






1、Transformer
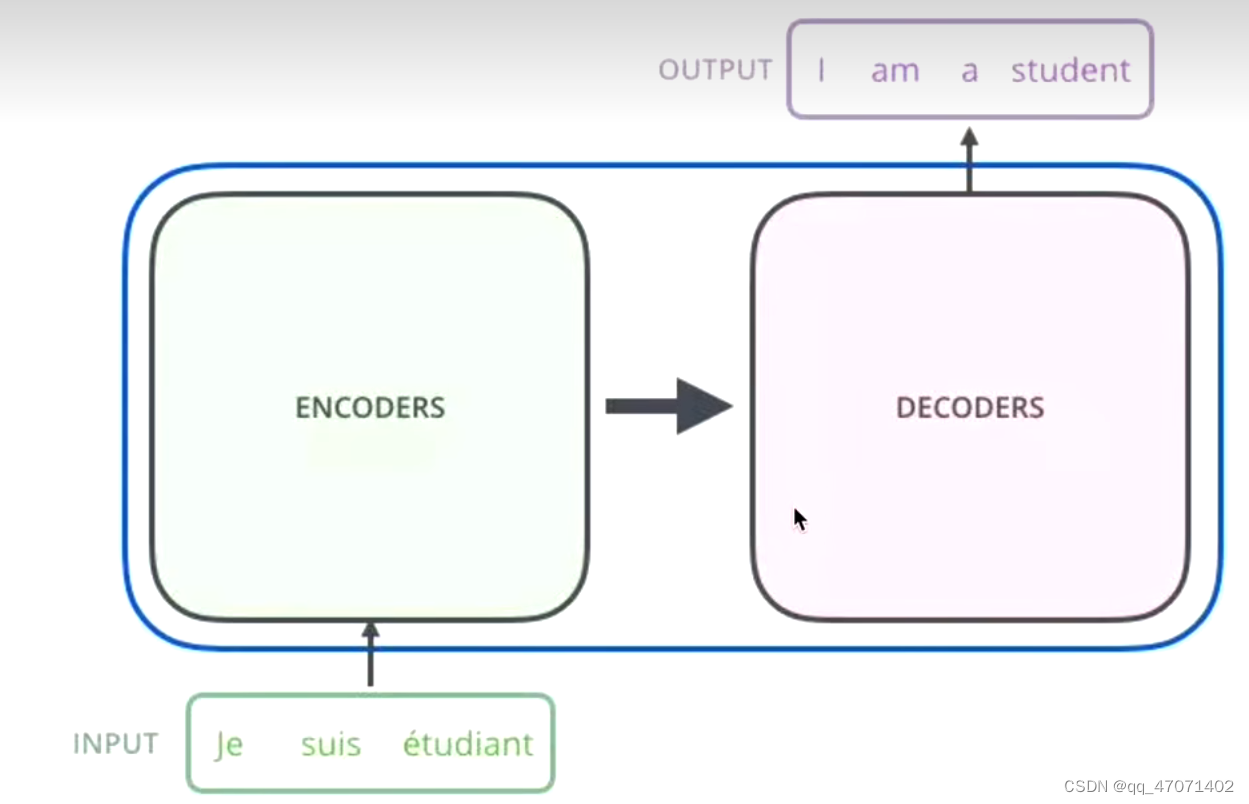
seq2seq模型,序列到序列,分为两部分,编码器和解码器
1、通过编码器对序列进行向量化(词向量)
2、把词向量输入到解码器,得到结果(生成单词)
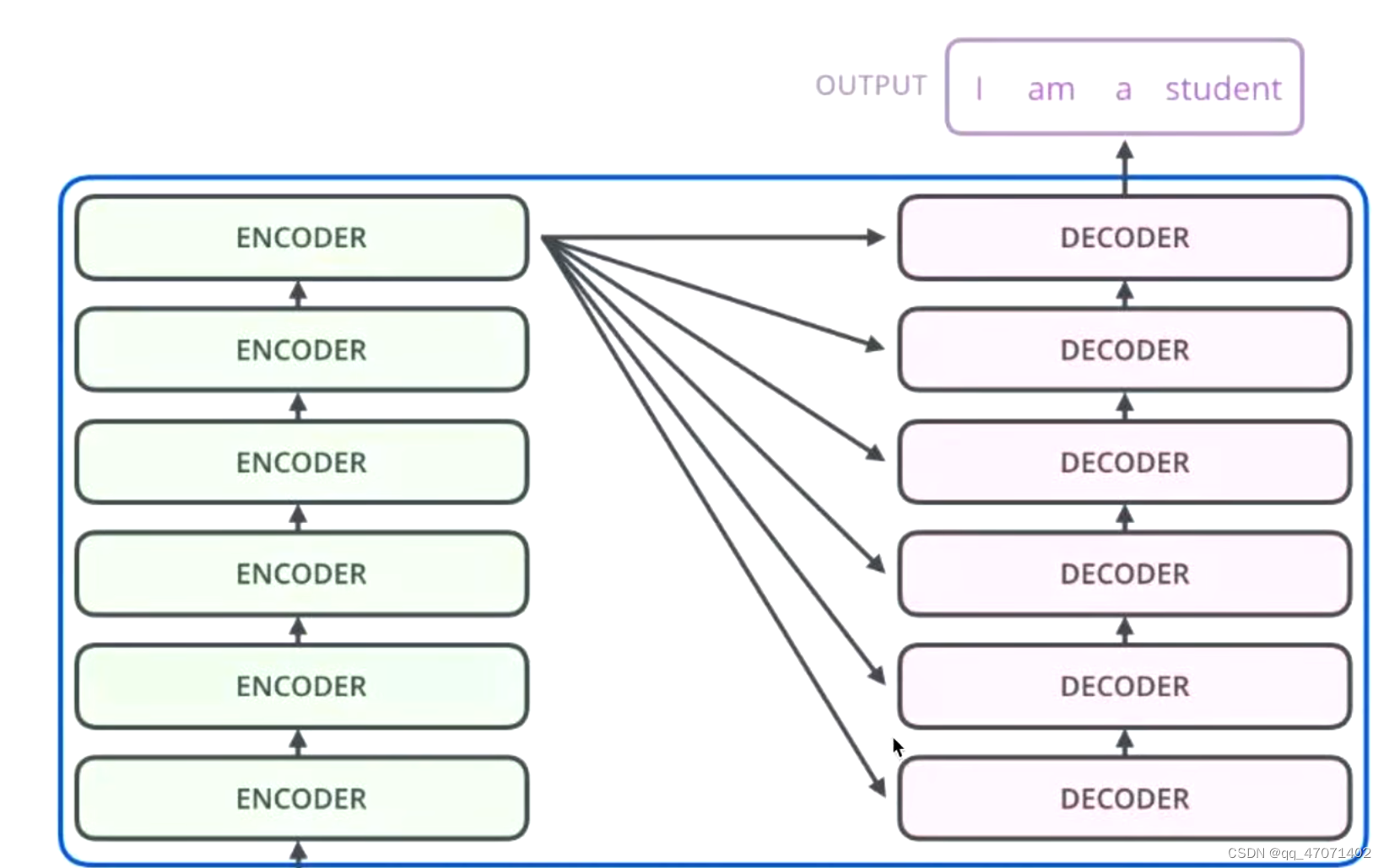
Nx的意思是指连续的堆叠N个encoder,得到一个编码特征
Outputs(Shifted right)指的是将上一个encoder的输入直接拿过来

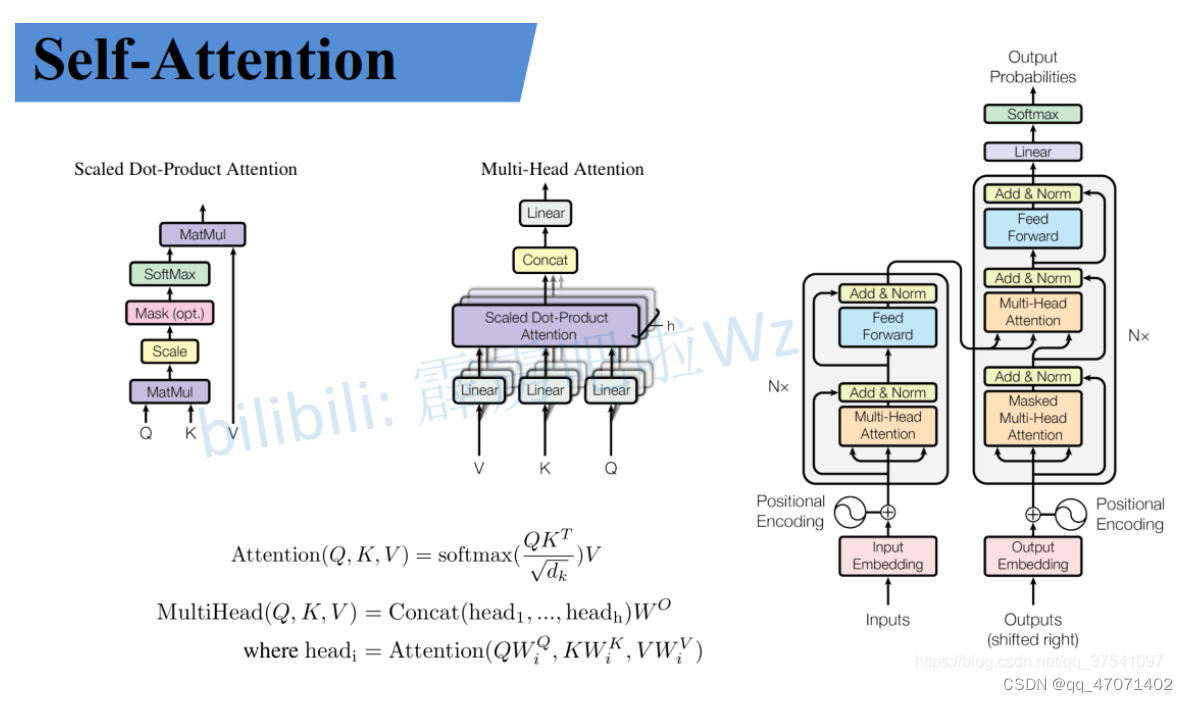
Self-Attention
## Self-Attention
import torch.nn as nn
import torch
class Self_Attention(nn.Module):
def __init__(self, dim, dk, dv):
super(Self_Attention, self).__init__()
self.scale = dk ** -0.5
self.q = nn.Linear(dim, dk)
self.k = nn.Linear(dim, dk)
self.v = nn.Linear(dim, dv)
def forward(self, x):
q = self.q(x)
k = self.k(x)
v = self.v(x)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = attn @ v
return x
att = Self_Attention(dim=2, dk=2, dv=3)
x = torch.rand((1, 4, 2))
output = att(x)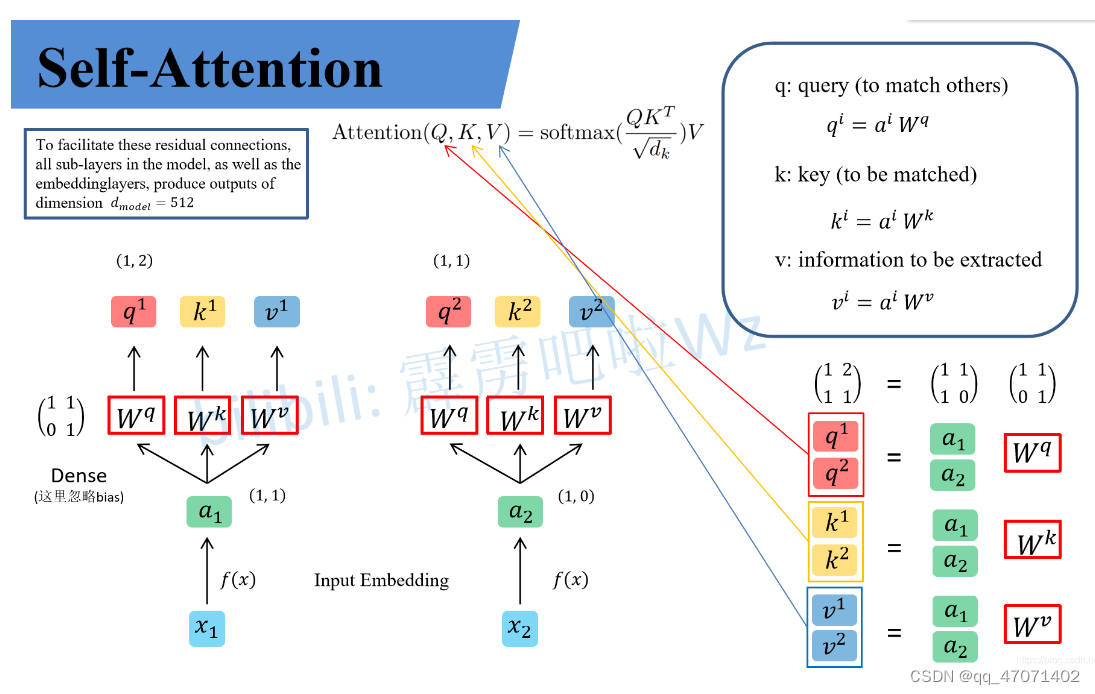
-
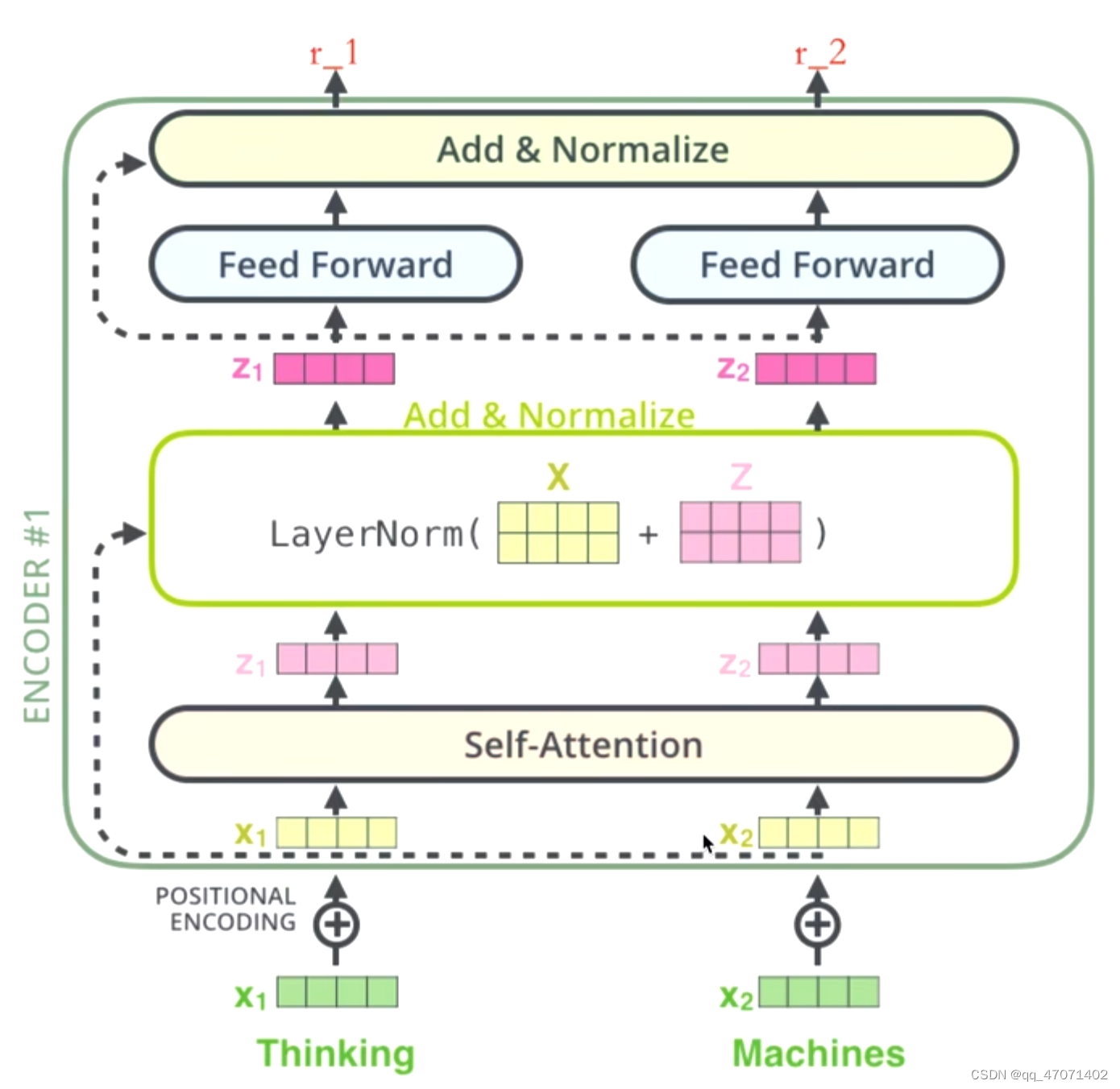
a为嵌入后的特\征,q,k,v是a通过一个linear层映射实现的
-
q代表query,后续会去和每一个k进行匹配
-
k代表key,后续会被每个q匹配
-
v代表从a中提取得到的信息
-
进行点乘后的数值很大,导致通过softmax后梯度变的很小
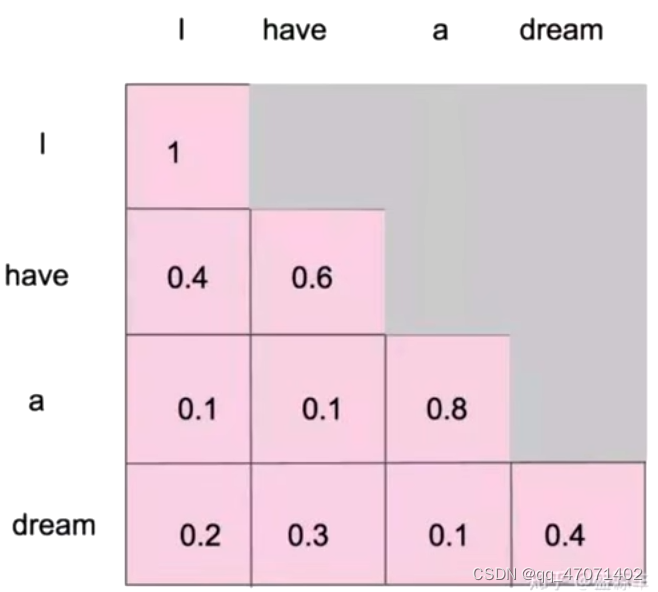
Masked(掩码) Self-Attention
对于生成模型来说,以一句话为例,I have a dream,生成的单词是一个一个生成的,所以没法再一开始就对所有的单词计算self-attention,所以需要用到mask
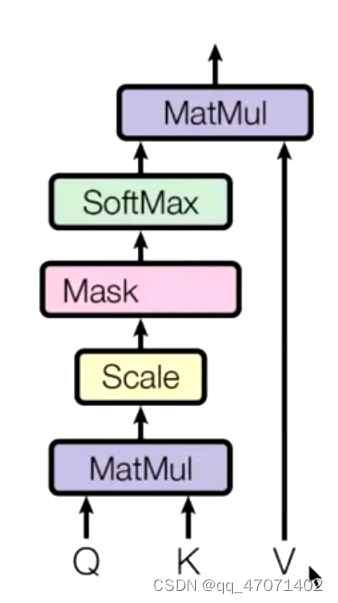
Multi-Head Attention
多头注意力是将q、k、v根据头数进行均分,然后对分头之后的进行self-attention的计算,最后再进行拼接回来,做一次线性变换,也就是乘以W得到最终的结果。代码的实现是直接transpose然后reshape会原来的维度
from math import sqrt
import torch
import torch.nn as nn
class MultiHeadSelfAttention(nn.Module):
def __init__(self, dim_in, d_model, num_heads=3) -> None:
super(MultiHeadSelfAttention, self).__init__()
self.dim_in = dim_in
self.d_model = d_model
self.num_heads = num_heads
assert d_model % num_heads == 0, "d_model must be multiple of num_heads"
self.linear_q = nn.Linear(dim_in, d_model)
self.linear_k = nn.Linear(dim_in, d_model)
# v的层数可以不和q k相同
self.linear_v = nn.Linear(dim_in, d_model)
self.scale = 1 / sqrt(d_model // num_heads)
self.fc = nn.Linear(d_model, d_model)
def forward(self, x):
batch, num_token, dim_in = x.shape
assert dim_in == self.dim_in
nh = self.num_heads
dk = self.d_model // nh
# multi heads attention
q = self.linear_q(x).reshape(batch, num_token, nh, dk).transpose(1, 2)
k = self.linear_k(x).reshape(batch, num_token, nh, dk).transpose(1, 2)
v = self.linear_v(x).reshape(batch, num_token, nh, dk).transpose(1, 2)
dist = torch.matmul(q, k.transpose(2, 3)) * self.scale
dist = torch.softmax(dist, dim=-1)
att = torch.matmul(dist, v) # shape(batch nh num_token dv) (1,3,4,2)
# multi heads fusion
att = att.transpose(1, 2).reshape(batch, num_token, self.d_model)
# shape(batch num_token d_model)
output = self.fc(att)
return output
x = torch.rand((1, 4, 2))
multi_head_att = MultiHeadSelfAttention(x.shape[2], 6, 3)
output = multi_head_att(x)

Positional Encoding
Positional Encoding的作用是让transformer引入相对位置的信息,使用如下公式进行位置编码:
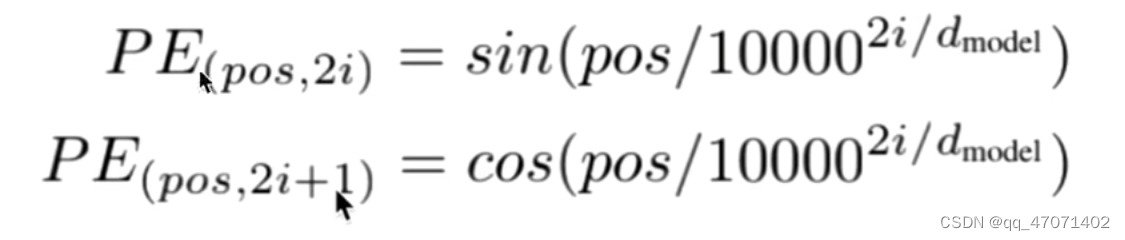
pos为第几个词,i为词向量的第几个维度,例如,词向量的维度为512,则2i+1的最大值为512
为什么要使用这样两个三角函数来计算位置编码呢? 主要是利用到了三角函数的和差化积公式:

对于不同位置的编码,可以表示如下:
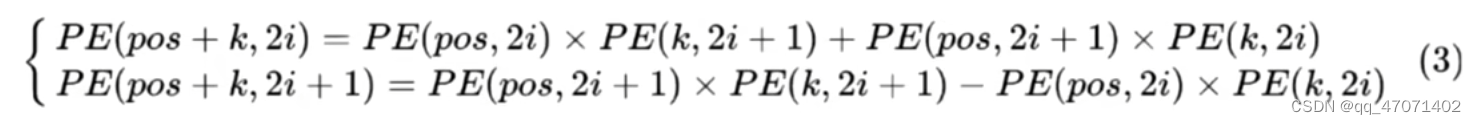
(3)式可以理解为,通过这样的和差化积公式,可以将两个不同位置的信息进行线性组合,从而使得他们之间有了一定的联系,蕴含了位置上的关联。
以一个例子来看: pos+k = 5; 其实就蕴含了1和4,2和3的情况,0的时候没意义。
2、Vision transformer
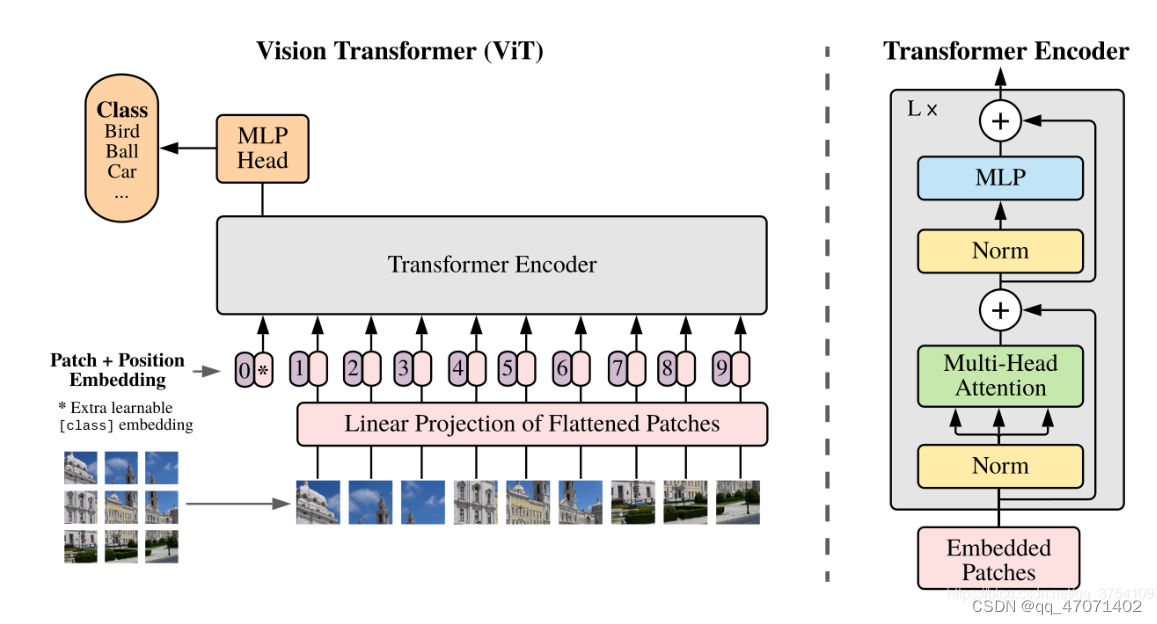
ViT模型是将transformer架构直接拿过来应用到视觉上的第一个模型,模型由三个模块组成:
-
Linear Projection of Flattened Patches (将patchs嵌入到和transformer要求一样的输入)
-
Transformer Encoder
-
MLP Head (用来分类的)
Embedding层
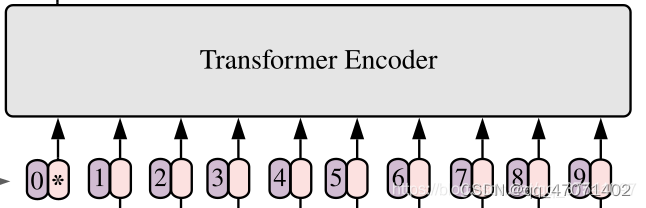
对于transformer,要求输入的是token,即二维矩阵[numtoken,tokendim]。在ViT中每个token向量长度为768。
对于ViT,输入图片的大小为(224x224),按照16x16大小的patch进行划分,将得到196个patchs。再通过映射得到长度为768的token。
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = (img_size, img_size)
patch_size = (patch_size, patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
return x
在代码中,是通过卷积直接实现的,将[224,224,3]的图像卷积为[14,14,768]的特征,然后再将前两个维度展平,就得到了[196,768]的二维矩阵,正是transformer想要的输入。
Position Encoding and [cls] token
-
[cls] token的作用是用来进行分类
-
Position Encoding的作用和transformer中一样,让向量蕴含位置信息
-
整体的输入的维度就是 Cat([1,768],[196,768]) → [197,768]
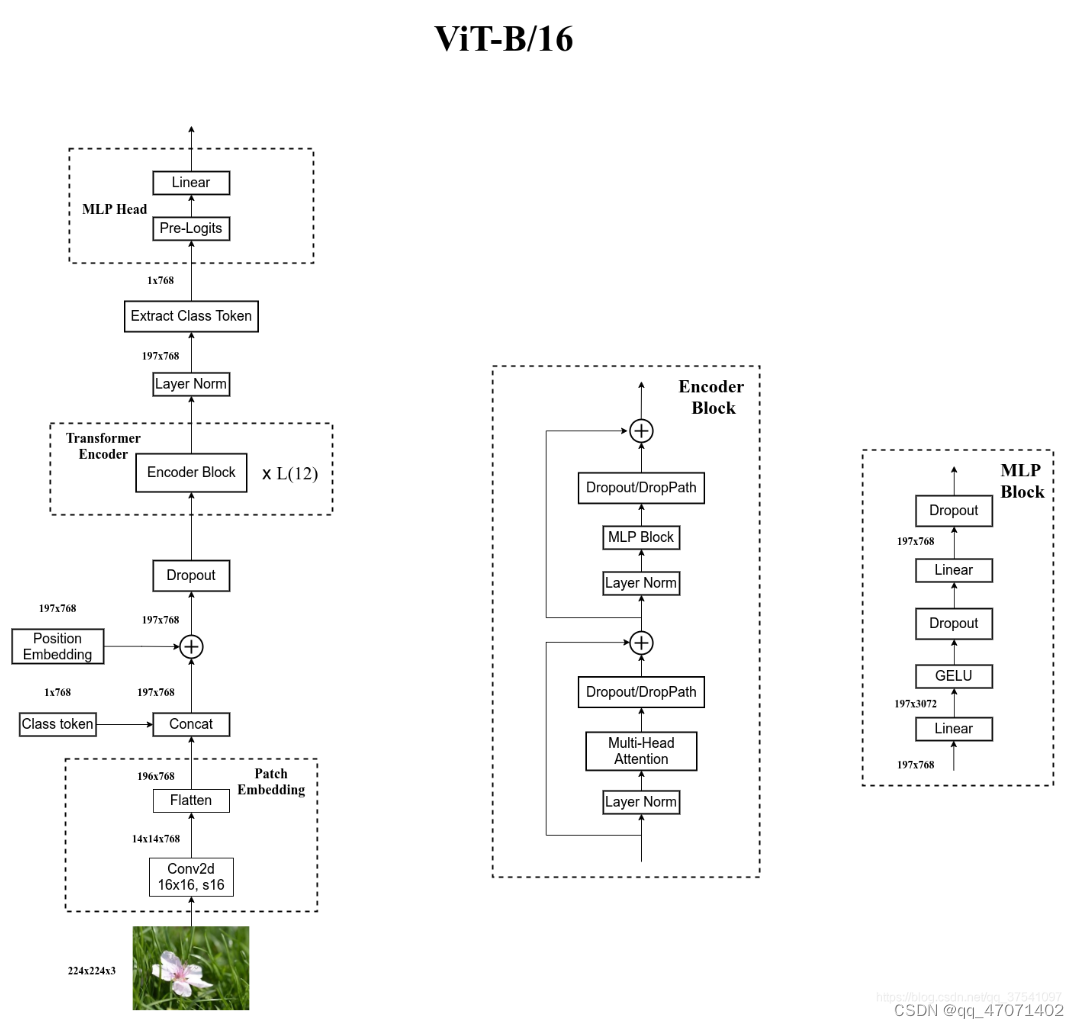
ViT Encoder
-
DropPath是随机地禁用网络中的一些路径和连接,减少了网络的复杂性。
-
对于SR任务,用的是经过Encoder之后的特征。
MLP Head
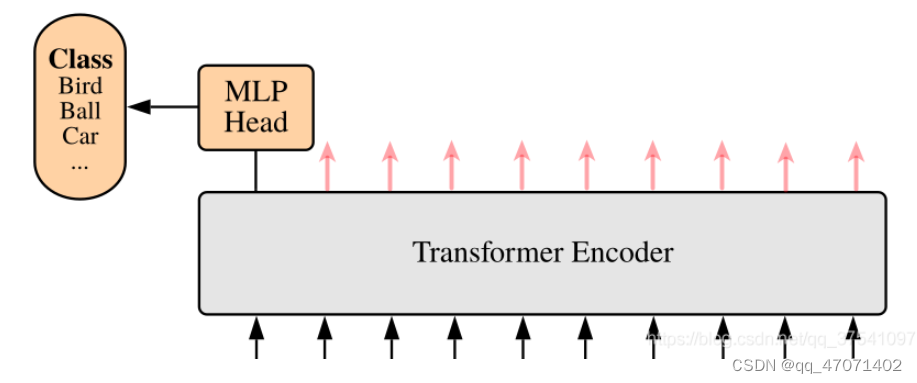
提取出[class] token生成的对应结果就行,即[197, 768]中抽取出[class ]token对应的[1, 768]。接着通过MLP Head得到最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。
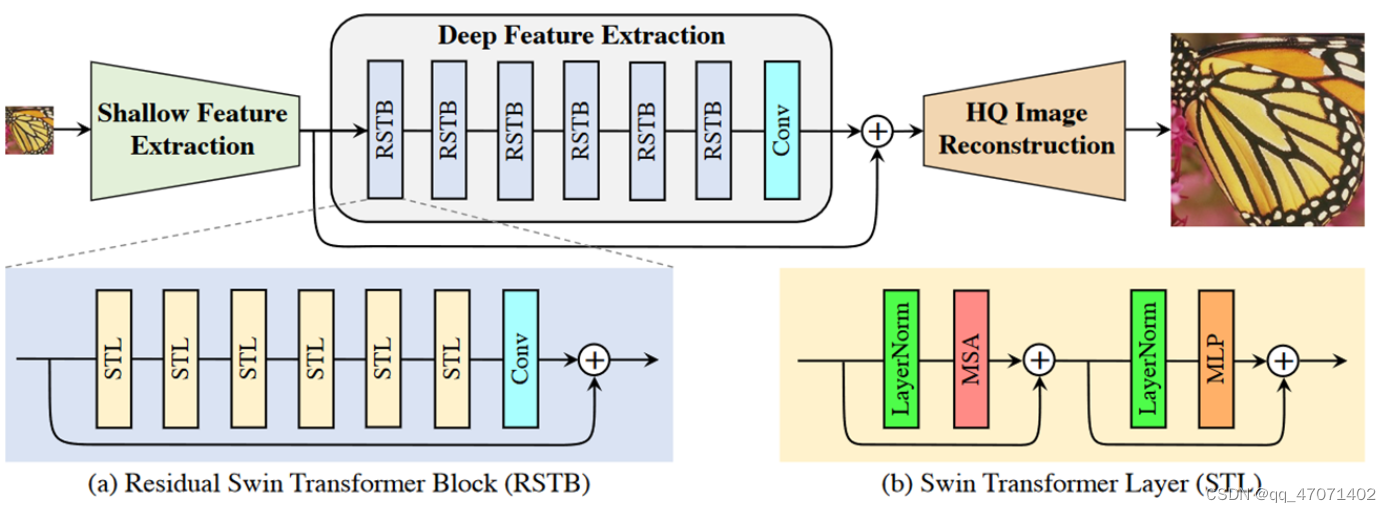
3、SwinIR
使用了Swin transformer作为主体框架的图像超分辨率网络:















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









