.choice(range(4))
col = 0
#初始化第一个动作
action = get_action(row, col)
#计算反馈的和,这个数字应该越来越小
reward_sum = 0
#循环直到到达终点或者掉进陷阱
while get_state(row, col) not in ['terminal', 'trap']:
#执行动作
next_row, next_col, reward = move(row, col, action)
reward_sum += reward
#求新位置的动作
next_action = get_action(next_row, next_col)
#计算分数
update = get_update(row, col, action, reward, next_row, next_col)
#更新分数
Q[row, col, action] += update
#更新当前位置
row = next_row
col = next_col
action = next_action
if epoch % 100 == 0:
print(epoch, reward_sum)
train()完整代码:在4时序查分算法中https://download.csdn.net/download/qq_46684028/88076627
















 62
62











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











