






1、Semantic Lens: Instance-Centric Semantic Alignment for Video Super-Resolution(AAAI24)
1 Institute of Information Science, Beijing Jiaotong University, Beijing, China
2 Beijing Key Laboratory of Advanced Information Science and Network Technology, Beijing, China
3 Alibaba-NTU Singapore Joint Research Institute, Nanyang Technological University, Singapore
4 School of Computer and Communication Engineering, University of Science and Technology Beijing, Beijing, China
{qitang, yzhao, mqliu}@bjtu.edu.cn, jian.jin@ntu.edu.sg, yaochao@ustb.edu.cn
-
以一种全新的角度来进行对齐,考虑到了图像内在的语义信息;
-
是第一篇从
语义分割的角度来分析前景后景在移动过程中,对对齐影响的工作;

1.1 存在的问题
目前视频超分辨率没有考虑到的一些问题:
-
由于视频运动中存在复杂的运动交织,
精确的像素对齐是一项具有挑战的任务; -
视频运动中存在的
前景和后景对对齐任务是存在影响的,先前的工作没有考虑到这个问题对对齐效果的影响; -
当面临由于
遮挡而导致信息丢失时,像素级别的对齐可能会带来模糊的效果;
1.2 改进方法与新范式
1.2.1 针对存在的问题的一种解决方案,即使用语义信息来指导:
-
人们在面对一段运动的视频的时候,会自动的区分前景信息和背景信息
-
eg:我们可能直观的将赛道上领跑的赛车视为前景,而其他的为后景;
-
一种简单的方法就是对视频中的前景和后景进行建模;
-
背后的归因是:建立
以实例为中心的语义表示,并把视频中相应的对齐归于相应的实例;
-
-
物体的一些尺寸和光照的变化会影响像素对齐的效果,但在语义空间这些因素可以忽略不计;
-
将每个实例或背景视为一个独立的运动单元;
-
原本复杂的相互交织的动作,被分解为几个简单而独立的动作
-
1.2.2 针对上述提出的两点,作者引入了语义镜头,是一种视频超分辨率的新范式:
-
语义镜头将镜头的放大能力与语义先验结合起来,不仅可以提高分辨率,还可以产生令人愉悦的视觉效果。具体来说,通过构建
语义提取器将最初由帧组成的视频解耦为实例、事件和场景; -
提出了一个语义驱动的注意力交叉嵌入块来桥接语义先验和像素级特征,了解恢复的内容;
-
为了利用语义信息,提出了SemanticsPowered Attention Cross-Embedding (
SPACE) ,包括全局视角移位器 (GPS) 和实例特定语义嵌入编码器 (ISEE)。将语义以类似位置嵌入(transformer中的位置嵌入)的方式嵌入到从LR帧提取的特征中,并在语义先验的指导下实现以实例为中心的帧对齐; -
设计了实例特定语义嵌入编码器,通过注意机制在以实例为中心的语义空间中执行帧间对齐。
1.3 网络架构
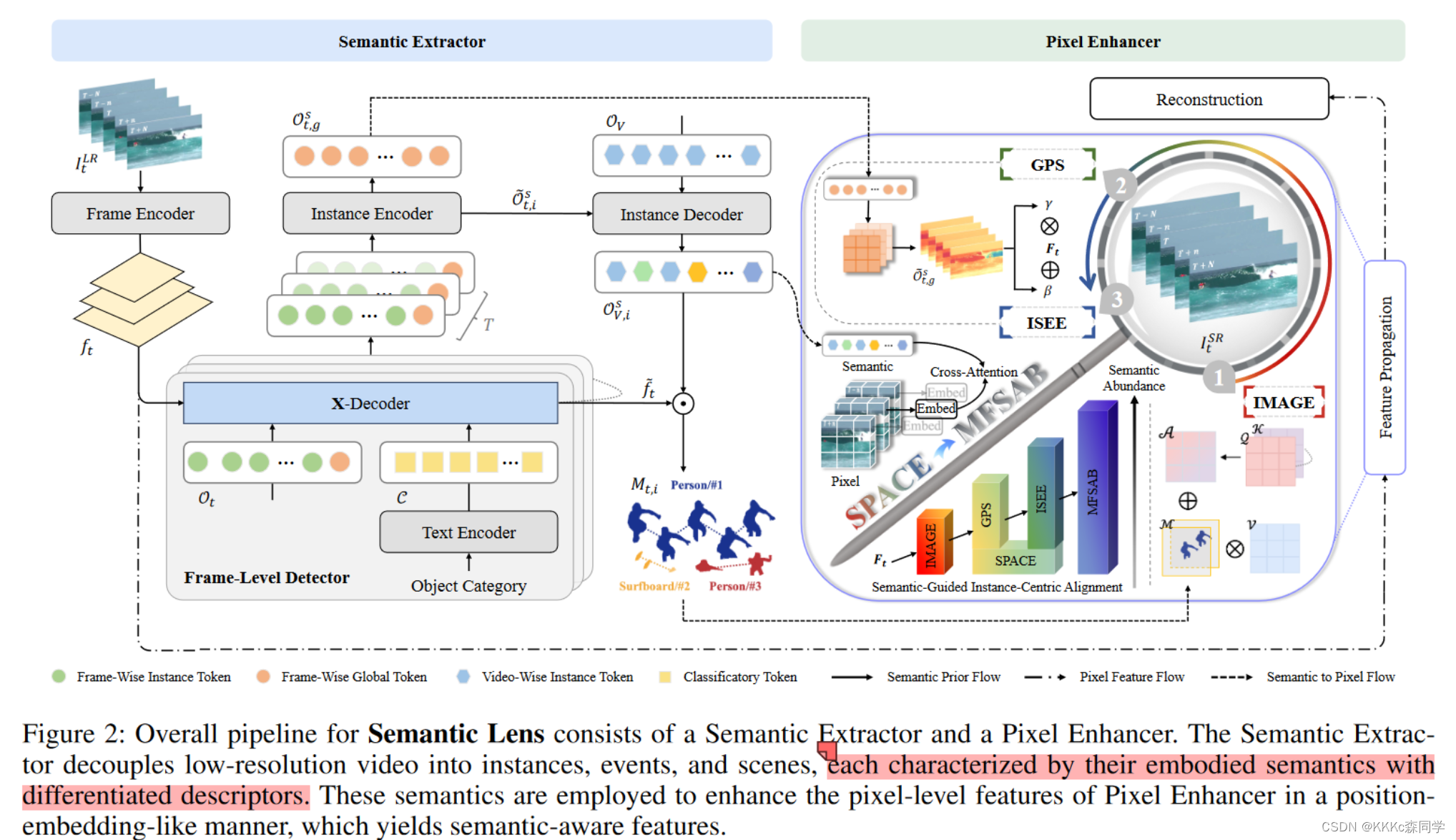
-
网络架构主要分为了两个部分:语义信息抽取器
Semantic Extractor和像素增强器Pixel Enhancer-
语义信息抽取器用来抽取视频帧中不同物体的语义信息;
-
像素增强器通过使用语义信息来得到更丰富的纹理细节;
-
-
1.3.1 Implicit Masked Attention Guided Pre-Alignment (
IMAGE)-
是一种预对齐的模块,通过attention的方式来实现粗略的对齐;
-
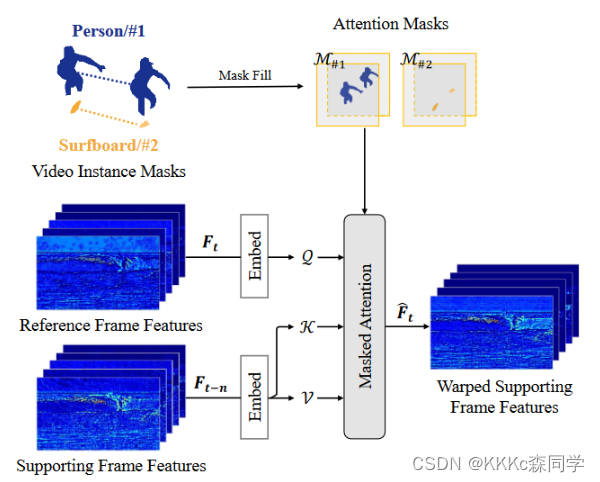
-
大致是思想是通过判断实例之间的相关性,如果两帧之间实例
mask有相关的就不做改变,如果不相关,则mask填充为负无穷; 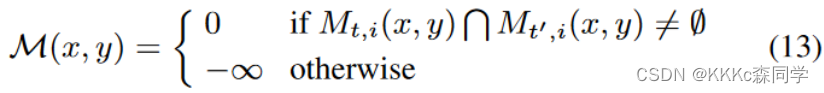
-
-
1.3.2 Semantics-Powered Attention Cross-Embedding (
SPACE)
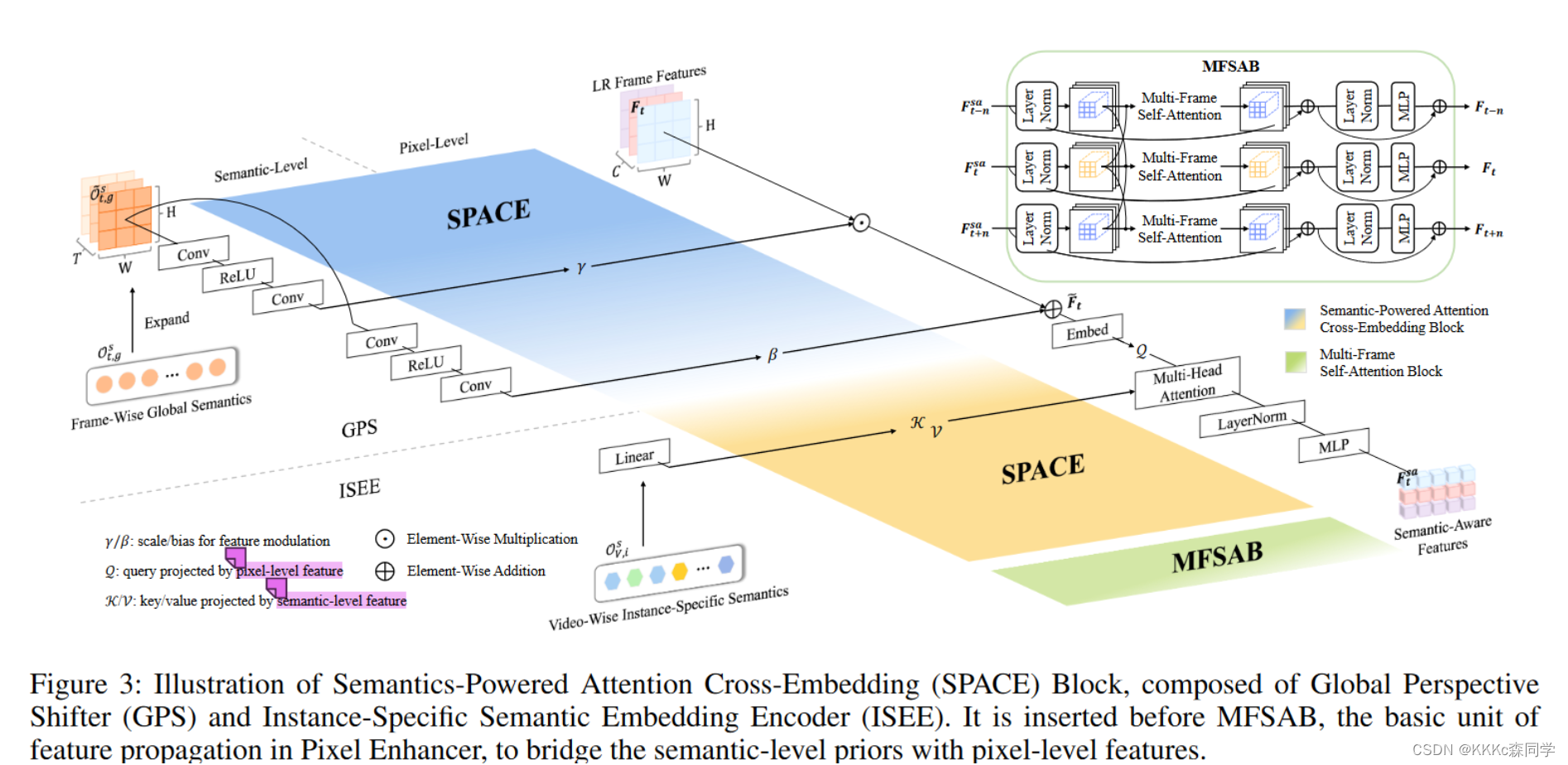
-
通过粗略对齐之后需要考虑的问题是,语义信息和LR帧如何的进行交互建模;
-
SPACE的提出解决了这个问题,由两个模块组成:GPS和ISEE
GPS:Global Perspective Shifter
-
GPS的作用为通过从语义信息特征图里学习一对仿射系数来对LR帧特征做全局的调整;
-
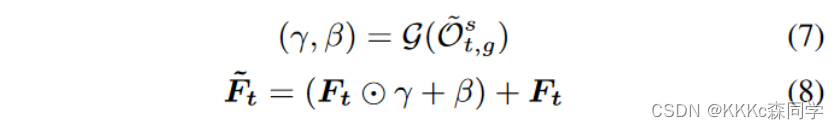
ISEE:Instance-Specific Semantic Embedding Encoder
-
ISEE的作用是将语义信息和GPS的输出进行交互;
-
是通过Q、K、V交叉注意力的形式来进行嵌入的,Q是通过GPS调整后的特征,K和V是视频语义信息特征;
-
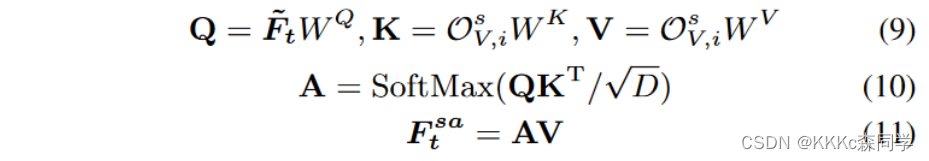
MFSAB:Multi-Frame Self-Attention Blocks
-
多帧注意力的结构,是一种双向的特征传播的架构,类似于BasicVSR++
-
MFSAB是Pixel Enhancer中特征传播的架构,用来建立语义先验和像素级别特征的一个桥梁
1.4 实验
1.4.1 数据集
-
训练数据集:YouTube-VIS(YTVIS),是视频实例分割的相关的数据集,作者使用的是YTVIS-21和YTVIS-22;
-
测试数据集:YTVIS2019、YTVIS2020、YTVIS2021三个val数据
-
对于测试数据集分为了两种设置BI和BD,BD设置的高斯sig为1.6
1.4.2 训练设置
-
5帧,语义特征进行压缩:512维 -> 120维,图像patch大小为64x64
-
Adamw优化器,weight decay为0.0001,学习率为0.0002
-
损失为Charbonnier Loss
-
Pytorch2.0、4张3090
1.4.3 消融实验
-
对作者提出的模块进行消融

Baseline是只保留了MFSAB特征传播的网络,以此作为基准网络,由表3可以得出最重要的模块为ISEE,因为这个模块是用来建立语义信息和帧特征交互融合的关键模块。
-
可视化效果的消融
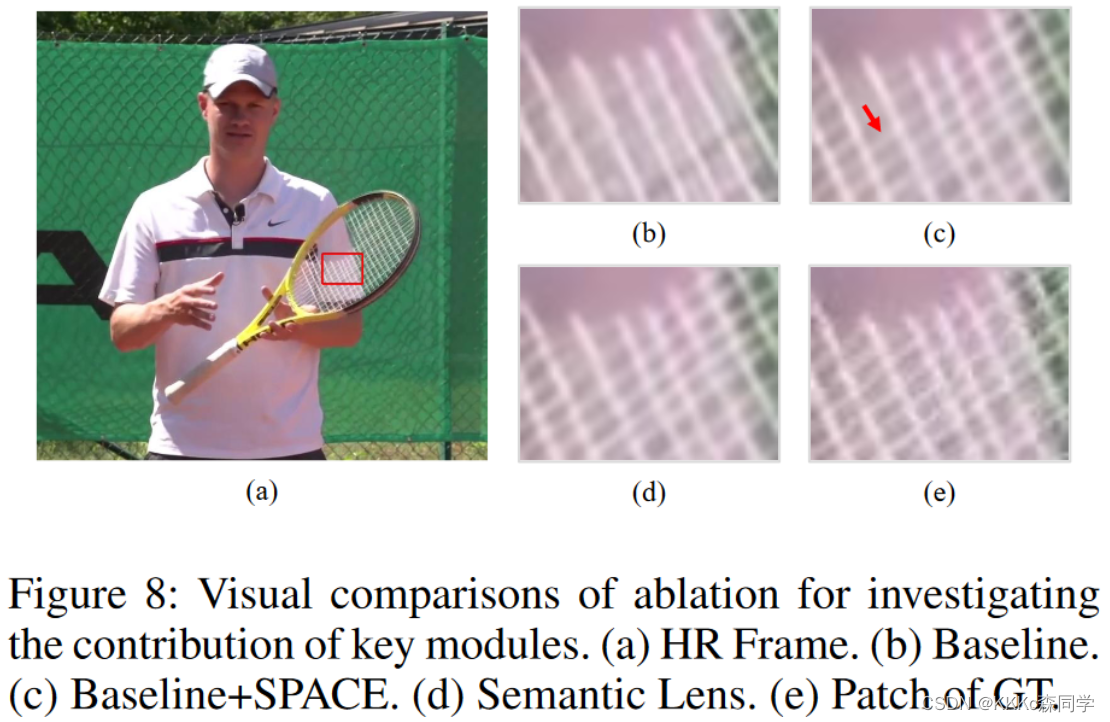
(b)为不加如SPACE的baseline,一些线条回复的模糊;(c)为加入SPACE之后的网络,能够恢复出细致的线条纹理。
1.5 指标和可视化结果
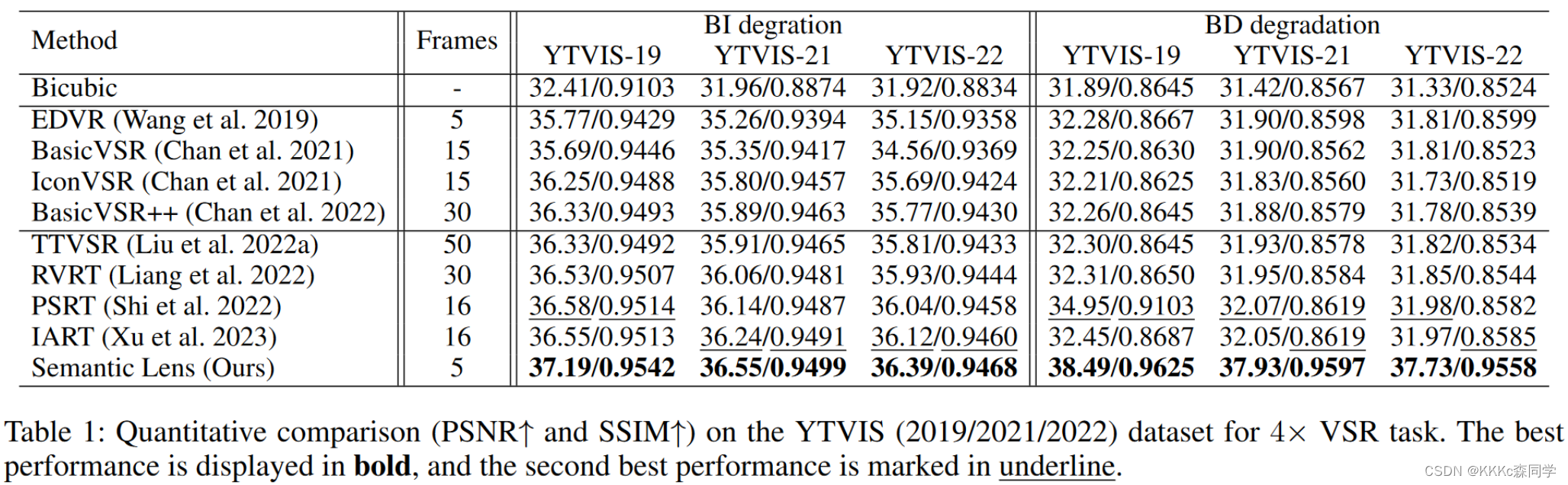
1.5.1 PSNR和SSIM指标结果
-
分别在两个退化上,BI和BD退化上进行了比较,比较的方法为比较新和SOTA的方法,分别进行了重新的训练,在语义分割的数据集上,参数的设置和原论文一致;
-
Semantic Lens在所有的YTVIS数据集上达到了最好的效果,尤其是在BD退化上,提高显著,也验证了语义信息利用的有效性;
1.5.2 可视化对比图
















 1830
1830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









