







数据的标准化(Standardization)和归一化(Normalization)是数据预处理中的两种常见技术。
为社么要进行标准化和归一化?
1、样本不同的特征 / 属性所在的数值范围差异巨大,导致训练不收敛或其他问题。
2、所有数据在相同的取值空间更容易处理,方便模型的统一化和规范化,更好地适应模型或数据分析方法。
3、更容易发现数据的本质规律。
一、归一化(Normalization)
- 将数据按比例缩放,使之落入一个小的特定区间,通常是[0, 1]或[-1, 1]
- 归一化有多种方法,其中最常见的是最小-最大归一化(Min-Max Normalization)
- 它的数学公式如下:
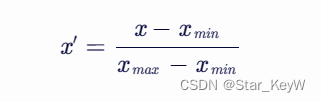
其中的最大值和最小值,均来自训练集
- 代码实现:
-
# MinMaxScaler 是 scikit-learn 中的一个类,用于将数据特征缩放到一个指定的范围(通常是 [0, 1]),或将数据按每个特征的最大绝对值缩放到单位范围内。 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() # scikit-learn的转换器通常期望输入是二维的,其中每一行代表一个样本,每一列代表一个特征 # fit方法计算了数据中每个特征的最小值和最大值,这些值将被用于缩放 # transform 方法使用这些统计信息来实际缩放数据,将其转换到 [0, 1] 范围内 scaled_result = scaler.fit_transform(data)
-
- 直观展示:

归一化对异常值非常敏感,因为异常值可能会显著影响xmin和xmax的值。
二、标准化(Standardization)
- 也称为Z值归一化(Z-Score Normalization),将数据转换到0值附近
- 线性变换,是将每一维特征的均值都调整为0,标准差(方差)调整为1
- 标准差指数据间的差异程度,数据差异越大,标准差越大
- 进行标准化后,数据并非一定呈现正态分布,若想改变数据的整体形态,需要采取非线性变换(eg:取对数、平方根...)
- 它的数学公式如下:
- z 是标准化后的值
- μ 是原始数据的均值
- σ 是原始数据的标准差
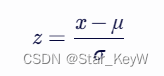
- 代码实现:
-
# 将特征值缩放到平均值为0,标准差为1的分布 from sklearn.preprocessing import StandardScaler # 使用训练集拟合StandardScaler scaler = StandardScaler() # 使用训练集拟合的参数来转换测试集 standardized_data = scaler.fit_transform(data)
-
















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











