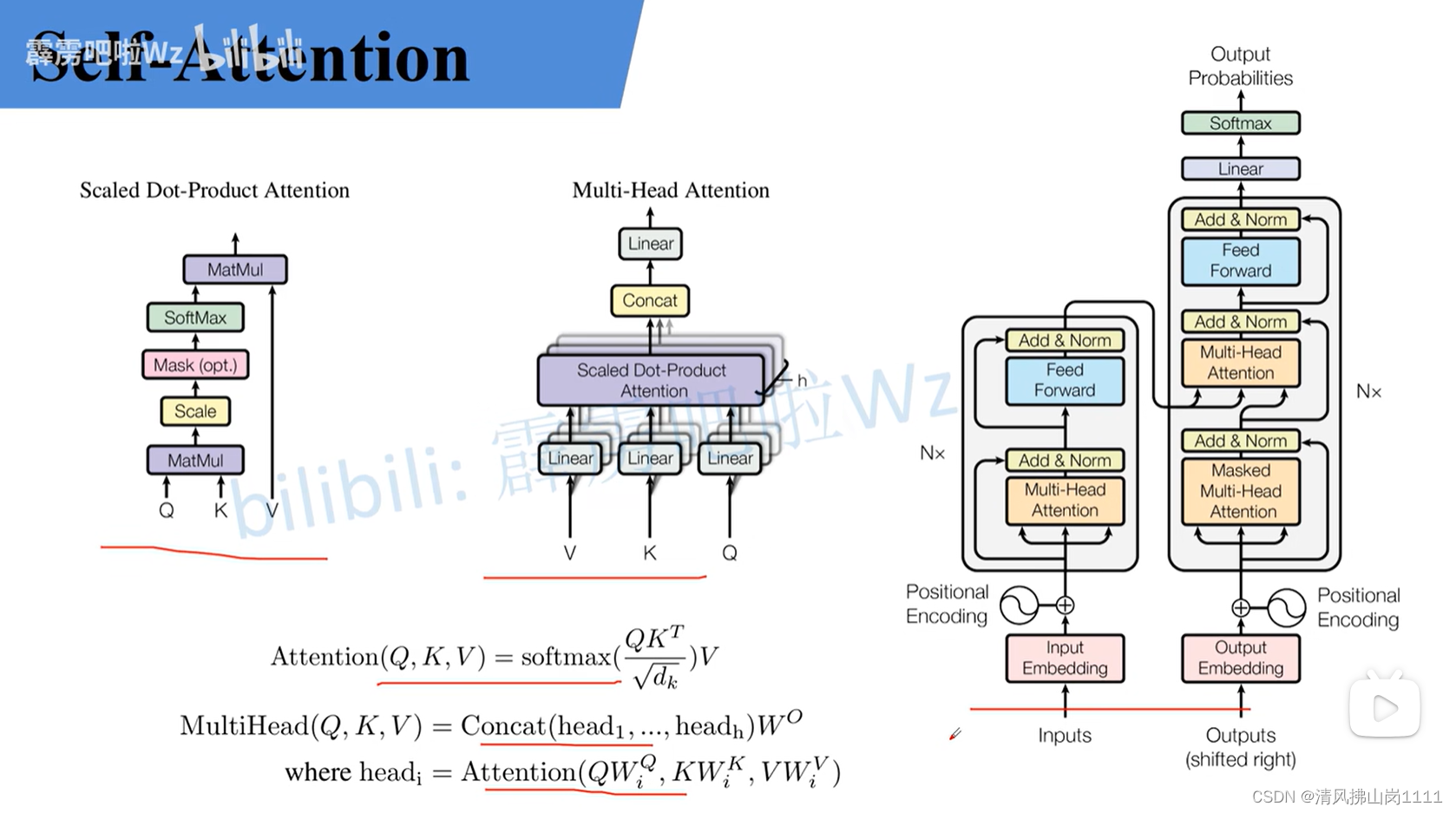
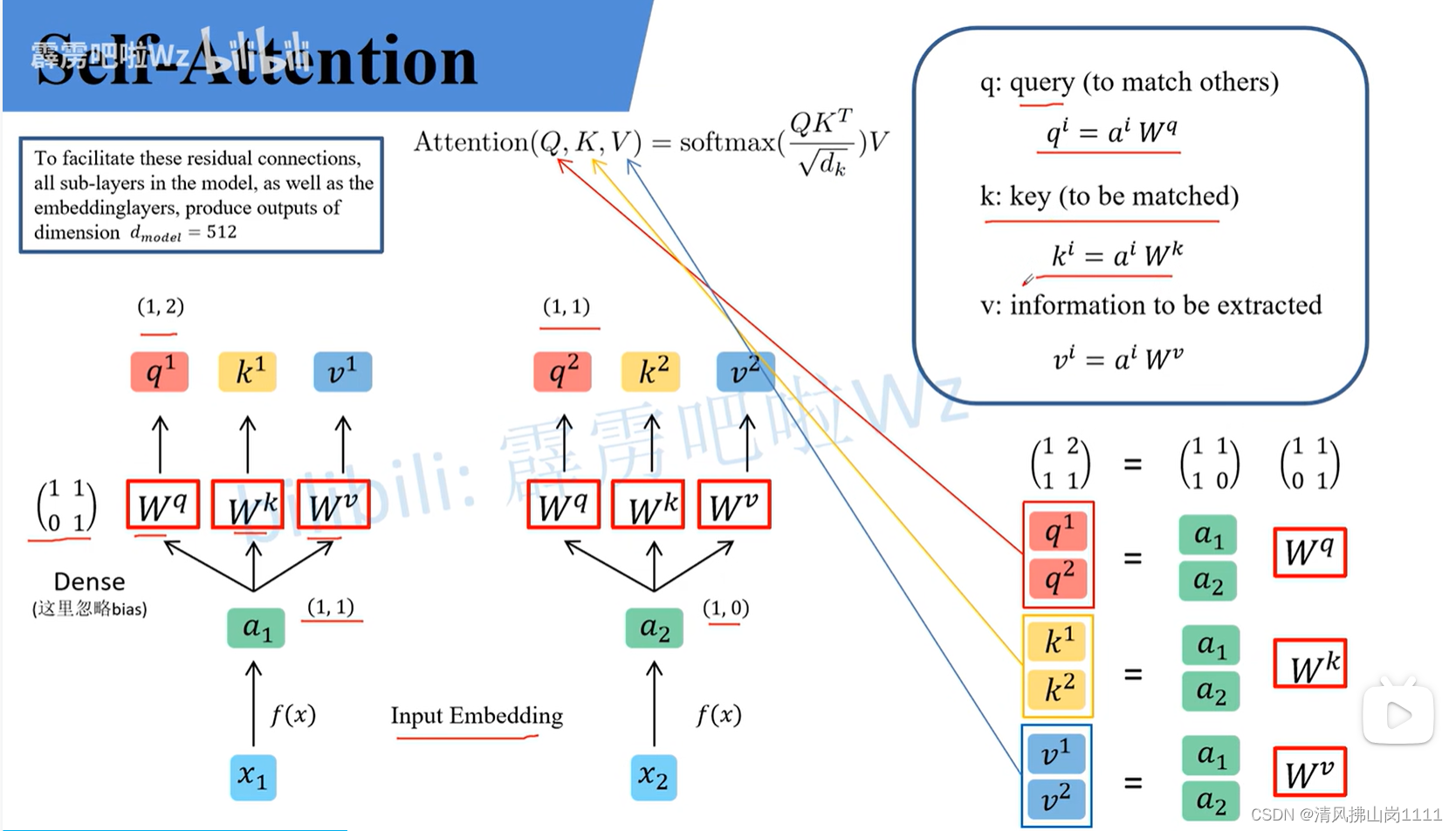
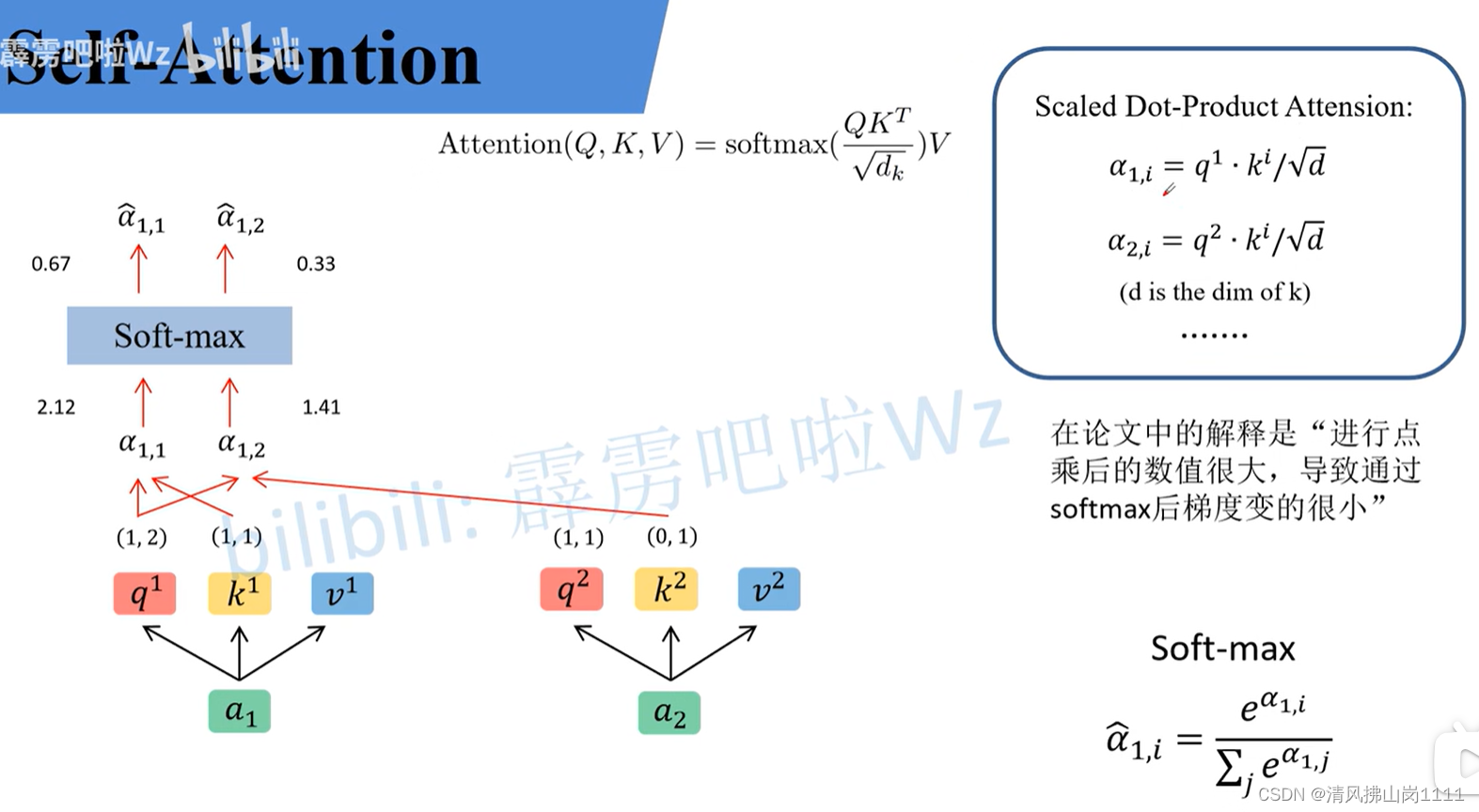
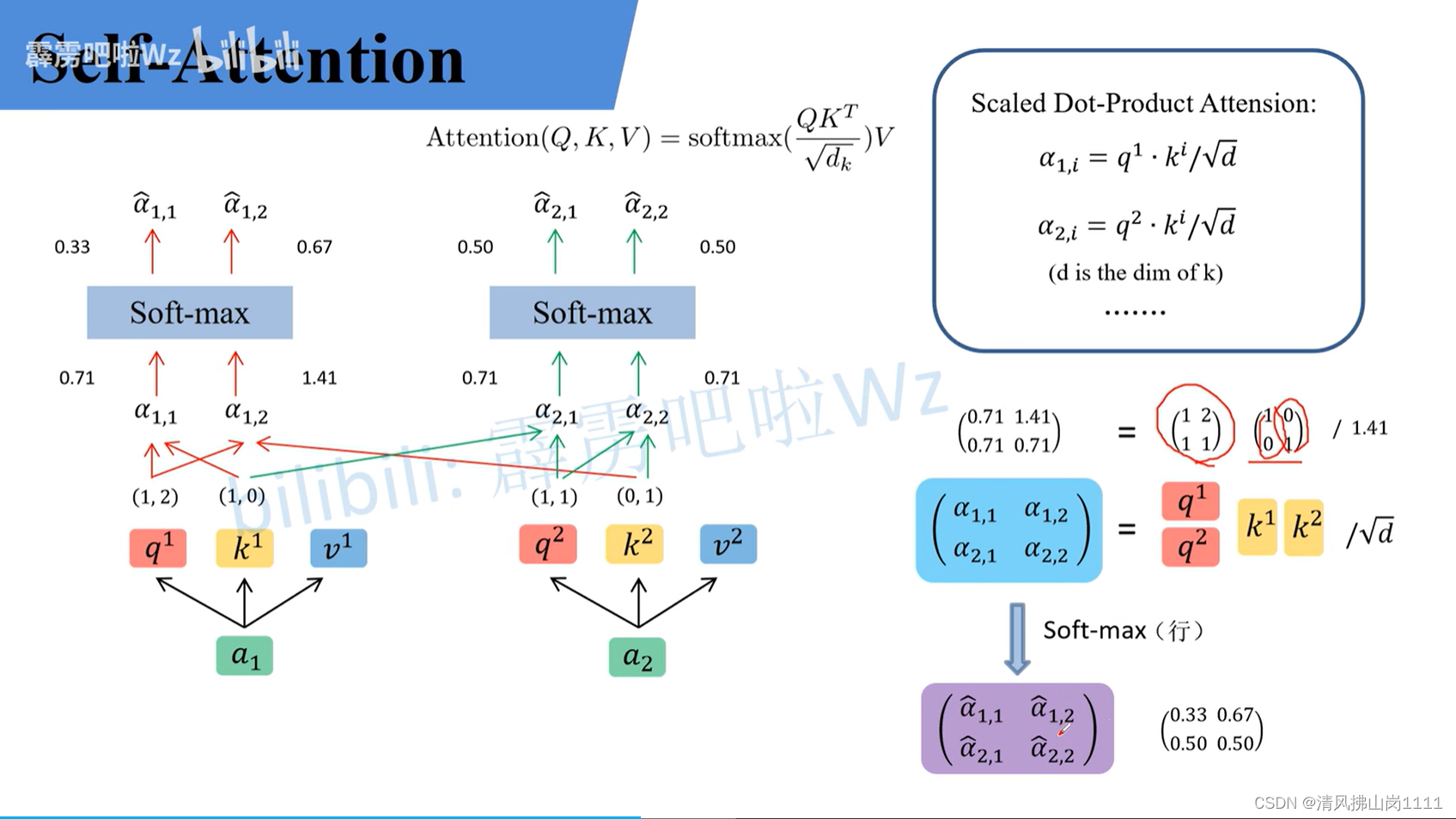
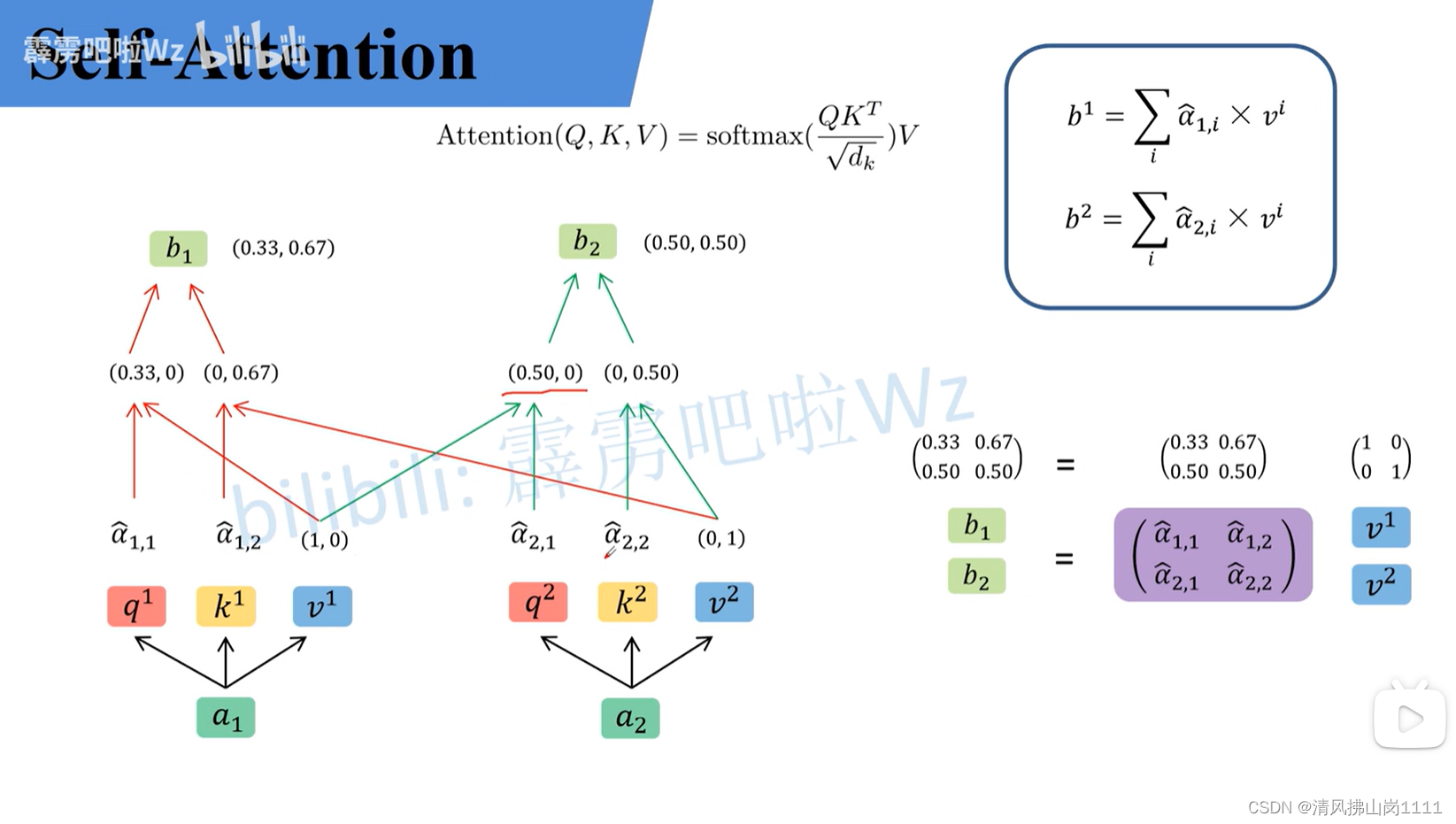
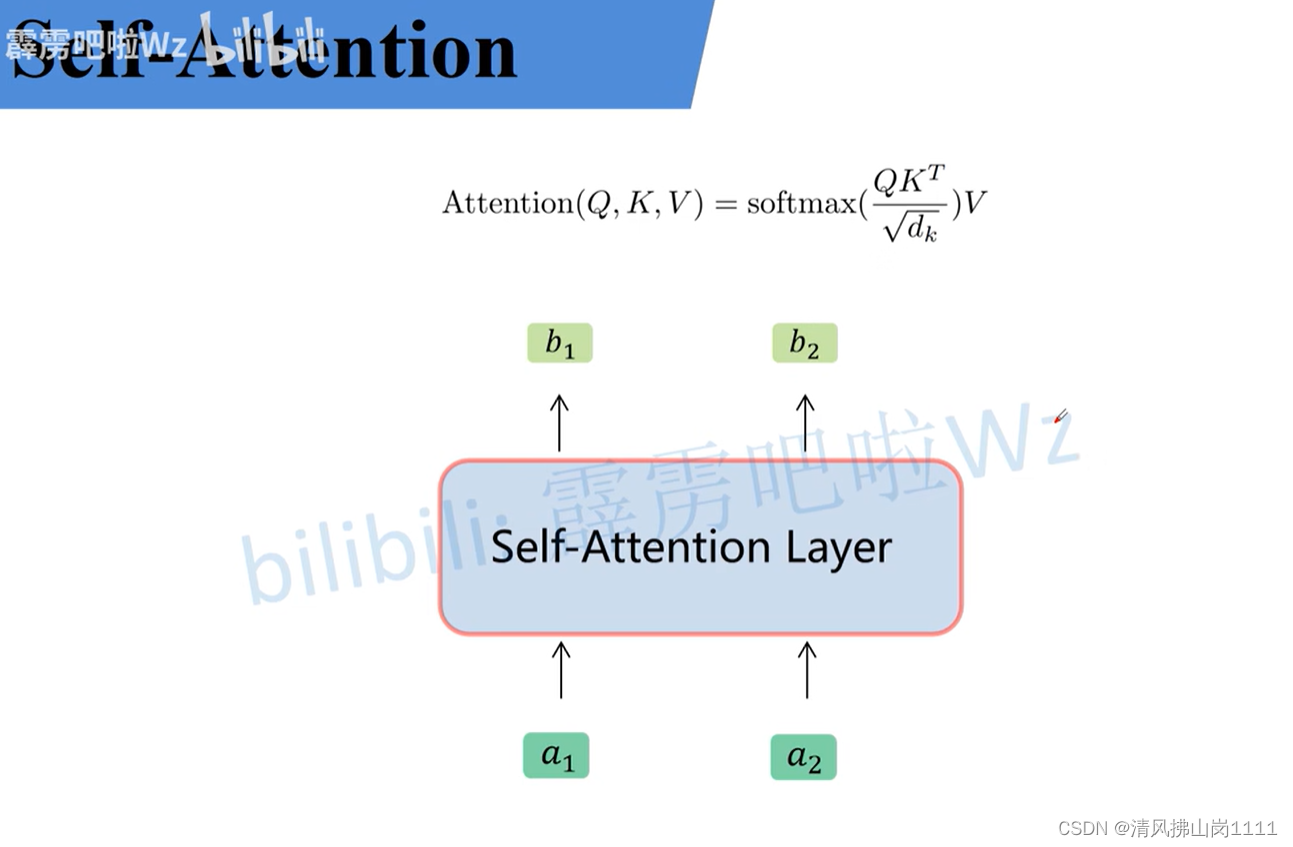
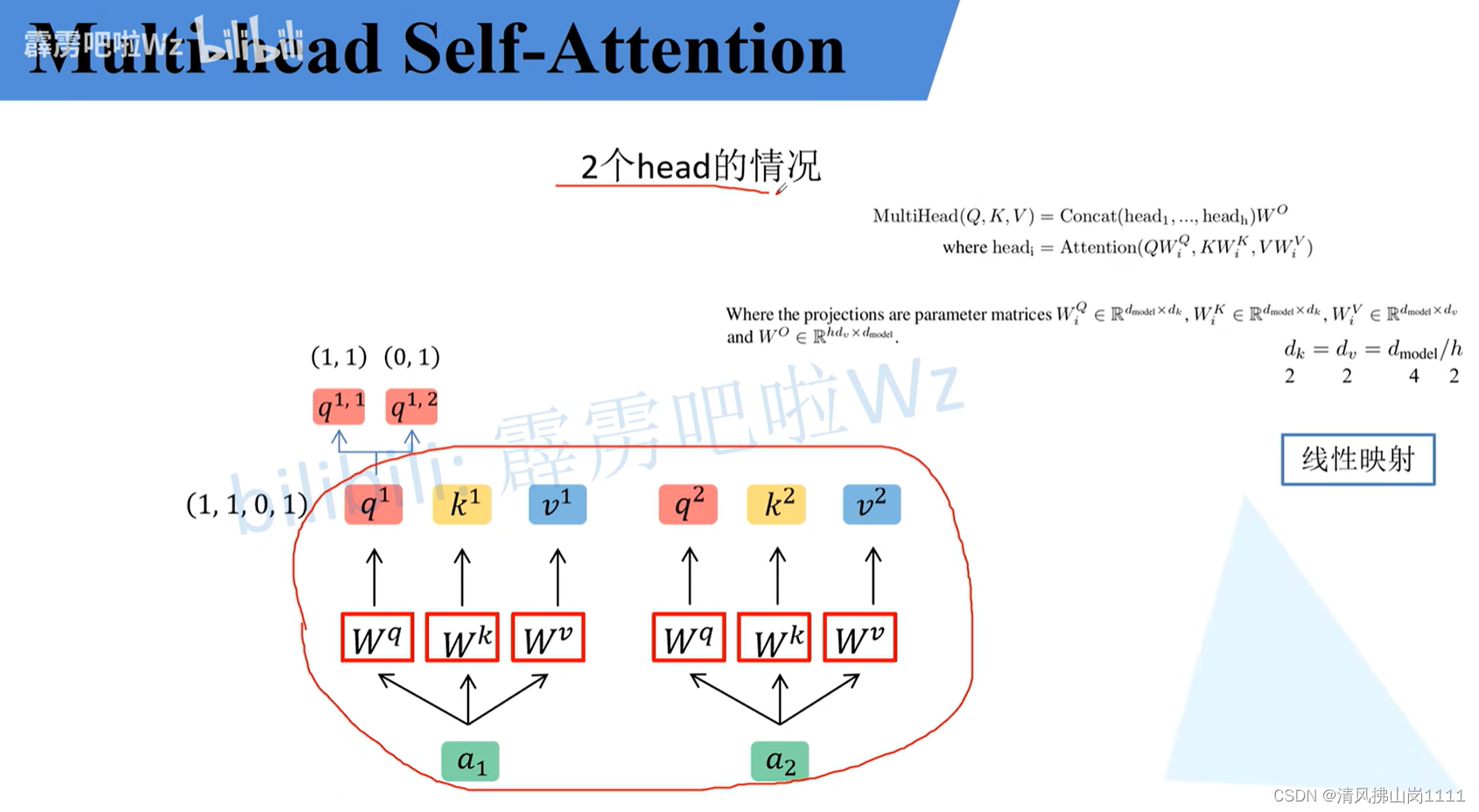
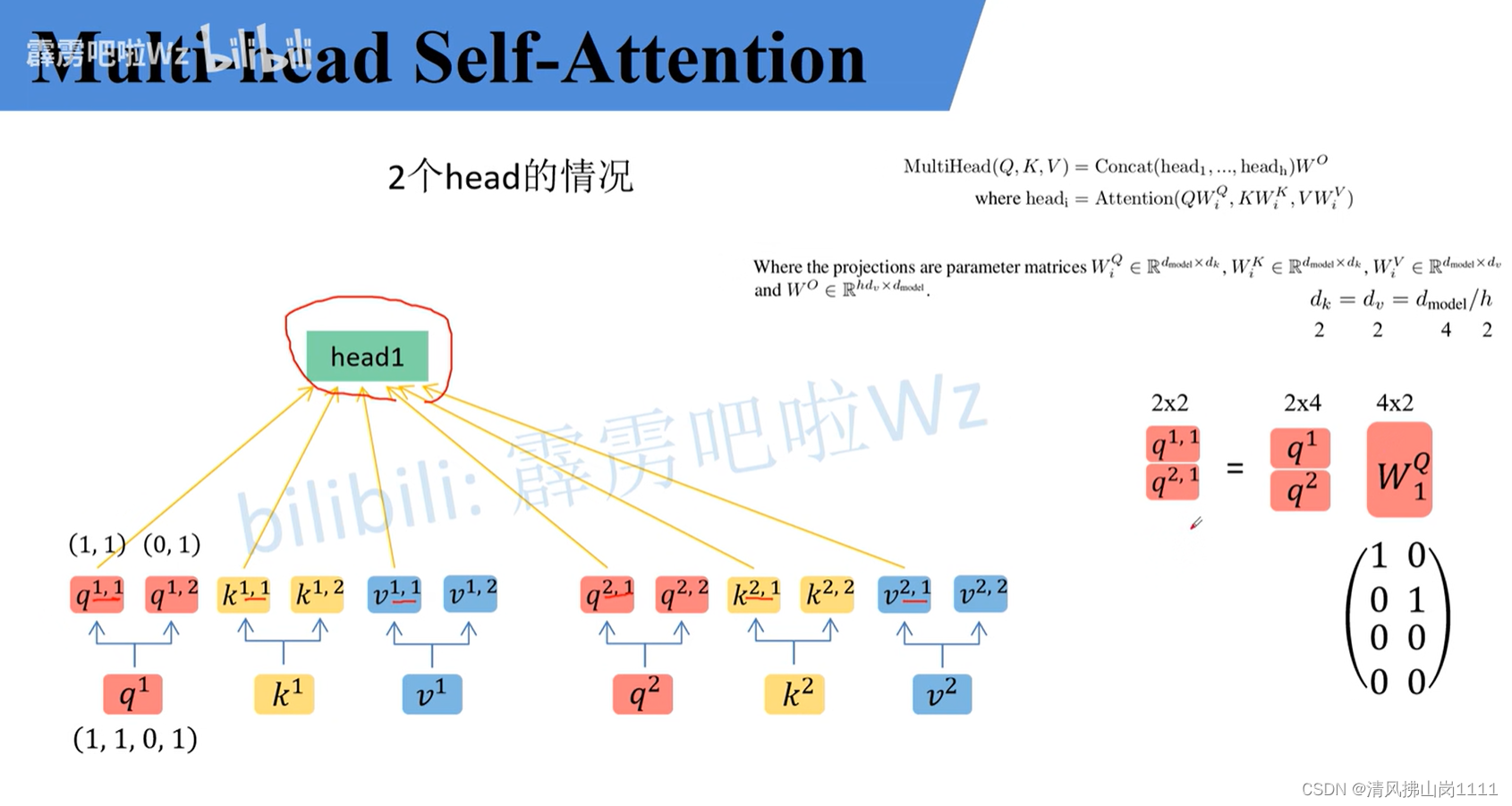
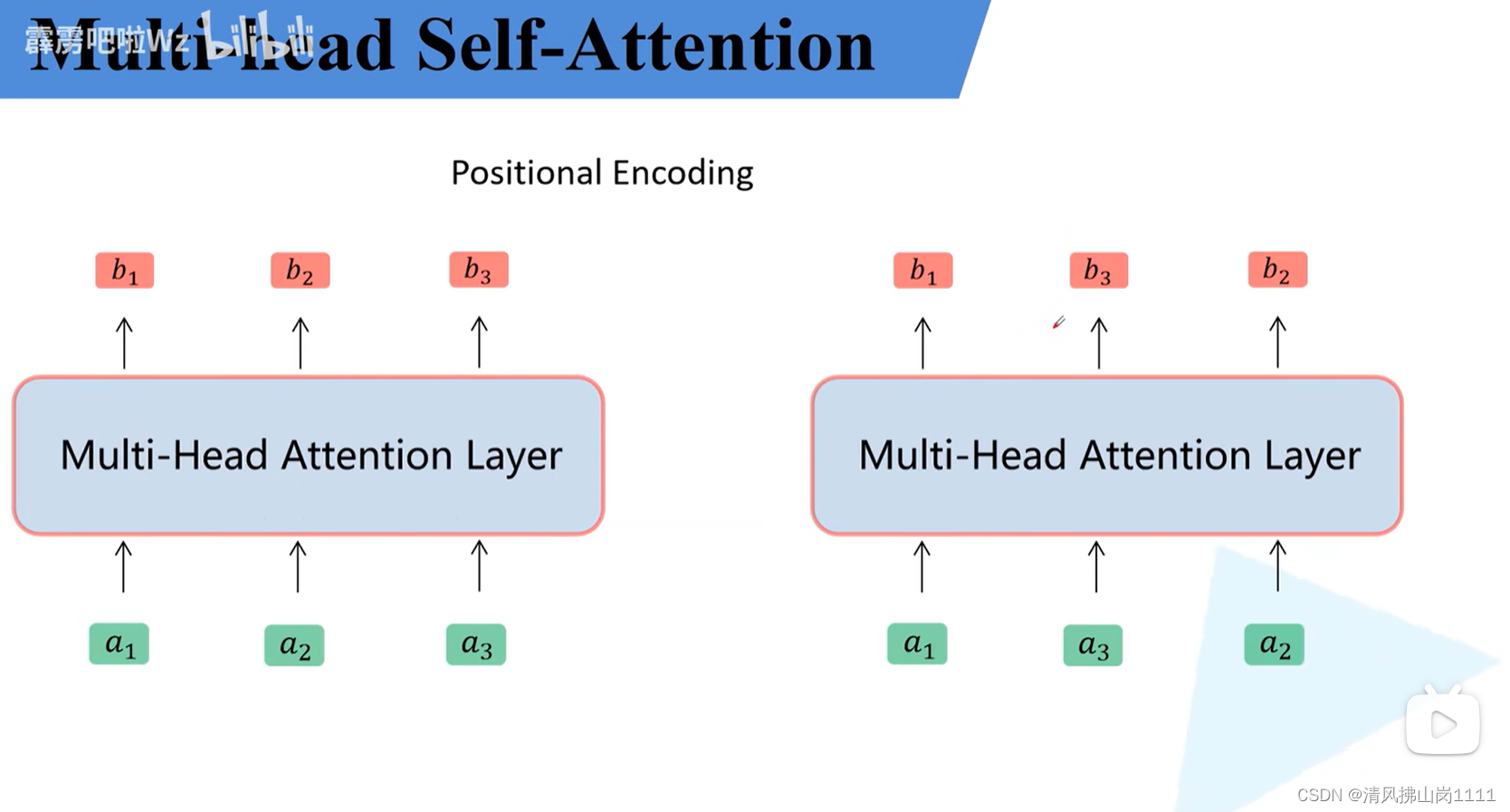
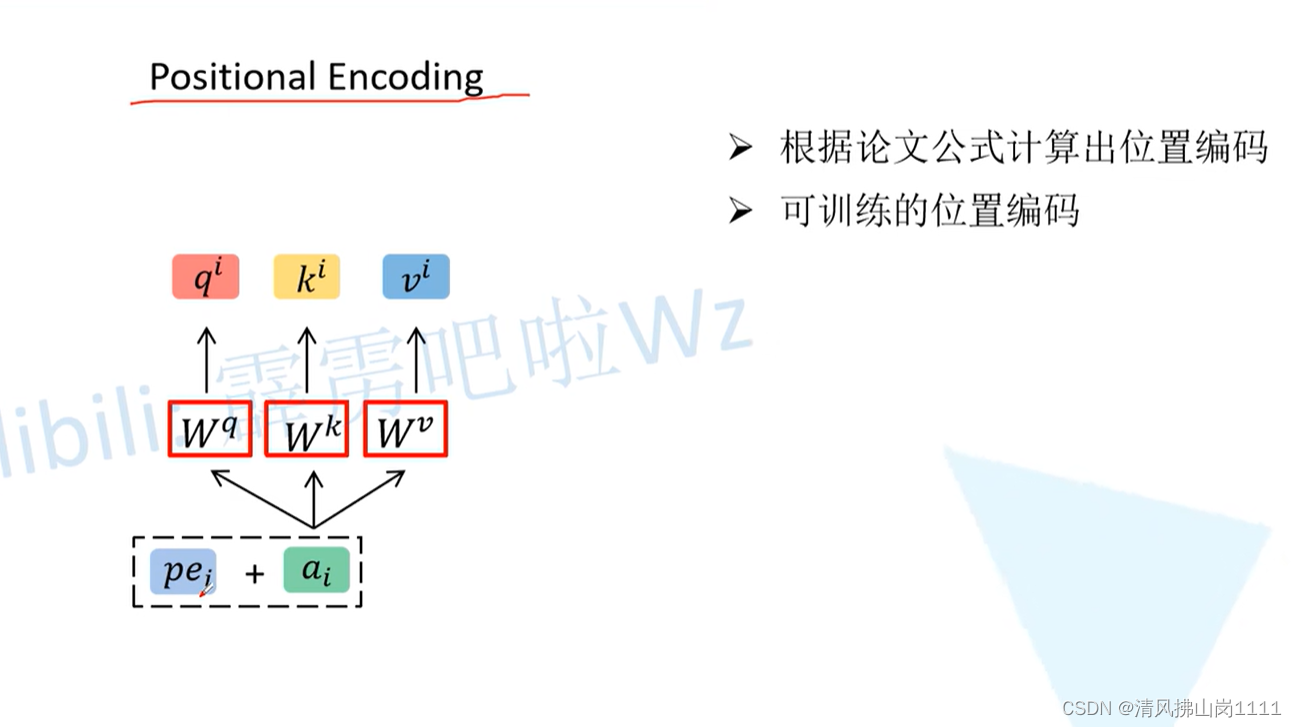
参考链接:详解Transformer中Self-Attention以及Multi-Head Attention_transformer multi head-CSDN博客文章浏览阅读10w+次,点赞873次,收藏2.4k次。原文名称:Attention Is All You Need原文链接:https://arxiv.org/abs/1706.03762最近Transformer在CV领域很火,Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的(之前的RNN模型记忆长度有限且无法并行化,只有计算完tit_iti时刻后的数据才能计算ti+1t_{i+1}ti+1时刻的数据,但Transformer可以)。在这篇文章中作者提出了S_transformer multi headhttps://blog.csdn.net/qq_37541097/article/details/117691873 b站讲解:Transformer中Self-Attention以及Multi-Head Attention详解_哔哩哔哩_bilibili 图解(视频截图):
























 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









