






1.OPTICS聚类算法
应用背景:如今整个数据集越来越复杂,都采用到了至少一个全局密度表征参数。如果对同一数据集中同时也存在这两种不同的全局密度表征参数的一个聚类簇或者是两个的嵌套簇,则所使用到的DBSCAN算法显然并没有做到高效地处理,因为DBSCAN聚类算法采用的是全局密度表征参数。为了能够进一步研究解决了这个实际应用问题,学者们甚至也已经提出和研究到了OPTICS算法。
算法原理:OPTICS聚类算法,其基本编程思想大致是和DBSCAN算法非常之类似,但OPTICS算法不是像DBSCAN算法一样显而易见地直接生成聚类结果,它是一种优化算法帮助选取初始距离阈值的算法。
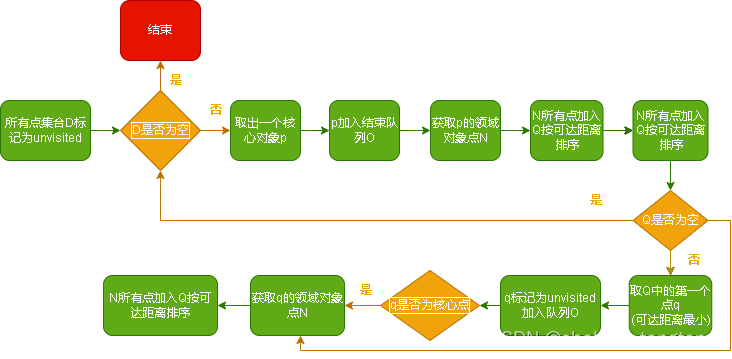
两个新概念:定义了两个下面即将介绍的新概念,一个是核心距离,一个是最小的可达距离。
此算法将大量数据放到一个有序列表中按照其他点离某一个核心点距离进行排序,寻找离该核心点距离最小距离的点,并将其放入结果队列中,按照此选取方法不断选取直至有序队列中的点全部都进入结果队列中,算法结束。最终生成的结果有序列表中的数据点都是聚类中相邻且集中的,我们可以通过该有序列表包含的信息主观选取密度阈值 ,结果队列中有序的对象列表也可以用其生成的横坐标为样本处理顺序,纵坐标为可达距离的决策图选取适当的 。我们可以根据固定的
,选取适当的
,再运用本文重点所述的DBSCAN密度聚类算法进行聚类。
核心距离:假设某一样本点,如果给定了
和
,那么使得
成为核心点的某邻域的最短长度称为
的核心距离。其中
表示的是
中距离某一样本点
第
长的样本点。
最小可达距离:设,对于给定的
和
,
关于
的可达距离定义为:
流程图:
2.DBSCAN和OPTICS聚类算法对比
前面介绍OPTICS算法定义时说过,因为DBSCAN聚类算法基于全局密度参数,使得该算法不能识别不同密度的簇。对于高密度簇的核心点,在较小的领域内就可以至少有个点;对于低密度簇的核心点,在较大的领域内才可以有个点。所以对初始参数更加敏感。OPTICS算法的提出就是为了克服DBSCAN聚类算法采用全局表征密度参数带来的聚类质量差问题。但OPTICS聚类算法对于距离阈值比较不敏感,所以我们将其设为无穷大。下面我们来看下给定3个聚类中心、随机生成的250个数据点,对于相同、不同密度的簇,DBSCAN算法的聚类效果,将密度相同的标准差设定为0.35,将密度不相同的标准差设定为0.35,0.1,0.6。生成以下两幅图:
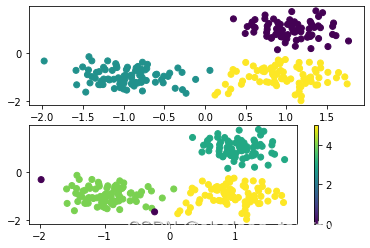
图1 DBSCAN聚类算法处理密度相同数据效果图

图2DBSCAN聚类算法处理密度不同数据效果图
通过图1、图2的对比我们可以看出DBSCAN算法在处理不同密度簇聚类的时候出现了很多噪声点,即聚类质量不好。于是我们用OPTICS算法对于相同的数据点进行聚类处理得到图3,图4。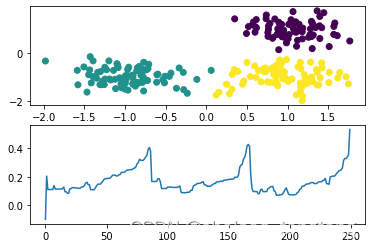
图3 OPTICS聚类算法处理密度相同数据效果图
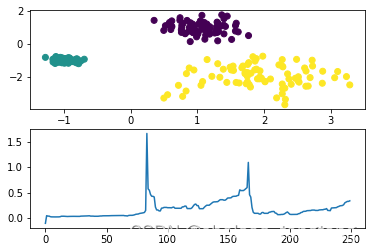
图4 OPTICS聚类算法处理密度不同数据效果图
簇在坐标中表述为波谷(凹陷),并且波谷(凹陷)越深,簇越紧密。从图2-8的第二幅图可以看出,可达距离呈现三个波谷,也即表现为3个簇。我们可以直观看出图3的选取大概0.2~0.4时,样本被聚类成三类。图4的选取大概0.5~1时,样本被聚类成三类。
当你需要提取聚集的时候,参考Y轴和图像,自己设定一个合适的就可以聚类,也可以继续用DBSCAN聚类算法进行聚类。
3、DBSCAN和OPTICS算法的结合
OPTICS聚类算法不是直接得表现出数据属于某一类,而是直接为每一个聚类分析数据生成一个增广的簇排序,通过解析该簇有序的列表数据可以直接得到一个决策图。通过决策图可以得到一个广泛的距离阈值来克服全局参数所带来的缺陷。OPTICS算法可以运用在DBSCAN聚类算法之前用来距离阈值的选取,这样的做法可以大大提高DBSCAN算法的准确性。















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









