






发布:2024年 WACV
论文:WACV 2024 Open Access Repository (thecvf.com)
代码:https://github.com/AkideLiu/BPKD
摘要
当前语义分割中的知识蒸馏方法倾向于采用一种整体方法,平等对待所有空间位置。然而,对于密集预测,由于上下文信息泄露,学生对边缘区域的预测具有高度的不确定性,需要比人体区域更高的空间敏感性知识。为了应对这一挑战,提出了一种名为边界特权知识蒸馏(BPKD)的新方法。从教师模型的主体和边缘分别提取知识到紧凑的学生模型。具体而言,采用了两个不同的损失函数:(i)edge loss,旨在在边缘区域的像素级别上区分模糊类别;(ii)body loss,利用形状约束,选择性地关注内部语义区域。实验结果表明,提出的BPKD方法对边缘和人体区域提供了广泛的细化和聚合。此外,该方法在三个流行的基准数据集上取得了最先进的语义分割蒸馏性能,突出了其有效性和泛化能力。BPKD在各种轻量级分割结构(包括cnn和transformer)上表现出一致的改进,突出了其与架构无关的适应性。
Introduce
当前深度模型存在的问题:具有大量参数的深度学习模型在语义分割方面取得了显著的性能。然而,由于模型的计算复杂度较高,这些模型对于移动设备和机器人等资源受限的设备是不切实际的。
语义分割轻量级模型:MobileNet、ShuffleNet和EfficientNet
语义分割的开创性知识蒸馏方法:更关注捕获像素、通道和图像之间的相关信息。
- 《Structured Knowledge Distillation for Semantic Segmentation》表明语义分割中的隐藏知识是通过结构化表示构建的。结构化知识更适合成对相似度缩减和整体蒸馏。
- IFVD《Intra-class Feature Variation Distillation for Semantic Segmentation》建议根据语义掩码对知识进行编码。
- 在 CWD《Channel-wise Knowledge Distillation for Dense Prediction》中,作者通过强调对齐教师和学生之间每个通道最显着的区域来细化蒸馏。
在语义分割任务中,图像的边界区域通常包含细粒度的信息,这些信息对于精确的分割结果至关重要。这些研究主要关注在整个图像上传递知识表示,忽略了不同空间位置上不同知识表示的重要性。在学习边缘特征时,模型聚合相邻类类别之间的上下文信息,导致上下文信息泄漏。
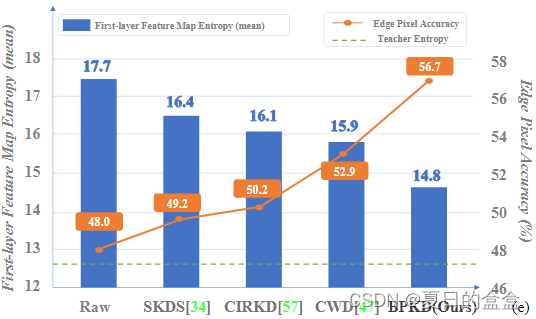
如下图b, c, d)所示,目前的全视图蒸馏方法在边缘区域表现出高水平的不确定性,以及更高水平的熵:
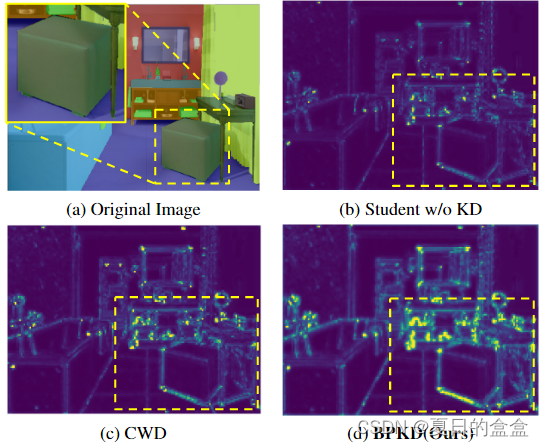
如下图所示,目前的方法在边缘像素上存在较高的不确定性和较低的精度,表明上下文信息泄漏现象:
为了解决现有方法中上下文信息学习问题,我们提出了一种新的方法,称为边界特权知识蒸馏(BPKD)。我们将知识蒸馏过程分为两个小节:边缘蒸馏和身体蒸馏部分。我们提出的 BPKD 方法通过解耦知识蒸馏和使用教师软标签来明确提高边缘区域和对象边界的质量。边缘蒸馏损失涉及上下文信息的空间概率对齐和聚合来细化边界。此外,边界提供了对对象内部区域形状的先验知识,并且身体区域可以利用这些知识来消除高不确定性边界样本并平滑学习曲线。因此,我们观察到由于隐式形状约束,对象中心受到更大的关注,进一步提高了体区域的分割。
具体来说,与专门的实时分割方法相比,我们减少了学生网络和教师网络之间的性能差异。
主要贡献:
- 我们表明,当前的蒸馏方法通过分析低级特征的不确定性存在上下文信息泄漏问题,导致边界处的分割性能不是最优的。据我们所知,这是第一篇在知识蒸馏文献中识别语义分割的关键问题的论文。
- 我们提出了一种新的知识蒸馏方法,该方法分别侧重于提取与物体身体和边缘相关的信息。我们的专用边缘损失函数显着提高了边缘切片的质量,同时对身体区域施加强烈的形状约束。这种方法有效地最小化了不确定性,防止了蒸馏过程中的上下文信息泄漏,并放大了对内部区域的关注。
- 我们的方法在三个流行的基准数据集上实现了最先进的结果。与之前的 SOTA CWD 相比,我们报告平均交集比联合 (mIoU) 增加高达 4.02%。此外,我们观察到边缘和身体区域的预测质量显着提高,进一步证明了我们的有效性。
Related Work
语义分割:
- 语义分割方法主要利用全卷积网络(FCNs)、PSPNet和DeepLab系列等
- 使用金字塔池模块(PPM)和atrous空间金字塔池(ASPP)等先进技术来捕获多尺度上下文
- HRNet进一步创新了一个并行主干,用于高分辨率特征维护
- ENet、SqueezeNet和 ESPNet等轻量级模型获得了吸引力。这些模型使用早期下采样、滤波分解和高效空间金字塔等策略来减少计算开销。
- MobileNet 变体也可以有效地进行分割
边缘检测:
- 经典的边缘检测算法如Canny、Sobel和Prewitt已经被改造成现代深度学习架构,以实现细粒度分割。
- HED和RCF等深度监督边缘检测方法直接将多尺度边缘信息引入到分割管道中
- 类似地,像 CASENet这样的模型通过将特定于类的边融合到分割算法中,提高了最先进的技术,为详细的边界表示和类区分提供了双重好处。
- 同时,边缘注意模型等技术通过基于边界重要性对特征进行加权来合并边缘信息,从而在语义分割中实现更精细的轮廓映射。
知识蒸馏:
- 知识蒸馏(KD)旨在将一个或多个扩展教师模型的学习浓缩为精简的学生模型。
- KD技术主要应用于基本视觉任务,可分为基于响应、基于特征的范式和基于关系的范式。基于响应的方法,主要由 Hinton 等人发起。
- 最小化 Kullback-Leibler 散度以传达隐含的高价值知识。
- FitNet等基于特征的方法对齐教师和学生之间的内部特征激活,
- 而基于关系的方法深入研究层间或样本间关系。
- 传统的KD在很大程度上倾向于图像分类,在像素级分割任务中的效用有限。
最近的进展已经看到了 KD 方法为语义分割量身定制拟合:
- structural knowledge distillation等策略将分割定义为结构化预测任务,对知识转移采用成对相似性和整体对抗增强。
- Channel-wise蒸馏专注于显著的通道区域。
- 其他创新包括类内特征变异蒸馏,它结合了像素级和类变化,以及优化全局语义互连的跨图像关系蒸馏。
- mask生成蒸馏利用教师指导进行特征恢复。
- 最近的工作表明 Pearson 相关性作为一种可行的 KL 散度替代方案。
- 实证验证证实了这些专门的KD技术在提高语义分割性能方面的有效性。
method
BPKD 框架
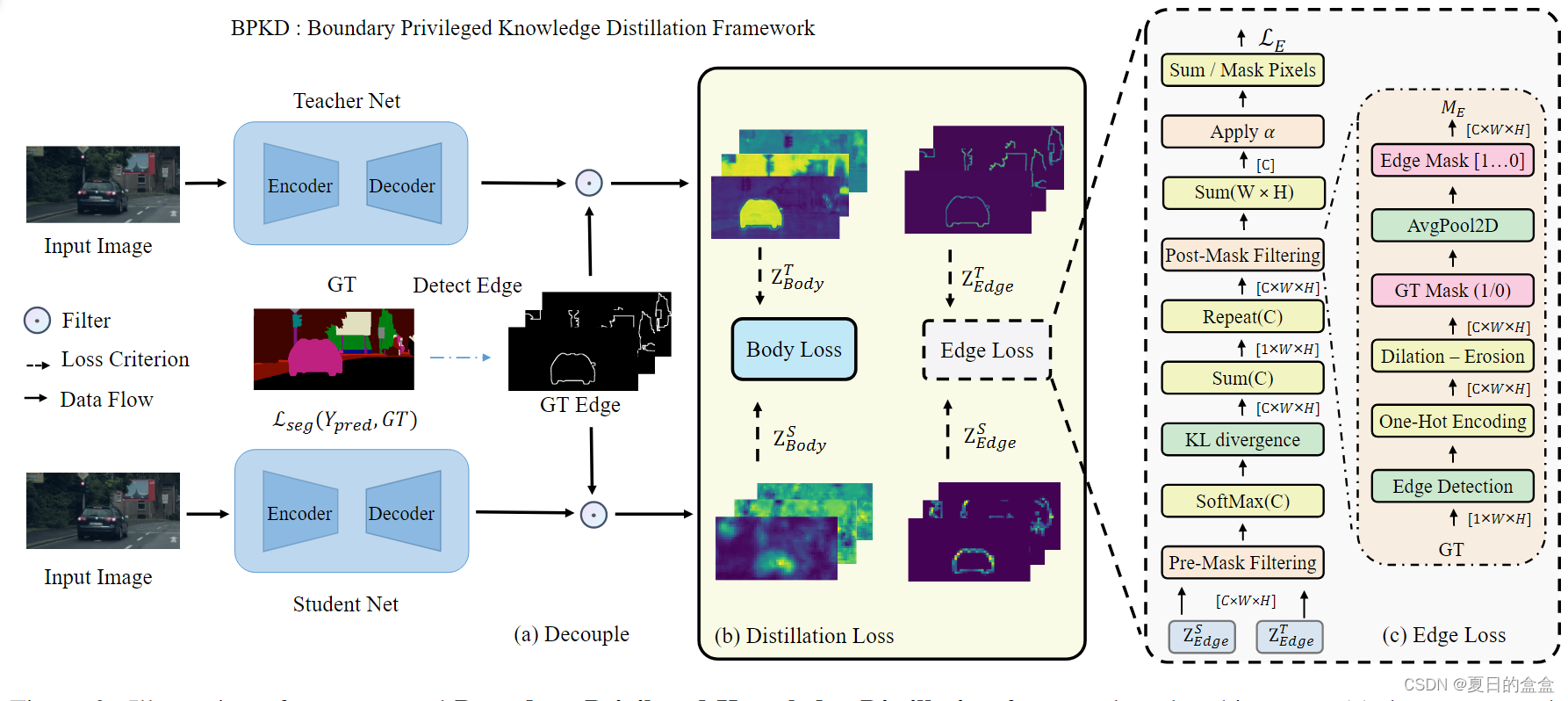
(a) 展示了涉及ground truth边缘检测以生成 Mask 的解耦过程,然后应用掩码过滤器来获得 Teacher 和 Student 的 logits 掩码。这一步确保来自边界区域的信息被隔离并适当地传达给学生。(b) 表明蒸馏包括两个术语:body损失和edge损失。body损失项捕获了分类的相似性,而edge损失项集中在边界区域的转移上。
和
是
和
的缩写词。在
中 , S和T表示学生和教师。(c) 显示了边缘损失计算分两个阶段进行:预掩码过滤和掩码后过滤。预掩码过滤步骤塑造概率分布以仅包含边缘信息。随后,掩码后过滤步骤聚合相邻类别之间的上下文信息,生成最终的边缘损失。
edge损失好处:
-
提取边缘区域单独增强对象边界的质量
-
边缘蒸馏损失为对象的内部区域提供了先验形状知识
body损失好处:
-
通过模仿教师的 logit 概率分布来减少学习难度,因为去除了高不确定性边界
-
通过隐式形状约束在对象中心利用更高的注意力。
框架过程:
-
使用边缘检测技术通过处理地面实况和分割 logit 图来为每个类生成边缘掩码
。令
表示网络的 logit 图,其中 C 对应于通道数,H × W 表示空间分辨率。
-
边缘掩码
和edge组件
,它们遵循加法规则,表示为
。我们的 BPKD 框架分别将这两个组件中编码的edge和body知识转移到学生。由于边缘切片的知识表示较少,我们引入了一种分类意识来平衡不同特殊视角的重要性。总之,这些技术在提高模型的整体性能方面起着至关重要的作用。
在这项研究中,我们提出了一种新的方法,将蒸馏损失分解为两个不同的分量,即body损失和edge损失
,如公式1所示。我们包括body损失权重
和edge损失权重
来控制每个损失项的贡献。这种解耦策略允许我们检查边缘学习在知识蒸馏过程中的敏感性。
![]()
Edge Knowledge Representation
我们的框架最小化了教师和学生在边缘区域的特征之间的差异。为了实现这一点,我们通过使用软边缘掩码来提取边缘知识表示。该边缘掩码应用于 logit 映射,为教师和学生的边缘区域生成掩码特征表示。边缘图是通过两个阶段创建的:Pre-Mask Filtering (PRM),它捕获所有类别的边缘差异,以及 PostMask Filtering (POM),它为每个单独的类提取边缘差异。这种方法允许模型提取边缘知识更准确和更精确的表示,从而提高细节分类的性能。
在边缘检测过程中,我们采用可调Trimap算法从ground truth (GT)中提取表示的边缘表示。尽管教师的预测可以作为生成边缘掩码的替代来源,但与直接使用 GT 相比,它们提供了略低的准确度。为了生成二值边缘掩模
,我们计算应用于GT的dilation和erosion操作之间的差异,形式上表示为
。生成的二进制掩码
经过平均池化,生成
,其形状与logits预测
相同。ME 的维度由分割网络的输出步幅 S 控制,特别是
。
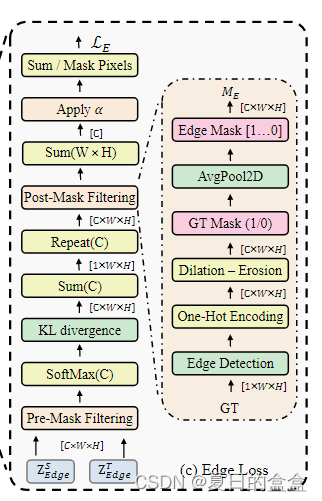
Pre Mask Filtering (PRM)
为了获得 logits 图,我们将应用于学生和教师 logits:
。具体来说,我们对每个通道 C 应用边缘掩码,以便我们可以为重叠边缘区域集中 logits。一个直观的例子是,如果有一帧显示一只狗和一个猫站在附近,只考虑狗和猫类的 logits 激活,所有其他激活都会被抑制。这样的操作迫使学生更多地关注相邻模棱两可的类别之间的相关性。将空间级 KL 散度损失应用于过滤后的
和
:
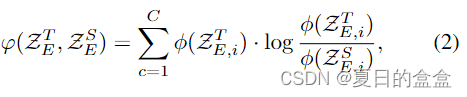
其中
是每个像素的 softmax 操作。
表示所有空间位置的边缘掩码 KL 距离。
Post Mask Filtering (POM)
我们进一步分离每个类的边缘损失,并通过Post Mask Filtering (POM)根据边缘区域进行归一化。令和
分别表示教师和学生模型中像素 i 处第 c 类的 logits。设
为第c类的ground truth二值边缘掩码平均池化得到的软掩码,
为该类
中非零像素的个数。我们的 POM 项可以表示如下:
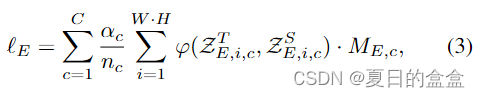
通过基于每个类的边缘区域重新加权损失,我们优先考虑边缘的中心,其中通常定位最重要的信息。这种方法确保学生模型专注于学习每个类的正确边缘位置和形状。
软边缘掩码在 Edge Loss 中起着至关重要的作用,我们生成它们的方法涉及两种专门的设计:1)将二进制
转换为加权离散空间,以及 2)为每个通道生成掩码而不是统一的掩码。直接应用二进制掩码可能包含不自信的偏差,因此我们使用平均池化来生成更软的掩码。我们还仔细考虑重叠掩码以最小化噪声和不确定性。我们的掩码设计旨在专门包含不自信的偏差来最小化知识分布。
总之,边缘区域提出的PRM和POM阶段通过识别每个类的边缘差异并基于边缘区域对损失应用重新加权来细化知识蒸馏过程。这种方法保证学生模型为每个类学习正确的边缘位置和形状,并为身体知识表示提供形状先验知识。
Body Knowledge Representation
本节研究body知识蒸馏。先前的工作考虑了全视图蒸馏,它用边缘上的噪声表示稀释身体知识。为了克服这些挑战,我们利用反向边缘二进制掩码来提取身体掩码。通过删除边缘区域,我们利用隐式形状约束并减少不确定性,这允许身体损失专注于将对象的大内部区域分配给它们对应的类别。为了实现这一点,我们提出了一种区域对齐方法,该方法合成通道级激活以获得语义丰富的部分。正如我们预定义的,。身体 logits 由
获得。如之前的工作所示,由于硬约束,身体区域的像素级损失会带来意想不到的噪声。因此,我们对身体部位采用通道蒸馏的松散约束。身体增强损失 (BEL) 定义为:
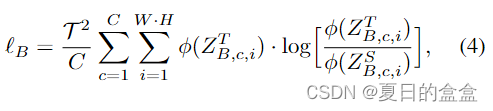
Experiments
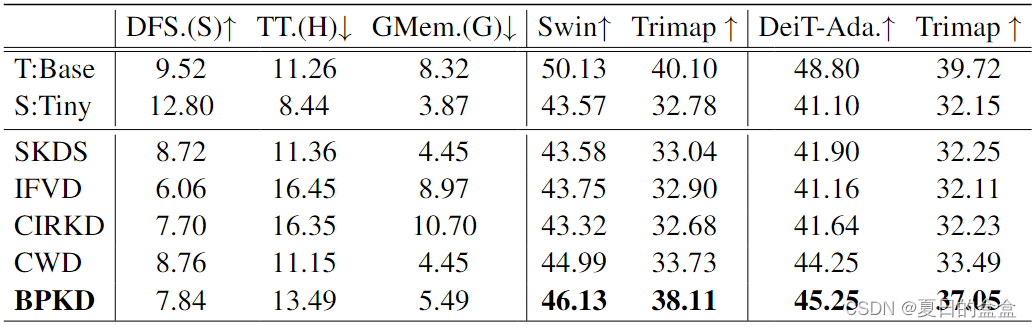
将BPKD方法与各种紧凑的网络进行了基准测试 :以ResNet18为backbone的PSPNet、HRNet-W18、以MobileNetV2为backbone的Deeplab-V3+、以ResNet18为backbone的ISANet、使用 UPerNet的Swin Transformers、使用 UPerNet的DeiT Adapter。
与SOTA相比:
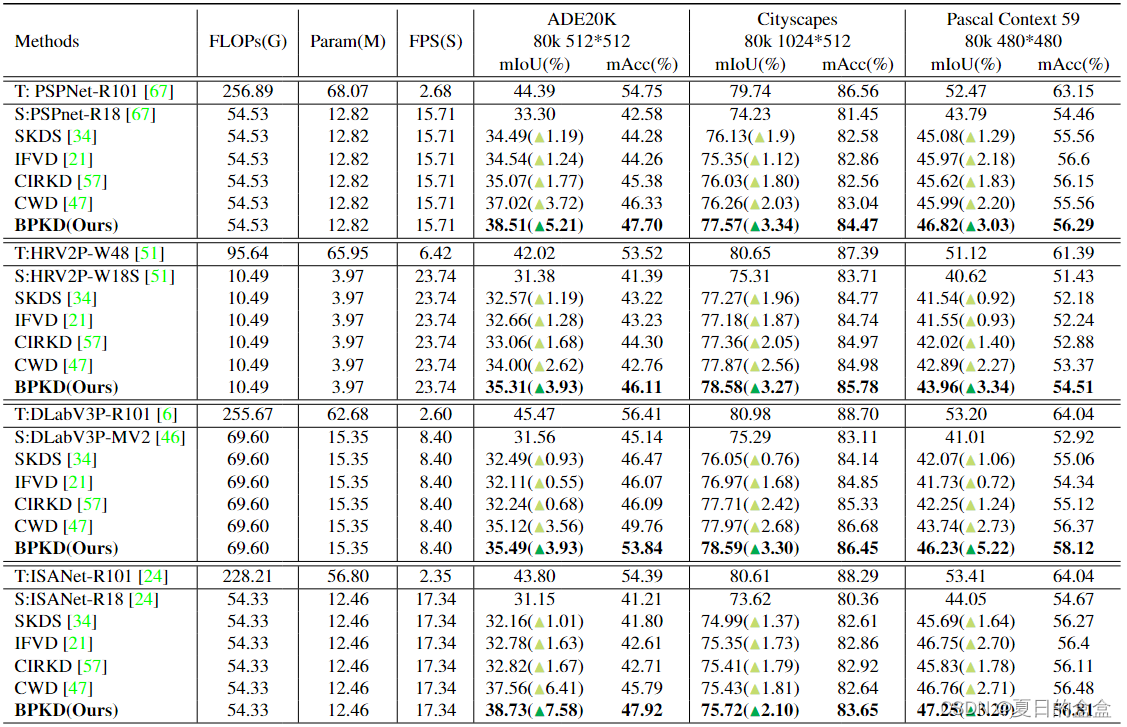
基于transformer的架构与不同蒸馏策略的性能比较 :
Conclusion
本文提出了一种新的边界特权知识蒸馏(BPKD)语义分割方法,该方法将繁琐的教师模型的身体和边缘知识转移到紧凑的学生模型中。大量实验表明,身体和边缘区域的知识表示应该以不同的方式考虑。由于内在属性不同,边缘区域需要专注于区分每个像素的不确定类别,而身体区域需要更多地关注定位和连接对象结构。实验结果表明,所提出的蒸馏方法在各种公共基准数据集上始终优于最先进的方法。边缘区域的整体 mIoU 和性能都大幅提升。

















 5245
5245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









