







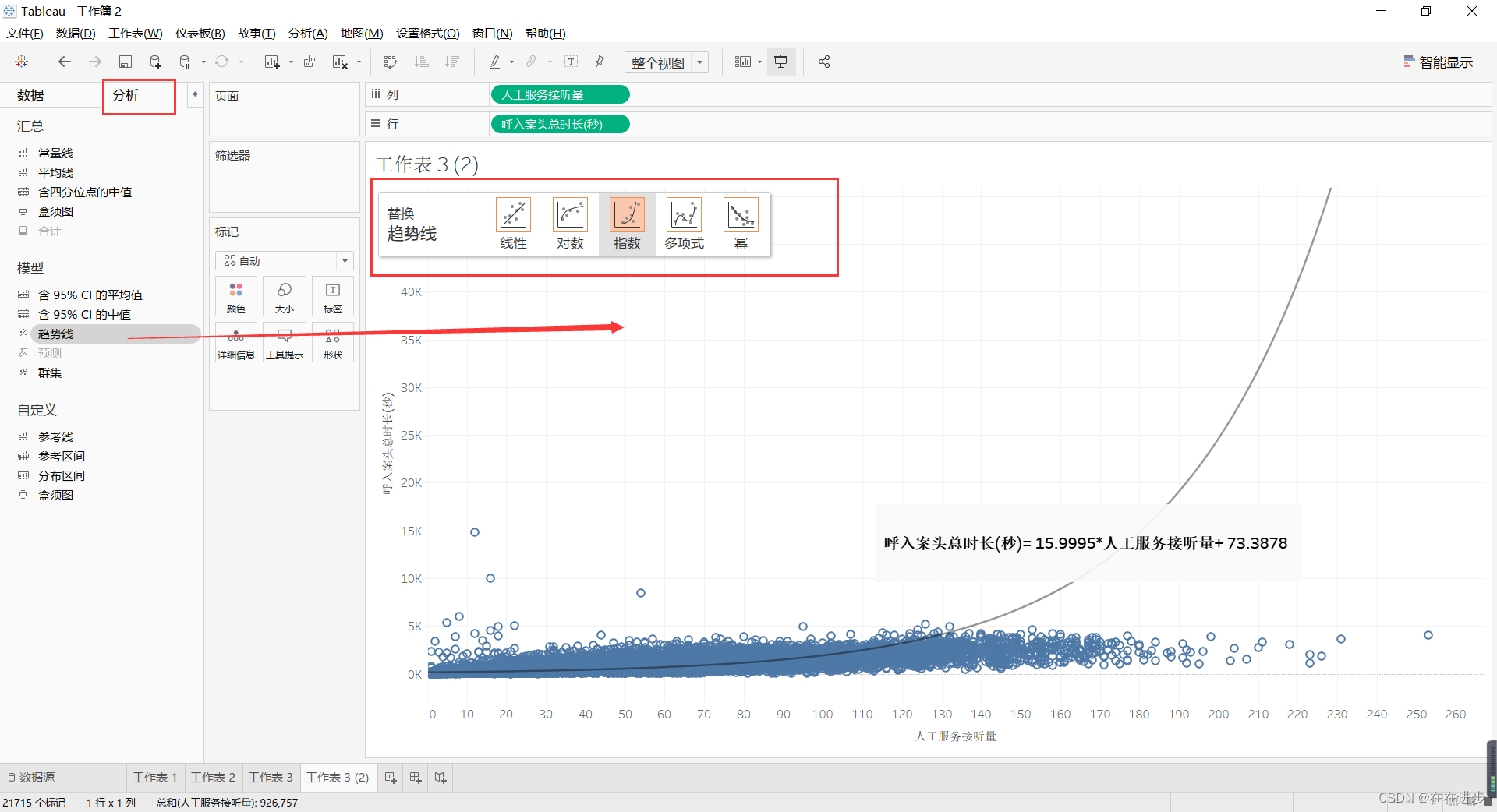
1 线性回归分析
导入数据并添加趋势线
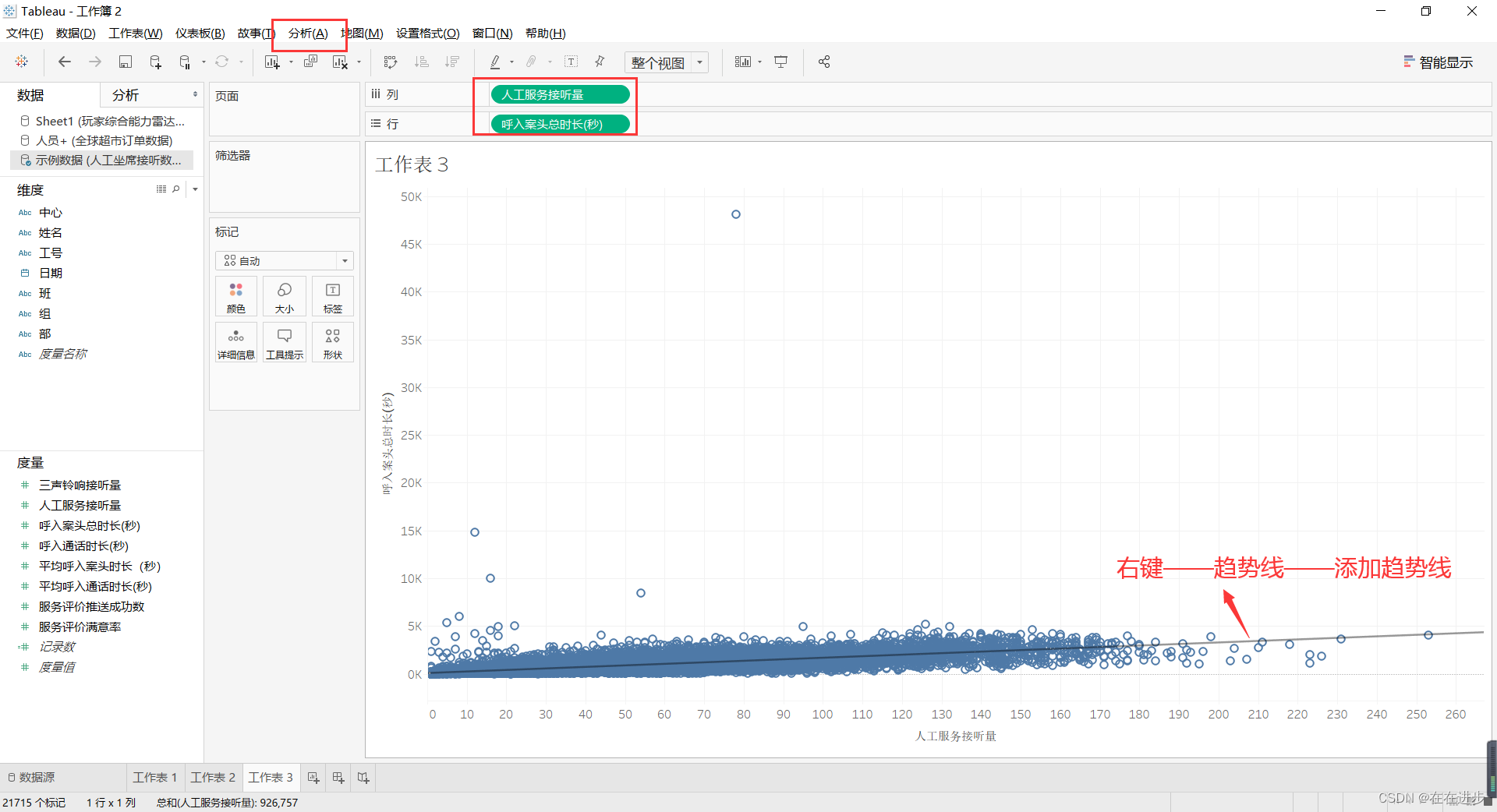
R平方值:越大越好,表示拟合优度
P值:越小越好,决定了系数(15.9995)的可信程度
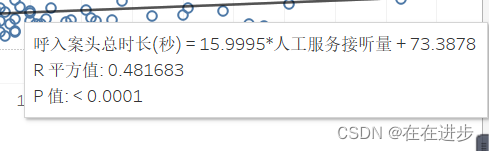
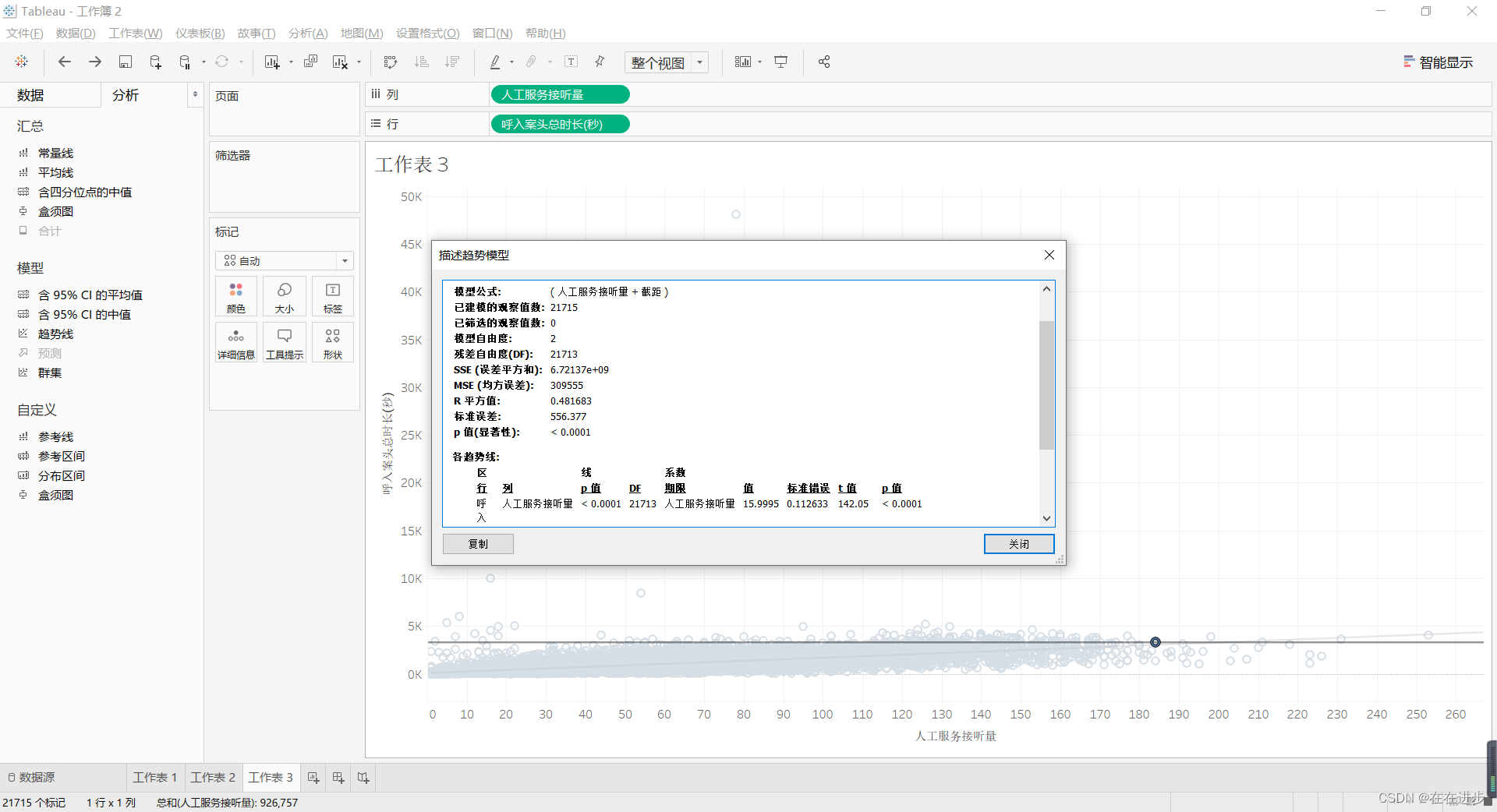
选中线——右键——描述趋势线:
工作区右键——添加区域注释:
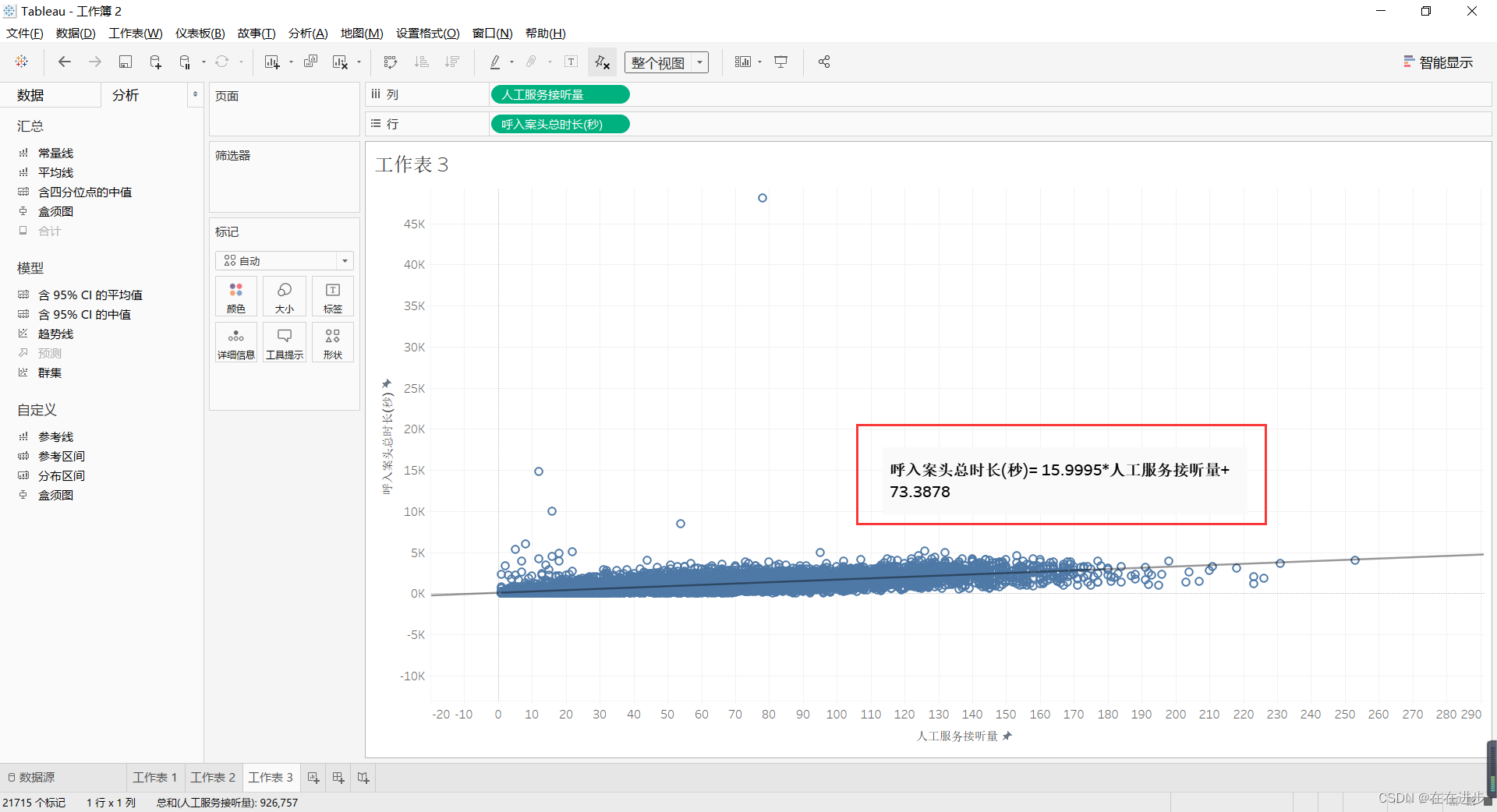
也可以在分析里面,直接往工作区域里面拖:
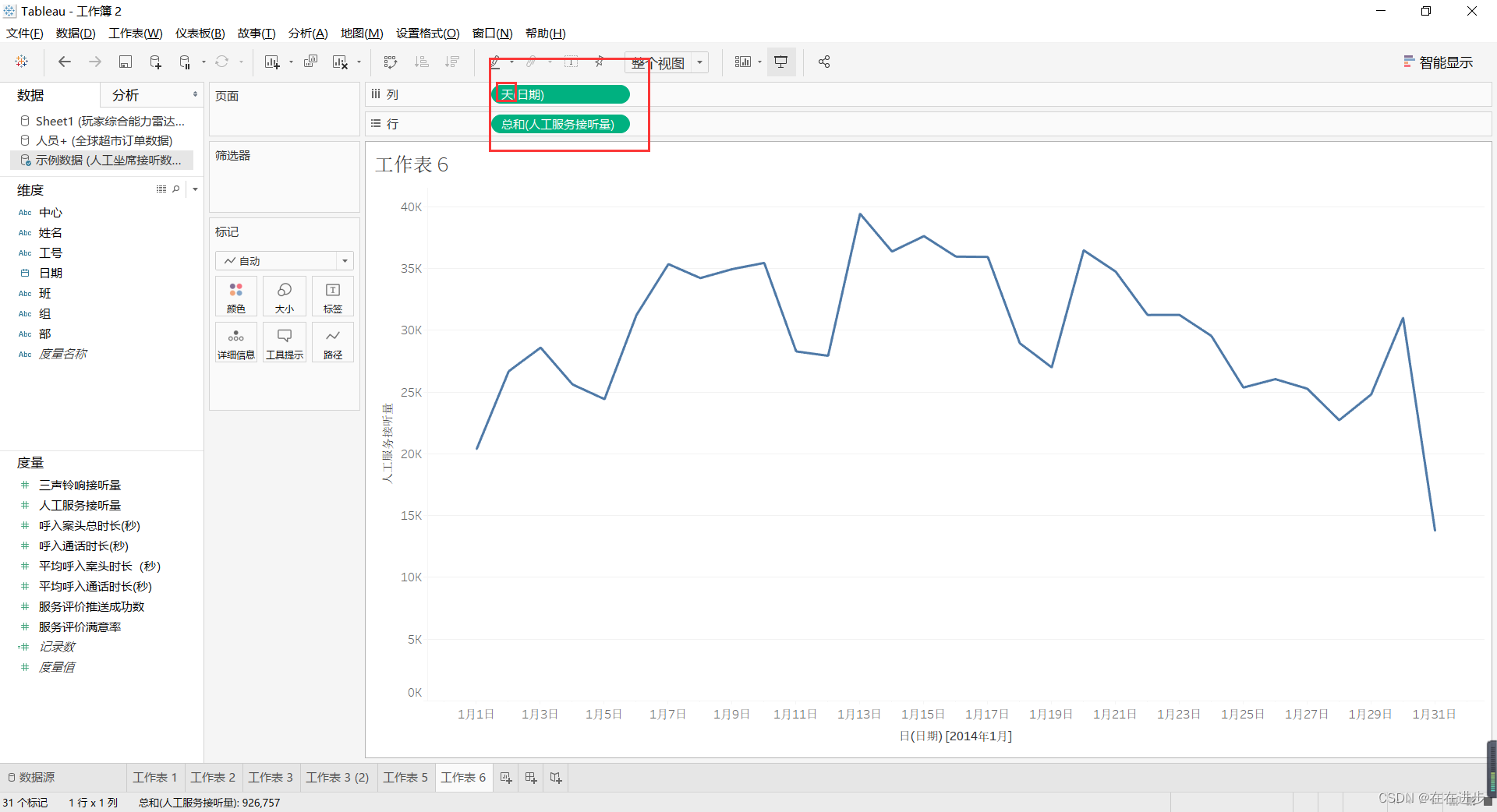
2 时间序列分析
可以自动预测拟合
(1)导入数据并将时间改为具体的天数,不能是维度,否则不能预测
(2)工作区右键——预测(日期类型不能错,都得是度量类型),默认为自动预测,意义不大
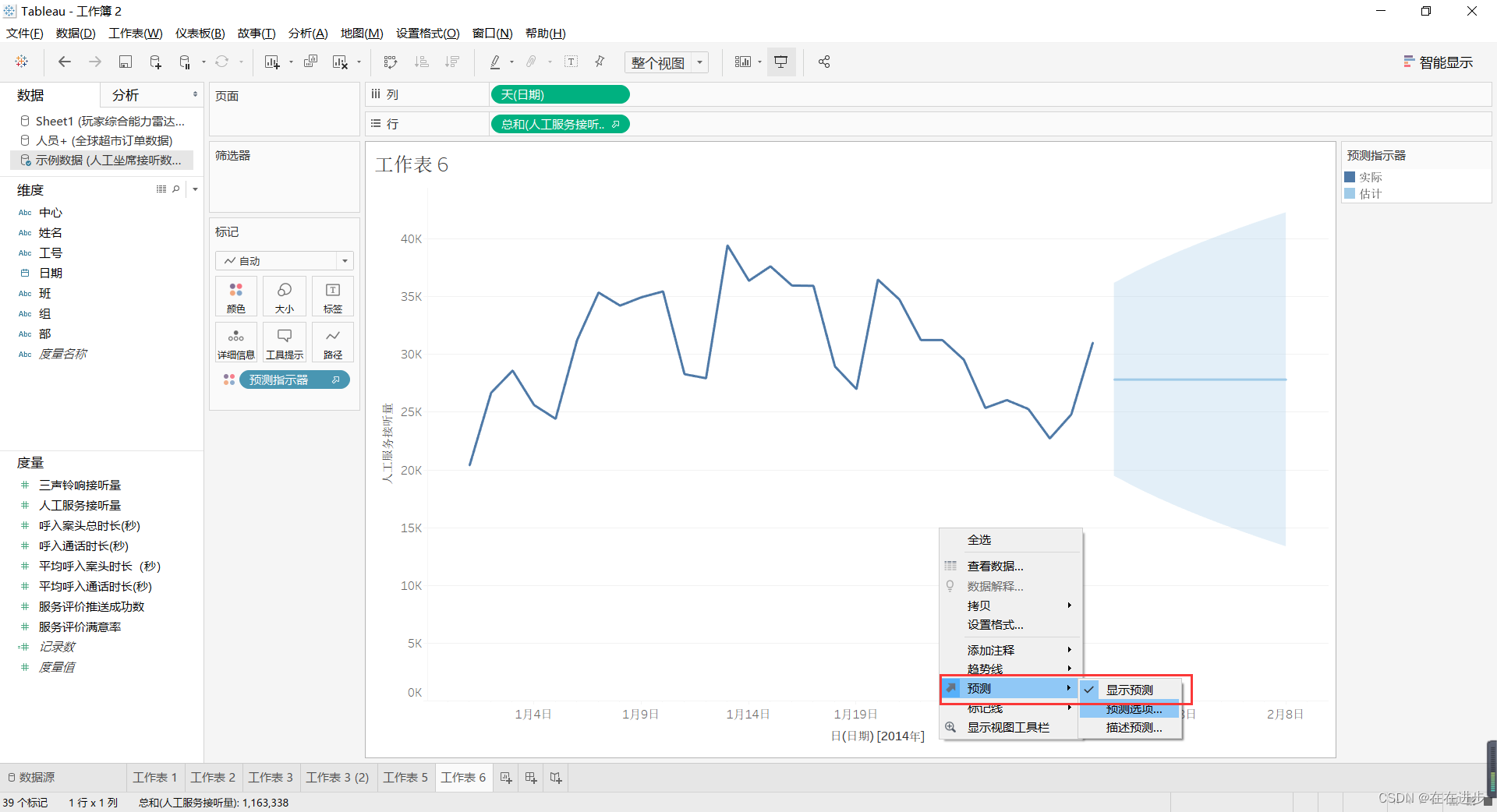
预测按钮为灰色,可能原因如下,因为跟时间有关,所以时间类型肯定很重要

(3)预测选项可以进行自定义编辑
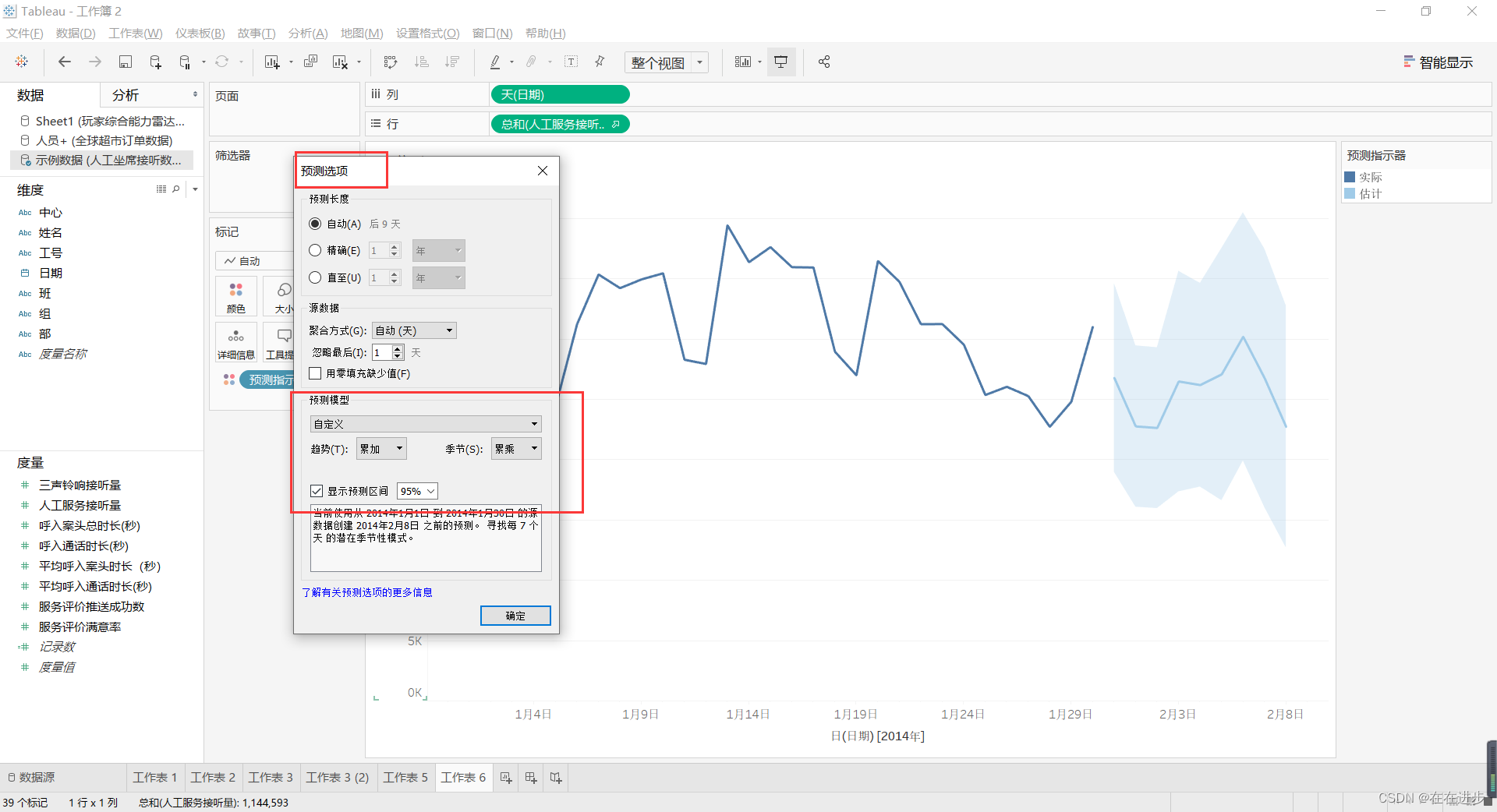
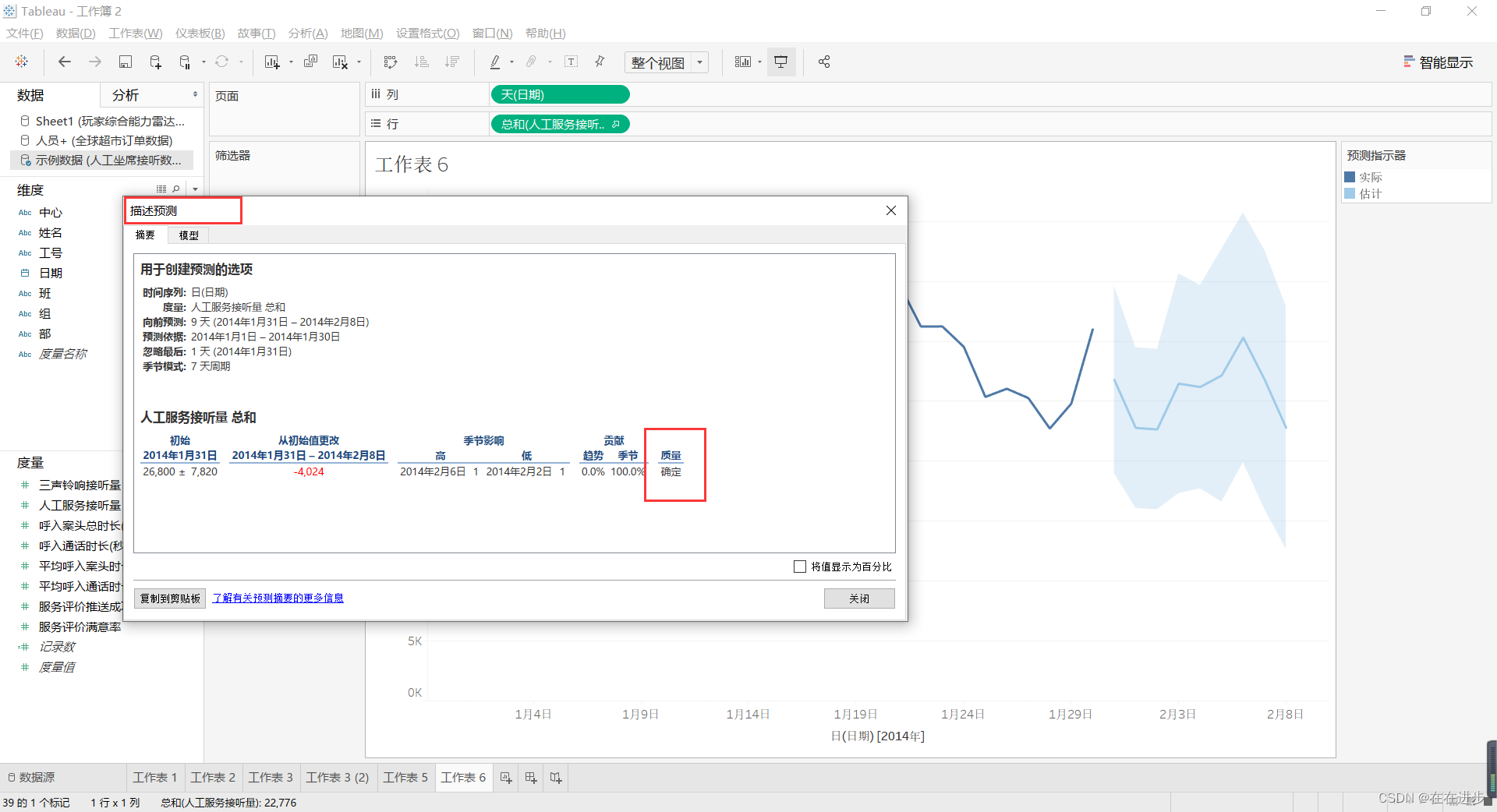
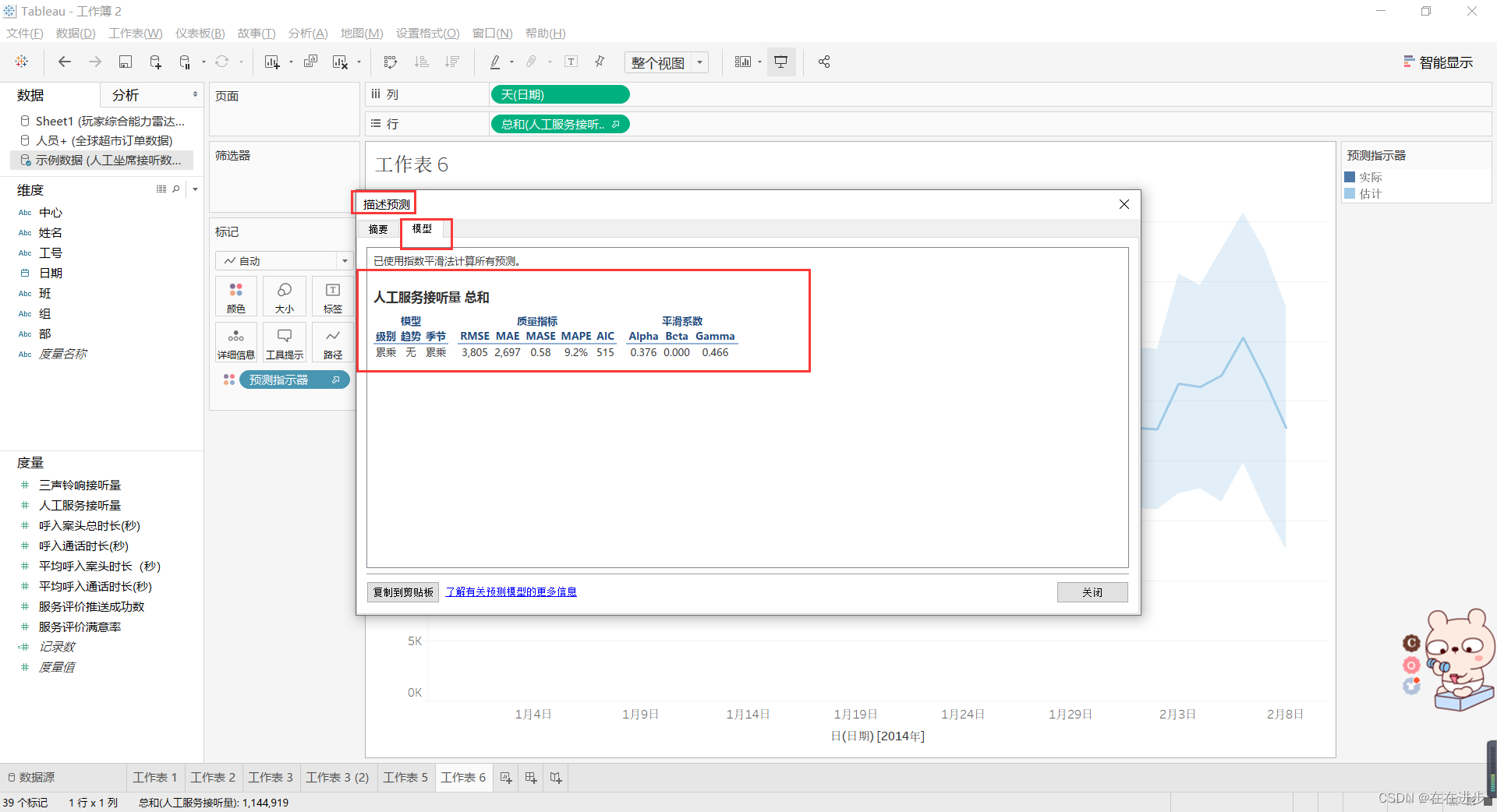
(4)查看预测的质量等模型参数再来进行自定义的调整
累乘适合数据集变化很大的情况,这种情况累加无法反应
数据下载链接:https://pan.baidu.com/s/1F0V2bvGOLIcM0PgQ1z_BHA?pwd=83g7
提取码:83g7

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









