






1、目前的一些超分的工作
-
目前一些盲超分工作开始将文本信息利用起来来做一个prompt的先验:
[1] SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution
[2311.16518] SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution (arxiv.org)
[2] Image Super-Resolution with Text Prompt Diffusion
[2311.14282] Image Super-Resolution with Text Prompt Diffusion (arxiv.org)
2、Image Super-Resolution with Text Prompt Diffusion(2023 CVPR PromptSR)
Zheng Chen1, Yulun Zhang2∗, Jinjin Gu3,4, Xin Yuan5, Linghe Kong1,* Guihai Chen1, Xiaokang Yang1 1 Shanghai Jiao Tong University, 2ETH Zürich, 3Shanghai AI Laboratory, 4The University of Sydney, 5Westlake University
2.1 背景和研究动机
-
从低分辨率图像提取退化的信息是具有挑战性的,这限制了SR模型的表型性能;
-
为了增强Image SR的性能,一个方法是引入一定的先验信息;
-
受多模态模型以及文本提示图像处理工作的发展,是否可以将退化先验作为一种文本提示的信息来辅助SR方法
目前的一些盲超分的方法分类:
-
显示模型:去估计退化的参数,比如模糊核和噪声;
-
隐式模型:学习一个退化模型的分布;
-
合成大量的复杂的退化,并在这个退化空间上去训练,达到更大的泛化性能;
使用文本信息的一些好处:
-
文本信息是抽象且灵活的;
-
能够利用现在的一些大的预训练模型;
-
文本信息的指导可以作为当前SR方法的一个补充。
2.2 创新之处
-
首次将文本信息作为一种先验来指导SR
-
设计了一种新的数据集形式,HR-LR-Text
-
提出了一个网络 PromptSR 来实现文本提示SR,PromptSR 基于扩散模型和预训练的语言模型。
2.3 具体细节
数据集生成:
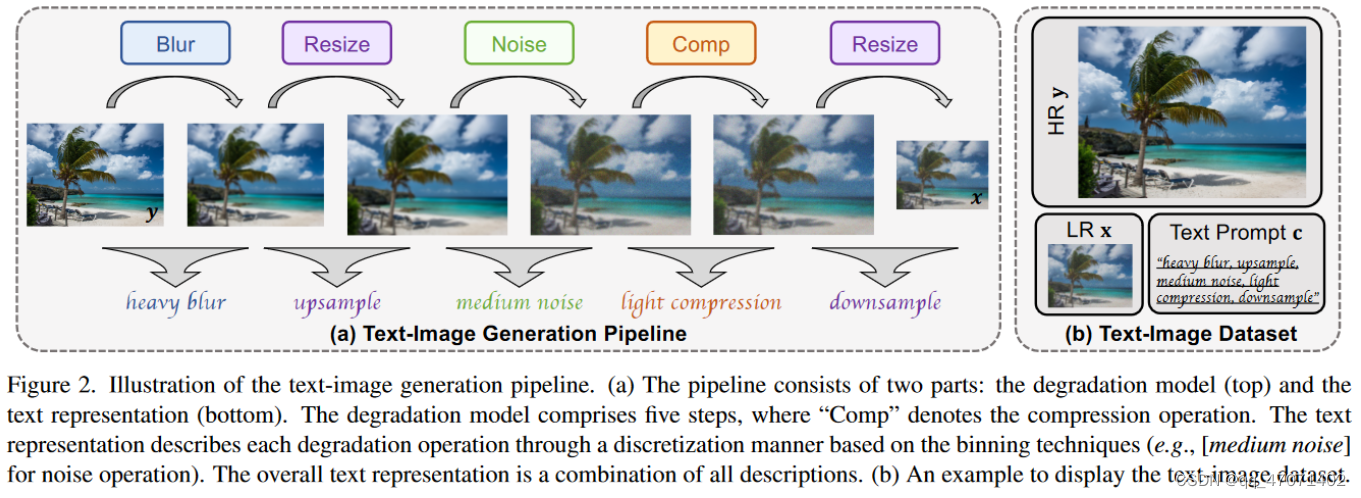
-
数据的生成由退化模型和文本表示组成,退化模型使用了像Real-ESRGAN的多种退化的形式,对于文本表示,则通过离散化的分箱操作来描述每个降级操作
-
离散化分箱:将连续的值进行离散化操作,比如是
[Gaussian noise with noise level 1.5]。然而,这种表述很麻烦。此外,过于精确的描述可能会限制普遍性。所以对噪声分了三个等级light、medium、heavy,Gaussian噪声和Poisson噪声均被归纳为noise,所以就可以将最原始的文本表示为[medium noise]。 -
Text-Image的形式如图(b)所示,由HR,LR,和文本的Prompt c组成
网络架构:
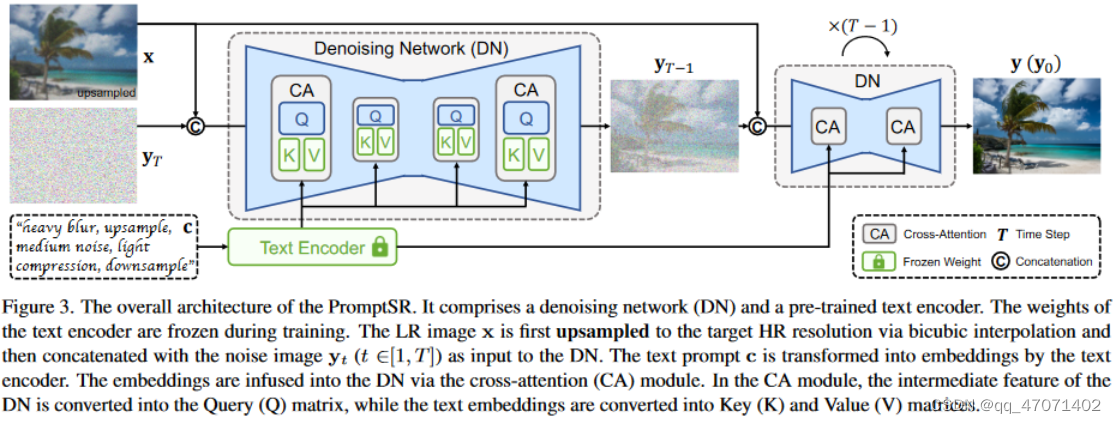
-
网络的输入是初始的上采样后的低分图像(通过bicubic),噪声图像Y_T以及文本的prompt描述;
-
Text Encorder是冻结的,使用的预训练好的文本编码器,如CLIP/T5模型,只训练扩散模型,网络的整体是一个U-net架构的去噪框架;
-
通过交叉注意力的形式将文本特征与图像特征进行Q、K、V的计算;

训练细节:
-
使用的训练数据是一个text-image的数据集,形式如(c,[y,x]),c是文本描述,y是HR,x为LR
-
通过t步的扩散噪声来得到一个噪声Y_T
-
训练的目标函数如下:
-
实验设置:
-
Blur:iso和aniso两种kernel,kernel width随机的从[7,9,...,21]中选择;
-
Resize:area,bilinear,bicubic interpolation三种,概率分别为[0.3,0.4,0.3];一共有两次的resize;
-
Noise:Gaussion noise的范围为[1,30],Poisson noise的范围为[0.05,3];
-
Compression:JPEG的压缩,等级为[30,95],越高压缩程度越大;
-
训练数据集:LSDIR,更大规模的数据集,有84991张高分辨率图像;
-
验证数据集:合成数据集:Urban100、Manga109、LSDIR(val)、DIV2K(val);真实数据集:RealSR、Real45
-
评价指标:PSNR、SSIM、LPIPS、ST-LPIPS、DISTS、CNNIQA、NIMA
-
DISTS: 统一结构和纹理相似性(dingkeyan93/DISTS: IQA: 深度图像结构和纹理相似度指标 (github.com))
-
ST-LPIPS: 移位宽容-LPIPS,即使在存在难以察觉的像素偏移的情况下,该指标仍然保持稳健
-
CNNIQA:使用卷积神经网络来做一个图像质量评估,CNN对图像patch进行评估
-
-
数据集和训练设置:64x64的patch,Adam optimizer,lr=0.0002
2.4 消融实验
-
对text prompt学习方式的消融,ControlNet是可以根据修改text promtp生成新的图像
-
-
对text prompt是否正确对结果影响的可视化消融:
-
-
对text prompt形式的消融,一种是内容caption,一种是degradation,一种是两者都包含:
-



实验表明,只使用degradation的泛化性能和效果最好,因为图像本身是包含了一些语义信息的,两者都用的话会对退化方面的prompt产生一定的不良影响,这是作者认为产生这种原因的结果。
-
对不同的text encoder的一个消融实验:
-

综合考虑,作者使用了CLIP模型,且模型的大小与性能的提升并不是成正比的关系。
2.5 效果:
-
指标效果对比
-
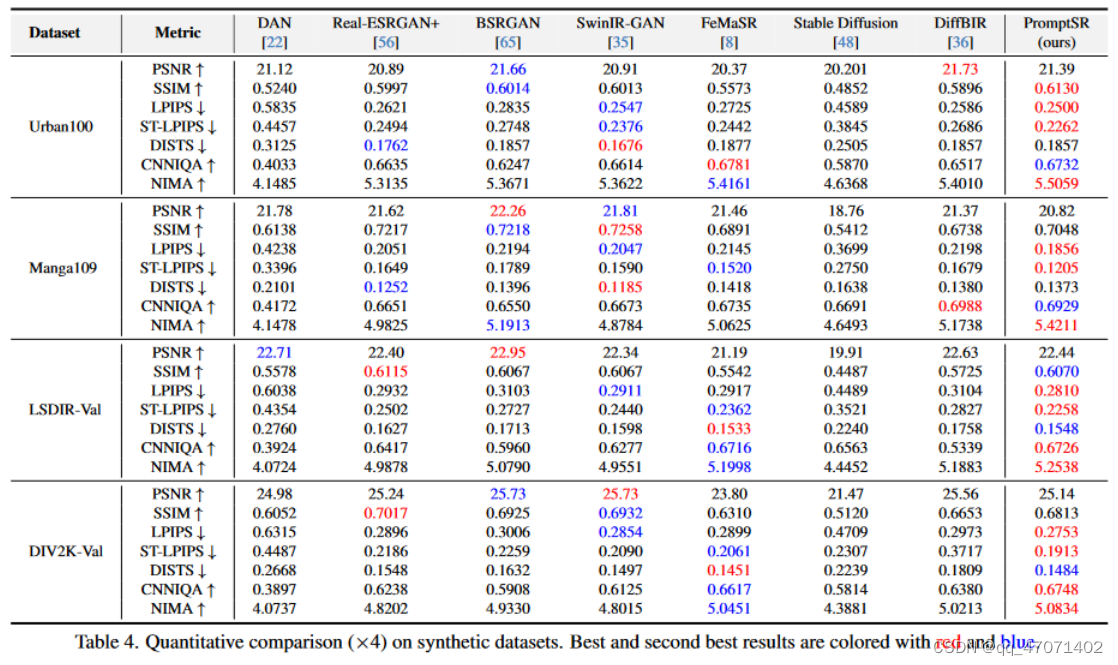
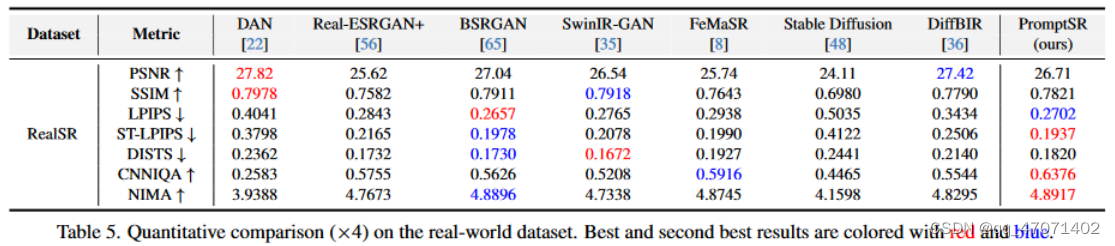
-
可视化对比图
-
















 5383
5383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









