







目录
活动地址:CSDN21天学习挑战赛
学习:深度学习100例-循环神经网络(RNN)实现股票预测 | 第9天_K同学啊的博客-CSDN博客
一、前言
1.1 循环神经网络(RNN)
简而言之,循环神经网络带有上一次网络输出的“记忆”,即 当前网络的隐藏层的输入不仅和它的输入层有关,还和上一网络隐藏层的输出有关
也可参考:深度学习之RNN(循环神经网络)_笨拙的石头的博客-CSDN博客_rnn
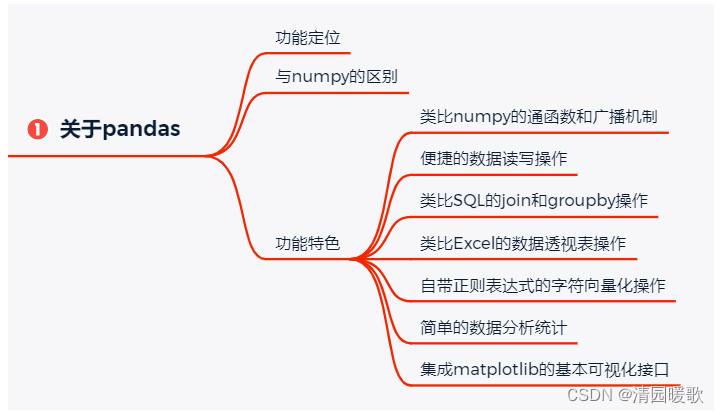
1.2 模块
1.2.1 数据加载
import os,math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
是为了解决 matplotlib 的如坐标轴中文出现乱码问题,若还出现乱码。则需要在中文字符前加上i,如:plt.xlabel(u"这是x轴")
1.2.2 import sklearn
参考:非常详细的sklearn介绍_机器学习算法那些事的博客-CSDN博客_sklearn
Sklearn (全称 Scikit-Learn) 是基于 Python 语言的机器学习工具。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上
在 Sklearn 里面有六大任务模块:分别是分类、回归、聚类、降维、模型选择和预处理

preprocessing:预处理
1.2.3 import pandas
参考:Pandas入门详细教程_Python数据之道的博客-CSDN博客
总结了这67个pandas函数,完美解决数据处理,拿来即用!_数据分析与统计学之美的博客-CSDN博客
pandas,python+data+analysis的组合缩写,是python中基于numpy和matplotlib的第三方数据分析库,与后两者共同构成了python数据分析的基础工具包,享有数分三剑客之名
data = pd.read_csv('./datasets/SH600519.csv') # 读取股票文件
data
"""
前(2426-300=2126)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价
后300天的开盘价作为测试集
"""
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
data.iloc [0:2426 - 300, 2:3].values:获取(2426-300)行,第2列数据的值(values)
二、其他
2.1 归一化
sc = MinMaxScaler(feature_range=(0, 1)) # 初始化一个MinMaxScaler对象
training_set = sc.fit_transform(training_set) # 先拟合,再转换成标准化
test_set = sc.transform(test_set)
sc = MinMaxScaler(feature_range=(0, 1)):将数据映射到[0, 1]中,此即 归一化
scaler = MinMaxScaler():自动归一化
也可以映射到其他区间 scaler2 = MinMaxScaler(feature_range=[1,2])
一定要先 fit_transform 再 transform
参考:【机器学习】数据归一化——MinMaxScaler理解_GentleCP的博客-CSDN博客_minmaxscaler
Python:sklearn数据预处理中fit(),transform()与fit_transform()的区别_健康平安的活着的博客-CSDN博客_sc.transform
2.2 模型构建
model = tf.keras.Sequential([
SimpleRNN(100, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.1), #防止过拟合
SimpleRNN(100),
Dropout(0.1),
Dense(1)
])
return_sequences=False,意思是RNN只输出最后一个状态向量,把之前的状态向量全都扔掉
Dropout(0.1):是为了防止过拟合,通过随即丢失节点来防止过拟合,在训练过程中,一些层的输出被随机忽略或“丢弃”,这种效果使原本的图层看起来像具有不同节点数,并且与前一个图层的连接关系也发生了变化。实际上,在训练期间对图层的每次更新都会对设置图层的不同“视图”执行。0.1是失活概率,即指定图层输出单元被丢弃的概率,若无法确定,可以从0.1到1尝试,增量为0.1
RNN模型与NLP应用笔记(3):Simple RNN模型详解及完整代码实现_番茄炒狼桃的博客-CSDN博客
深度学习基础之Dropout_Wang_AI的博客-CSDN博客
2.3 评估
"""
MSE :均方误差 -----> 预测值减真实值求平方后求均值
RMSE :均方根误差 -----> 对均方误差开方
MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
详细介绍可以参考文章:https://blog.csdn.net/qq_38251616/article/details/107997435
"""
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方误差: %.5f' % MSE)
print('均方根误差: %.5f' % RMSE)
print('平均绝对误差: %.5f' % MAE)
print('R2: %.5f' % R2)
metrics:评价指标函数















 1130
1130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











