







本文目录
本文代码基础
基础请查看:Python及Torch基础篇
一、依赖
环境依赖:
nltk==3.5
numpy==1.18.5
seaborn==0.11.1
matplotlib==3.3.2
psyco==1.6
zhtools==0.0.5
#torch==1.12.1 安装torch时使用下面的命令
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113 -i https://pypi.tuna.tsinghua.edu.cn/simple
代码导入包 :
import copy
import math
import matplotlib.pyplot as plt
import numpy as np
import os
import seaborn as sns
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import Counter
from nltk import word_tokenize
from torch.autograd import Variable
初始化参数:
PAD = 0 # padding占位符的索引
UNK = 1 # 未登录词标识符的索引
BATCH_SIZE = 128 # 批次大小
EPOCHS = 20 # 训练轮数
LAYERS = 6 # transformer中encoder、decoder层数
H_NUM = 8 # 多头注意力个数
D_MODEL = 256 # 输入、输出词向量维数
D_FF = 1024 # feed forward全连接层维数
DROPOUT = 0.1 # dropout比例
MAX_LENGTH = 60 # 语句最大长度
TRAIN_FILE = 'nmt/en-cn/train.txt' # 训练集
DEV_FILE = "nmt/en-cn/dev.txt" # 验证集
SAVE_FILE = 'save/model.pt' # 模型保存路径
#DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
DEVICE = 'cuda'
二、数据准备
数据集可以去网络上下载,下面的是train.txt文件部分内容,前面为英文,后面为繁体中文,中间以'\t'隔开。其他数据文件也相同。

Ⅰ 操作流程
- 读取txt文件,将英文和中文句子以
‘\t’分割,分别存储到不同的列表中,并将列表的句子按单词进行切割存放。且每句话前加上开始字符’BOS’,句末加上结束字符’EOS’。如下:
en = [
['BOS', 'anyone', 'can', 'do', 'that', '.', 'EOS'],
['BOS', 'how', 'about', 'another', 'piece', 'of', 'cake', '?', 'EOS'],
['BOS', 'she', 'married', 'him', '.', 'EOS']
]
cn=[
['BOS', '任', '何', '人', '都', '可', '以', '做', '到', '。', 'EOS'],
['BOS', '要', '不', '要', '再', '來', '一', '塊', '蛋', '糕', '?', 'EOS'],
['BOS', '她', '嫁', '给', '了', '他', '。', 'EOS']
]
- 构建字典:中文字典和英文字典。按英文列表为例,①首先将列表里每句话的所有单词统一存到一个新列表中。即一个列表包含了所有英文单词。②统计字典里有多少个词:先统计每个单词重复出现的个数,按次数从大到小排序,将单词和其出现的次数构成一个元组,即(单词,次数),存放到列表中,这样我们统计列表里元组的个数,就可以知道该字典有多少个词。③构建字典:使用enumerate函数获取列表里元素及其索引,并将元素(元组)的第一个值(也就是单词)与索引用
':'拼接成{‘单词’ :索引,… }存放到字典里,这样就构成了英文字典。中文字典同样如此。
存放到同一个列表中:
['BOS', 'anyone', 'can', 'do', 'that', '.', 'EOS', 'BOS', 'how', 'about', 'another', 'piece', 'of', 'cake', '?', 'EOS', 'BOS', 'she', 'married', 'him', '.', 'EOS']
统计单词出现次数:
Counter({'BOS': 3, 'EOS': 3, '.': 2, 'anyone': 1, 'can': 1, 'do': 1, 'that': 1, 'how': 1, 'about': 1, 'another': 1, 'piece': 1, 'of': 1, 'cake': 1, '?': 1, 'she': 1, 'married': 1, 'him': 1})
构成元组:
[('BOS', 3), ('EOS', 3), ('.', 2), ('anyone', 1), ('can', 1), ('do', 1), ('that', 1), ('how', 1), ('about', 1), ('another', 1), ('piece', 1), ('of', 1), ('cake', 1), ('?', 1), ('she', 1), ('married', 1), ('him', 1)]
构建字典:
word_dict ={'BOS': 2, 'EOS': 3, '.': 4, 'anyone': 5, 'can': 6, 'do': 7, 'that': 8, 'how': 9, 'about': 10, 'another': 11, 'piece': 12, 'of': 13, 'cake': 14, '?': 15, 'she': 16, 'married': 17, 'him': 18, 'PAD': 0, 'UNK': 1}
- 建立一个新列表(new_en),将步骤1中的句子里的单词按照字典的索引替换到新列表中。不改变源句子列表。再将替换后的列表元素,按长度排序。以方便后续填充时,填充的0最少。中文列表也是如此操作!
"""句子"""
en = [
['BOS', 'anyone', 'can', 'do', 'that', '.', 'EOS'],
['BOS', 'how', 'about', 'another', 'piece', 'of', 'cake', '?', 'EOS'],
['BOS', 'she', 'married', 'him', '.', 'EOS']
]
"""字典"""
word_dict ={'BOS': 2, 'EOS': 3, '.': 4, 'anyone': 5, 'can': 6, 'do': 7, 'that': 8, 'how': 9, 'about': 10, 'another': 11, 'piece': 12, 'of': 13, 'cake': 14, '?': 15, 'she': 16, 'married': 17, 'him': 18, 'PAD': 0, 'UNK': 1}
"""(1)替换"""
new_en = [
[2, 5, 6, 7, 8, 4, 3],
[2, 9, 10, 11, 12, 13, 14, 15, 3],
[2, 16, 17, 18, 4, 3]
]
"""(2)按长度排序"""
new_en = [
[2, 16, 17, 18, 4, 3],
[2, 5, 6, 7, 8, 4, 3],
[2, 9, 10, 11, 12, 13, 14, 15, 3]
]
- 模型输入是文本序列,而这些文本序列的长度是不一样的。为了将它们组成一个批次(batch)并输入到模型中,你需要确保它们的长度相同。但是,为了达到相同的长度,你可能需要在较短的序列后面填充一些特殊的标记,如使用0进行标记。将排序后索引列表划分为多个batch,并将每个batch里的列表按照该batch里列表的最长长度进行填充,以0进行填充。然后将填充好的数据创建掩码。
"""为了方便演示,自定义了列表元素作为排序后的索引列表"""
new_en = [
[2, 16, 4, 3],
[2, 5, 6, 4, 3],
[2, 5, 6, 7, 8, 4, 3],
[2, 5, 6, 7, 8, 3,2],
[2, 9, 10, 11, 12, 13, 14, 15, 3]
]
batch=3 #假设batch=3
"""(1)按batch进行填充"""
new_en = [
[2, 16, 4, 3, 0, 0, 0],
[2, 5, 6, 4, 3, 0, 0],
[2, 5, 6, 7, 8, 4, 3],
[2, 5, 6, 7, 8, 3, 2, 0, 0],
[2, 9, 10, 11, 12, 13, 14, 15, 3]
]
"""(2)创建掩码,看后续内容即可"""
- 这样我们就准备好了数据。
① 英文字典。
② 中文字典。
③ 英文数据:按batch填充好的字典索引列表。
④ 中文数据:按batch填充好的中文字典索引列表。
Ⅱ 总代码
封装成一个类,方便模块化管理。
import copy
import math
import matplotlib.pyplot as plt
import numpy as np
import os
import seaborn as sns
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import Counter
from nltk import word_tokenize
from torch.autograd import Variable
UNK=1
PAD=1
BATCH_SIZE=128
DEV_FILE = 'E:/Desktop/Document/4. Python/例程代码/dev_mini.txt' # 训练集
TRAIN_FILE = "E:/Desktop/Document/4. Python/例程代码/train_mini.txt" # 验证集
DEVICE='cpu'
PAD = 0 # 填充元素
def subsequent_mask(size):
attn_shape = (1, size, size)
# attn_shape =(1, 11, 11)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# np.ones(attn_shape) 会生成一个形状为 attn_shape 的全为1的矩阵。
# np.triu() 函数将这个矩阵转换为上三角矩阵。
# 参数 k 控制了主对角线以上的偏移量。当 k=0 时,生成的是包含主对角线在内的上三角矩阵;当 k=1 时,生成的是主对角线以上偏移一个单位的上三角矩阵。
# 返回一个右上角(不含主对角线)为全False,左下角(含主对角线)为全True的subsequent_mask矩阵
return torch.from_numpy(subsequent_mask) == 0
# torch.from_numpy(subsequent_mask) 将 NumPy 数组 subsequent_mask 转换为 PyTorch 张量。
# 然后,== 0 表示对张量中的每个元素进行逐元素比较,检查是否等于0。最终返回的是一个布尔类型的张量,其中每个元素都是与0比较的结果,即True或False。即等于0为True,等于1为False。
def seq_padding(X, padding=PAD):
"""
按批次(batch)对数据填充、长度对齐
"""
# 计算该批次各条样本语句长度
Length = [len(x) for x in X]
# 获取该批次样本中语句长度最大值
MaxLength = max(Length)
# 遍历该批次样本,如果语句长度小于最大长度,则用padding填充
return np.array([
np.concatenate([x, [padding] * (MaxLength - len(x))]) if len(x) < MaxLength else x for x in X
])
def subsequent_mask(size):
attn_shape = (1, size, size)
# attn_shape =(1, 11, 11)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# np.ones(attn_shape) 会生成一个形状为 attn_shape 的全为1的矩阵。
# np.triu() 函数将这个矩阵转换为上三角矩阵。
# 参数 k 控制了主对角线以上的偏移量。当 k=0 时,生成的是包含主对角线在内的上三角矩阵;当 k=1 时,生成的是主对角线以上偏移一个单位的上三角矩阵。
# 返回一个右上角(不含主对角线)为全False,左下角(含主对角线)为全True的subsequent_mask矩阵
return torch.from_numpy(subsequent_mask) == 0
# torch.from_numpy(subsequent_mask) 将 NumPy 数组 subsequent_mask 转换为 PyTorch 张量。
# 然后,== 0 表示对张量中的每个元素进行逐元素比较,检查是否等于0。最终返回的是一个布尔类型的张量,其中每个元素都是与0比较的结果,即True或False。即等于0为True,等于1为False。
def seq_padding(X, padding=PAD):
"""
按批次(batch)对数据填充、长度对齐
"""
# 计算该批次各条样本语句长度
Length = [len(x) for x in X]
# 获取该批次样本中语句长度最大值
MaxLength = max(Length)
# 遍历该批次样本,如果语句长度小于最大长度,则用padding填充
return np.array([
np.concatenate([x, [padding] * (MaxLength - len(x))]) if len(x) < MaxLength else x for x in X
])
class Batch:
"""
批次类
1. 输入序列(源)
2. 输出序列(目标)
3. 构造掩码
"""
def __init__(self, src, trg=None, pad=PAD):
# 将src、trg转为tensor格式,将数据放到设备上并规范成整数类型
src = torch.from_numpy(src).to(DEVICE).long()
# src =tensor([[ 2, 16, 17, 18, 4, 3, 0],[ 2, 5, 6, 7, 8, 4, 3]])
trg = torch.from_numpy(trg).to(DEVICE).long()
# trg =tensor([[ 2, 22, 23, 24, 25, 26, 4, 3, 0, 0, 0], [ 2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3]])
self.src = src
# self.src= tensor([[ 2, 16, 17, 18, 4, 3, 0],[ 2, 5, 6, 7, 8, 4, 3]])
# (src != pad):这部分代码会生成一个与输入序列 src 形状相同的布尔张量,其中真实单词的位置为 True,填充部分的位置为 False。并在seq length前面增加一维,形成维度为 1×seq length 的矩阵
self.src_mask = (src != pad).unsqueeze(-2)
"""self.src_mask=tensor([[[ True, True, True, True, True, True, False]],
[[ True, True, True, True, True, True, True]]])"""
# self.src_mask.shape= torch.Size([2, 1, 7])
# 如果输出目标不为空,则需要对解码器使用的目标语句进行掩码
if trg is not None:
# 解码器使用的目标输入部分
self.trg = trg[:, : -1] # 去除最后一列
# self.trg=tensor([[ 2, 22, 23, 24, 25, 26, 4, 3, 0, 0],[ 2, 6, 7, 8, 9, 10, 11, 12, 13, 4]])
# 解码器训练时应预测输出的目标结果
self.trg_y = trg[:, 1:] # 去除第一列的
# self.trg_y=tensor([[22, 23, 24, 25, 26, 4, 3, 0, 0, 0],[ 6, 7, 8, 9, 10, 11, 12, 13, 4, 3]])
# 将目标输入部分进行注意力掩码
self.trg_mask = self.make_std_mask(self.trg, pad)
# 生成一个大小为self.trg.size(-1)的掩码矩阵,下三角为True,上三角为False
# 将应输出的目标结果中真实的词数进行统计
self.ntokens = (self.trg_y != pad).data.sum()
# self.ntokens=tensor(17)
# 掩码操作
# 这个操作的目的是在训练解码器时,确保解码器在预测当前时间步的词时只能依赖之前的词,而不能依赖未来的词
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
# 这部分代码会生成一个与目标序列 tgt 形状相同的布尔张量,其中真实单词的位置为 True,填充部分的位置为 False。并在倒数第二维度上添加一个新维度。
# tgt_mask =tensor([[[True, True, True, True, True, True, True, True, True, True, True]]])
tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
# subsequent_mask(tgt.size(-1)):生成一个大小为tgt.size(-1)的下三角形的矩阵,上三角部分为0,下三角部分和对角线为1。
# Variable(...).type_as(tgt_mask.data):将生成的下三角形矩阵转换为与目标序列掩码相同的数据类型和设备类型。
# (tgt_mask & ...): 对上面生成的下三角形矩阵与目标序列掩码进行逻辑与操作,得到最终的目标序列掩码。
return tgt_mask
class PrepareData:
def __init__(self, train_file, dev_file):
# 读取数据、分词
self.train_en, self.train_cn = self.load_data(train_file)
self.dev_en, self.dev_cn = self.load_data(dev_file)
# 构建词表
self.en_word_dict, self.en_total_words, self.en_index_dict = \
self.build_dict(self.train_en)
self.cn_word_dict, self.cn_total_words, self.cn_index_dict = \
self.build_dict(self.train_cn)
# 单词映射为索引
self.train_en, self.train_cn = self.word2id(self.train_en, self.train_cn, self.en_word_dict, self.cn_word_dict)
self.dev_en, self.dev_cn = self.word2id(self.dev_en, self.dev_cn, self.en_word_dict, self.cn_word_dict)
# 划分批次、填充、掩码
self.train_data = self.split_batch(self.train_en, self.train_cn, BATCH_SIZE)
self.dev_data = self.split_batch(self.dev_en, self.dev_cn, BATCH_SIZE)
def load_data(self, path):
"""
读取英文、中文数据
对每条样本分词并构建包含起始符和终止符的单词列表
形式如:en = [['BOS', 'i', 'love', 'you', 'EOS'], ['BOS', 'me', 'too', 'EOS'], ...]
cn = [['BOS', '我', '爱', '你', 'EOS'], ['BOS', '我', '也', '是', 'EOS'], ...]
"""
en = []
cn = []
with open(path, mode="r", encoding="utf-8") as f:
for line in f.readlines():
sent_en, sent_cn = line.strip().split("\t")
sent_en = sent_en.lower()
# sent_cn = cht_to_chs(sent_cn)
sent_en = ["BOS"] + word_tokenize(sent_en) + ["EOS"]
# 中文按字符切分
sent_cn = ["BOS"] + [char for char in sent_cn] + ["EOS"]
en.append(sent_en)
cn.append(sent_cn)
return en, cn
def build_dict(self, sentences, max_words=5e4):
"""
构造分词后的列表数据
构建单词-索引映射(key为单词,value为id值)
"""
# 统计数据集中单词词频
word_count = Counter([word for sent in sentences for word in sent])
# 按词频保留前max_words个单词构建词典
# 添加UNK和PAD两个单词
ls = word_count.most_common(int(max_words))
total_words = len(ls) + 2
word_dict = {w[0]: index + 2 for index, w in enumerate(ls)}
word_dict['UNK'] = UNK
word_dict['PAD'] = PAD
# 构建id2word映射
index_dict = {v: k for k, v in word_dict.items()}
return word_dict, total_words, index_dict
def word2id(self, en, cn, en_dict, cn_dict, sort=True):
"""
将英文、中文单词列表转为单词索引列表
`sort=True`表示以英文语句长度排序,以便按批次填充时,同批次语句填充尽量少
"""
length = len(en)
# 单词映射为索引
out_en_ids = [[en_dict.get(word, UNK) for word in sent] for sent in en]
out_cn_ids = [[cn_dict.get(word, UNK) for word in sent] for sent in cn]
# 按照语句长度排序
def len_argsort(seq):
"""
传入一系列语句数据(分好词的列表形式),
按照语句长度排序后,返回排序后原来各语句在数据中的索引下标
"""
return sorted(range(len(seq)), key=lambda x: len(seq[x]))
# 按相同顺序对中文、英文样本排序
if sort:
# 以英文语句长度排序
sorted_index = len_argsort(out_en_ids)
out_en_ids = [out_en_ids[idx] for idx in sorted_index]
out_cn_ids = [out_cn_ids[idx] for idx in sorted_index]
return out_en_ids, out_cn_ids
def split_batch(self, en, cn, batch_size, shuffle=True):
"""
划分批次
`shuffle=True`表示对各批次顺序随机打乱
"""
# 每隔batch_size取一个索引作为后续batch的起始索引
idx_list = np.arange(0, len(en), batch_size)
# 起始索引随机打乱
if shuffle:
np.random.shuffle(idx_list)
# 存放所有批次的语句索引
batch_indexs = []
for idx in idx_list:
"""
形如[array([4, 5, 6, 7]),
array([0, 1, 2, 3]),
array([8, 9, 10, 11]),
...]
"""
# 起始索引最大的批次可能发生越界,要限定其索引
batch_indexs.append(np.arange(idx, min(idx + batch_size, len(en))))
# 构建批次列表
batches = []
for batch_index in batch_indexs:
# 按当前批次的样本索引采样
batch_en = [en[index] for index in batch_index]
batch_cn = [cn[index] for index in batch_index]
# 对当前批次中所有语句填充、对齐长度
# 维度为:batch_size * 当前批次中语句的最大长度
batch_cn = seq_padding(batch_cn)
batch_en = seq_padding(batch_en)
# 将当前批次添加到批次列表
# Batch类用于实现注意力掩码
batches.append(Batch(batch_en, batch_cn))
return batches
if __name__ == '__main__':
data = PrepareData(TRAIN_FILE, DEV_FILE) # 实例化类
"""类的一些成员变量
print(data.en_word_dict) #文件里所有英文组成一个字典。{'BOS': 2, 'EOS': 3, '.': 4, 'i': 5, 'the': 6, 'you': 7, 'to': 8, ......}
print(data.cn_word_dict) #文件里所有中文组成一个字典。{'BOS': 2, 'EOS': 3, '。': 4, '我': 5, '的': 6, '了': 7, ......}
print(data.cn_total_words)
print(data.en_total_words)
print(data.en_index_dict) #{2: 'BOS', 3: 'EOS', 4: '.', 5: 'i', 6: 'the', 7: 'you', 8: 'to', 9: 'a', 10: '?',。....}
print(data.cn_index_dict)
print(data.dev_data)
"""
print(data.dev_cn)#[[2, 5, 1273, 7, 4, 3], [2, 5, 93, 7, 924, 34, 1, 4, 3], [2, 5, 61, 153, 694, 479, 4, 3], [2, 15, 47, 51, 48, 4, 3],....]
#print(data.train_data) #里面包含很多个batch,每个batch里有数据信息
# for index, batch in enumerate(data.train_data):
# print(batch.src) # 转为tensor的batch_en(每句话的英文单词在字典的索引构成的列表,且填充好)
# print(batch.trg) # 转为tensor的batch_cn(每句话的中文单词在字典的索引构成的列表,且填充好)
# print(batch.src_mask) # batch_en的掩码
# print(batch.trg_mask) # batch_cn的掩码
#
Ⅲ 代码解读
1. 数据加载
作用:读取数据路径下的完整句子,将每个句子分割为一个一个的单词,并存到子列表中。返回含有子列表的列表,
"""参数参数path 为数据的路径,如下
train_file= 'nmt/en-cn/train.txt' # 训练集
dev_file= "nmt/en-cn/dev.txt" # 验证集
load_data(train_file)
"""
def load_data(path):
"""
读取英文、中文数据
对每条样本分词并构建包含起始符和终止符的单词列表
"""
en = [] #定义英文列表
cn = [] #定义中文列表
with open(path, mode="r", encoding="utf-8") as f: #只读的形式打开文件路径,文件描述符为f。
for line in f.readlines(): #按行读取
sent_en, sent_cn = line.strip().split("\t") #以‘\t’进行分割,前面的赋给sent_en,后面的赋给sent_cn 。
sent_en = sent_en.lower() #将英文转换为小写。
sent_en = ["BOS"] + word_tokenize(sent_en) + ["EOS"]
# 中文按字符切分
sent_cn = ["BOS"] + [char for char in sent_cn] + ["EOS"]
en.append(sent_en) #将切割好的英文 存入英文列表。包含['BOS', 'i', 'love', 'you', 'EOS']
cn.append(sent_cn) #将切割好的中文 存入中文列表。
return en, cn #返回两个单词列表
"""
输出列表格式如下:
en = [
['BOS', 'anyone', 'can', 'do', 'that', '.', 'EOS'],
['BOS', 'how', 'about', 'another', 'piece', 'of', 'cake', '?', 'EOS'],
['BOS', 'she', 'married', 'him', '.', 'EOS']
]
cn=[
['BOS', '任', '何', '人', '都', '可', '以', '做', '到', '。', 'EOS'],
['BOS', '要', '不', '要', '再', '來', '一', '塊', '蛋', '糕', '?', 'EOS'],
['BOS', '她', '嫁', '给', '了', '他', '。', 'EOS']
]
"""
程序解析
word_tokenize()将字符串分割为一个个的单词,并由列表保存。
from nltk import word_tokenize
sent_en="He knows better than to marry her."
print(word_tokenize(sent_en))
# 输出为:['He', 'knows', 'better', 'than', 'to', 'marry', 'her', '.']
2. 构建单词表
"""输入
en = [
['BOS', 'anyone', 'can', 'do', 'that', '.', 'EOS'],
['BOS', 'how', 'about', 'another', 'piece', 'of', 'cake', '?', 'EOS'],
['BOS', 'she', 'married', 'him', '.', 'EOS']
]
或
cn=[
['BOS', '任', '何', '人', '都', '可', '以', '做', '到', '。', 'EOS'],
['BOS', '要', '不', '要', '再', '來', '一', '塊', '蛋', '糕', '?', 'EOS'],
['BOS', '她', '嫁', '给', '了', '他', '。', 'EOS']
]
"""
PAD = 0 # padding占位符的索引
UNK = 1 # 未登录词标识符的索引
def build_dict(sentences_list, max_words=5e4):
"""
构造分词后的列表数据
构建单词-索引映射(key为单词,value为id值)
"""
# Counter()-- 统计列表(迭代对象)各元素出现次数,并按次数从多到少排序。
word_count = Counter([word for sentences in sentences_list for word in sentences])
#输出 word_count= Counter({'BOS': 3, 'EOS': 3, '.': 2, 'anyone': 1, 'can': 1, 'do': 1, 'that': 1, 'how': 1, 'about': 1, 'another': 1, 'piece': 1, 'of': 1, 'cake': 1, '?': 1, 'she': 1, 'married': 1, 'him': 1})
#获取出现频率最高的前 50000 个元素及其个数,返回一个含有多个元组的列表。
ls = word_count.most_common(int(max_words))
#输出 ls =[('BOS', 3), ('EOS', 3), ('.', 2), ('anyone', 1), ('can', 1), ('do', 1), ('that', 1), ('how', 1), ('about', 1), ('another', 1), ('piece', 1), ('of', 1), ('cake', 1), ('?', 1), ('she', 1), ('married', 1), ('him', 1)]
total_words = len(ls) + 2
word_dict = {word [0]: index + 2 for index, word in enumerate(ls)}
#输出 word_dict ={'BOS': 2, 'EOS': 3, '.': 4, 'anyone': 5, 'can': 6, 'do': 7, 'that': 8, 'how': 9, 'about': 10, 'another': 11, 'piece': 12, 'of': 13, 'cake': 14, '?': 15, 'she': 16, 'married': 17, 'him': 18}
# 添加UNK和PAD两个单词
word_dict['UNK'] = UNK
word_dict['PAD'] = PAD
#输出 word_dict ={'BOS': 2, 'EOS': 3, '.': 4, 'anyone': 5, 'can': 6, 'do': 7, 'that': 8, 'how': 9, 'about': 10, 'another': 11, 'piece': 12, 'of': 13, 'cake': 14, '?': 15, 'she': 16, 'married': 17, 'him': 18, 'PAD': 0, 'UNK': 1}
# 构建索引和单词的映射
index_dict = {v: k for k, v in word_dict.items()}
#输出 index_dict ={2: 'BOS', 3: 'EOS', 4: '.', 5: 'anyone', 6: 'can', 7: 'do', 8: 'that', 9: 'how', 10: 'about', 11: 'another', 12: 'piece', 13: 'of', 14: 'cake', 15: '?', 16: 'she', 17: 'married', 18: 'him', 0: 'PAD', 1: 'UNK'}
return word_dict, total_words, index_dict
"""
输出:
en:
word_dict ={'BOS': 2, 'EOS': 3, '.': 4, 'anyone': 5, 'can': 6, 'do': 7, 'that': 8, 'how': 9, 'about': 10, 'another': 11, 'piece': 12, 'of': 13, 'cake': 14, '?': 15, 'she': 16, 'married': 17, 'him': 18, 'PAD': 0, 'UNK': 1}
index_dict= {2: 'BOS', 3: 'EOS', 4: '.', 5: 'anyone', 6: 'can', 7: 'do', 8: 'that', 9: 'how', 10: 'about', 11: 'another', 12: 'piece', 13: 'of', 14: 'cake', 15: '?', 16: 'she', 17: 'married', 18: 'him', 0: 'PAD', 1: 'UNK'}
"""
程序解析
(1)将列表里每个子列表的所有单词合并到一个新列表(没有子列表)中。
将sentences里面每句话的每个单词组合形成一个新的列表。
sentences_list = [
['BOS','I', 'love', 'natural', 'language', 'processing', '.', 'EOS'] ,
['BOS', 'Natural', 'language', 'processing', 'is', 'fascinating', '.', 'EOS']
]
word_count = [word for sentences in sentences_list for word in sentences]
"""
另一种写法:
word_list = []
for sentences in sentences_list :
for word in sentences:
word_list.append(word)
"""
print(word_count )
"""
输出: ['BOS', 'I', 'love', 'natural', 'language', 'processing', '.', 'EOS', 'BOS', 'Natural', 'language', 'processing', 'is', 'fascinating', '.', 'EOS']
"""
(2)Counter()-- 统计列表(迭代对象)各元素出现次数,并按次数从多到少排序。
from collections import Counter
#Python 中的一个内置数据结构
# 定义一个列表
word_list = ['BOS', 'I', 'love', 'natural', 'language', 'processing', '.', 'EOS', 'BOS', 'Natural', 'language', 'processing', 'is', 'fascinating', '.', 'EOS']
# 使用 Counter 统计列表中各元素的出现次数
word_count = Counter(word_list)
print(word_count )
"""
输出: Counter({'BOS': 2, 'language': 2, 'processing': 2, '.': 2, 'EOS': 2, 'I': 1, 'love': 1, 'natural': 1, 'Natural': 1, 'is': 1, 'fascinating': 1})
"""
(3)获取出现频率最高的前 50000 个元素及其个数,返回一个含有多个元组的列表。
如: [ (元素1,频次),(元素2,频次),… ]
from collections import Counter
word_count = Counter({'BOS': 2, 'language': 2, 'processing': 2, '.': 2, 'EOS': 2, 'I': 1, 'love': 1, 'natural': 1, 'Natural': 1, 'is': 1, 'fascinating': 1})
ls = word_count.most_common(int(5e4))#返回列表中频率最高的元素和它们的计数,按照计数从高到低排序。频率最高的前 50000 个元素。
print(ls)
"""
输出:
[('BOS', 2), ('language', 2), ('processing', 2), ('.', 2), ('EOS', 2), ('I', 1), ('love', 1), ('natural', 1), ('Natural', 1), ('is', 1), ('fascinating', 1)]
"""
(4) 将含有多个元组的列表,转为字典。
如:word_dict ={元素1:索引,元素2,索引…}
enumerate(可迭代元素),返回的第一个值为索引,第二个值为元素。
ls = [('BOS', 2), ('language', 2), ('processing', 2), ('.', 2), ('EOS', 2), ('I', 1), ('love', 1), ('natural', 1), ('Natural', 1), ('is', 1), ('fascinating', 1)]
word_dict = {word [0]: index + 2 for index, word in enumerate(ls)}
# word是('BOS',2), word[0]='BOS' , word[1]=2
#index 是该元组的索引,也就是 0
"""另一种写法:
word_dict = {}
for index, word in enumerate(ls):
word_dict[ word[0] ] = index + 2
print(word_dict)
"""
print(word_dict) #存放元素及其索引号
"""
输出: {'BOS': 2, 'language': 3, 'processing': 4, '.': 5, 'EOS': 6, 'I': 7, 'love': 8, 'natural': 9, 'Natural': 10, 'is': 11, 'fascinating': 12}
"""
word_dict['UNK'] = 1
word_dict['PAD'] = 0
print(word_dict)
"""
输出:{'BOS': 2, 'language': 3, 'processing': 4, '.': 5, 'EOS': 6, 'I': 7, 'love': 8, 'natural': 9, 'Natural': 10, 'is': 11, 'fascinating': 12, 'UNK': 1, 'PAD': 0}
"""
(5) 将字典的元素和索引互换位置,用于预测输出时打印答案。
word_dict= {'BOS': 2, 'language': 3, 'processing': 4, '.': 5, 'EOS': 6, 'I': 7, 'love': 8, 'natural': 9, 'Natural': 10, 'is': 11, 'fascinating': 12, 'UNK': 1, 'PAD': 0}
index_dict = {v: k for k, v in word_dict.items()}
print(index_dict)
"""
输出:{2: 'BOS', 3: 'language', 4: 'processing', 5: '.', 6: 'EOS', 7: 'I', 8: 'love', 9: 'natural', 10: 'Natural', 11: 'is', 12: 'fascinating', 1: 'UNK', 0: 'PAD'}
"""
3. 将每句话每个单词在字典的索引合成列表,并按英文列表长度排序输出(从低到高)。
排序的作用:以便后续分batch做padding时,同批次各句子需要padding的长度相近减少padding量。
"""
输入:
en = [
['BOS', 'anyone', 'can', 'do', 'that', '.', 'EOS'],
['BOS', 'how', 'about', 'another', 'piece', 'of', 'cake', '?', 'EOS'],
['BOS', 'she', 'married', 'him', '.', 'EOS']
]
cn=[
['BOS', '任', '何', '人', '都', '可', '以', '做', '到', '。', 'EOS'],
['BOS', '要', '不', '要', '再', '來', '一', '塊', '蛋', '糕', '?', 'EOS'],
['BOS', '她', '嫁', '给', '了', '他', '。', 'EOS']
]
en_dict ={'BOS': 2, 'EOS': 3, '.': 4, 'anyone': 5, 'can': 6, 'do': 7, 'that': 8, 'how': 9, 'about': 10, 'another': 11, 'piece': 12, 'of': 13, 'cake': 14, '?': 15, 'she': 16, 'married': 17, 'him': 18, 'PAD': 0, 'UNK': 1}
cn_dict= {'BOS': 2, 'EOS': 3, '。': 4, '要': 5, '任': 6, '何': 7, '人': 8, '都': 9, '可': 10, '以': 11, '做': 12, '到': 13, '不': 14, '再': 15, '來': 16, '一': 17, '塊': 18, '蛋': 19, '糕': 20, '?': 21, '她': 22, '嫁': 23, '给': 24, '了': 25, '他': 26, 'PAD': 0, 'UNK': 1}
"""
def word2id(en, cn, en_dict, cn_dict, sort=True):
"""
将英文、中文单词列表转为单词索引列表
`sort=True`表示以英文语句长度排序,以便按批次填充时,同批次语句填充尽量少
"""
length = len(en) #计算长度
# 单词映射为索引
# 字典.get(word,UNK)获取字典中键 'word' 对应的值,如果键不存在,则返回一个指定的默认值 UNK
out_en_ids = [[en_dict.get(word, UNK) for word in sent] for sent in en]
# out_en_ids = [[2, 5, 6, 7, 8, 4, 3], [2, 9, 10, 11, 12, 13, 14, 15, 3], [2, 16, 17, 18, 4, 3]]
out_cn_ids = [[cn_dict.get(word, UNK) for word in sent] for sent in cn]
# out_cn_ids = [[2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3], [2, 5, 14, 5, 15, 16, 17, 18, 19, 20, 21, 3], [2, 22, 23, 24, 25, 26, 4, 3]]
# 按照语句长度排序
def len_argsort(seq):
"""
按照语句长度排序后,返回排序后原来各语句在数据中的索引下标
"""
return sorted(range(len(seq)), key=lambda x: len(seq[x]))
# 按相同顺序对中文、英文样本排序
if sort:
# 以英文语句长度排序,中文语句随着英语语句排序的改变而改变
sorted_index = len_argsort(out_en_ids) #sorted_index =[2, 0, 1]
out_en_ids = [out_en_ids[idx] for idx in sorted_index]
# out_en_ids = [[2, 16, 17, 18, 4, 3],[2, 5, 6, 7, 8, 4, 3], [2, 9, 10, 11, 12, 13, 14, 15, 3]]
out_cn_ids = [out_cn_ids[idx] for idx in sorted_index]
# out_cn_ids = [ [2, 22, 23, 24, 25, 26, 4, 3],[2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3], [2, 5, 14, 5, 15, 16, 17, 18, 19, 20, 21, 3]]
return out_en_ids, out_cn_ids
"""
输出:
out_en_ids= [[2, 16, 17, 18, 4, 3],[2, 5, 6, 7, 8, 4, 3], [2, 9, 10, 11, 12, 13, 14, 15, 3]]
out_cn_ids = [ [2, 22, 23, 24, 25, 26, 4, 3],[2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3], [2, 5, 14, 5, 15, 16, 17, 18, 19, 20, 21, 3]]
"""
程序解析
(1)将en句子中的各个单词在字典里的索引,组成一个索引列表。
from nltk import word_tokenize
PAD = 0 # padding占位符的索引
UNK = 1 # 未登录词标识符的索引
en = [
['BOS','I', 'love', 'natural', 'language', 'processing', '.', 'EOS'] ,
['BOS', 'Natural', 'language', 'processing', 'is', 'fascinating', '.', 'EOS']
]
en_dict= {'BOS': 2, 'language': 3, 'processing': 4, '.': 5, 'EOS': 6, 'I': 7, 'love': 8, 'natural': 9, 'Natural': 10, 'is': 11, 'fascinating': 12, 'UNK': 1, 'PAD': 0 }
# 字典.get(word,UNK)获取字典中键 'word' 对应的值,如果键不存在,则返回一个指定的默认值 UNK
out_en_ids = [[en_dict.get(word, UNK) for word in sent] for sent in en]
"""
另一种写法:
out_en_ids = []
for sent in en:
# 将句子中的每个单词转换为对应的单词ID
# 如果单词不在字典中,则使用UNK表示
word_ids = []
for word in sent:
word_id = en_dict.get(word, UNK)
word_ids.append(word_id)
out_en_ids.append(word_ids)
"""
print(out_en_ids)
"""
输出: [
[2, 7, 8, 9, 3, 4, 5, 6],
[2, 10, 3, 4, 11, 12, 5, 6]
]
2:en第一个句子的第一个单词'BOS'在en_dict字典的索引值为2.
7:en第一个句子的第二个单词'I'在en_dict字典的索引值为7.
8:en第一个句子的第三个单词'love'在en_dict字典的索引值为8.
......
"""
(2)将句子的索引列表按照句子长度进行排序–从短到长。
作用: 以便后续分batch做padding时,同批次各句子需要padding的长度相近减少padding量。
from nltk import word_tokenize
UNK=1
en = [
['BOS', 'I', 'love', 'natural', 'language', 'processing', '.', 'EOS'],
['BOS', 'This', 'is', 'a', 'test', 'sentence', '.', 'EOS','I','love'],
['BOS', 'test', '.', 'EOS']
]
en_dict = {'BOS': 2, 'language': 3, 'processing': 4, '.': 5, 'EOS': 6, 'I': 7, 'love': 8, 'natural': 9, 'This': 10, 'is': 11, 'a': 12, 'test': 13, 'sentence': 14, 'UNK': 1, 'PAD': 0}
def word2id(en, en_dict, sort=True):
length = len(en) # 计算长度
# 字典.get(word,UNK)获取字典中键 'word' 对应的值,如果键不存在,则返回一个指定的默认值 UNK
out_en_ids = [[en_dict.get(word, UNK) for word in sent] for sent in en]
"""
out_en_ids = [
[2, 7, 8, 9, 3, 4, 5, 6],
[2, 10, 3, 4, 11, 12, 5, 6]
]
"""
# 按照语句长度排序
def len_argsort(seq):
return sorted(range(len(seq)), key=lambda x: len(seq[x])) #使用详情查看-深度学习理论基础(一)的内容。
if sort:
sorted_index = len_argsort(out_en_ids) #获得按句子长度排序后的索引号,如sorted_index =[2, 0, 1]
out_en_ids = [out_en_ids[idx] for idx in sorted_index] #按照排序后的索引列表的索引,将索引列表排序。
return out_en_ids
print(word2id(en,en_dict))
"""
sort=False 索引列表按en句子的顺序排列
out_en_ids= [[2, 7, 8, 9, 3, 4, 5, 6], [2, 10, 11, 12, 13, 14, 5, 6, 7, 8], [2, 13, 5, 6] ]
sort=True 索引列表按en句子的长度排列,从短到长排列
out_en_ids= [[2, 13, 5, 6], [2, 7, 8, 9, 3, 4, 5, 6], [2, 10, 11, 12, 13, 14, 5, 6, 7, 8] ]
"""
4. 将数据索引数据按照batch进行划分,并创建掩码。
模型输入是文本序列,而这些文本序列的长度是不一样的。为了将它们组成一个批次(batch)并输入到模型中,你需要确保它们的长度相同。但是,为了达到相同的长度,你可能需要在较短的序列后面填充一些特殊的标记,如使用0进行标记。
作用:将输入划分batch,将每个batch里的数据按照batch里最长数据长度进行补0填充,即使得每个batch里的数据长度一致。
将batch数据转换为tenser格式,用于模型的输入。将填充好的再创建掩码。
"""假设输入,经过3排序后的输出,为4的输入。
out_en_ids= [[2, 16, 17, 18, 4, 3],[2, 5, 6, 7, 8, 4, 3], [2, 9, 10, 11, 12, 13, 14, 15, 3]]
out_cn_ids = [ [2, 22, 23, 24, 25, 26, 4, 3],[2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3], [2, 5, 14, 5, 15, 16, 17, 18, 19, 20, 21, 3]]
batch_size=2
shuffle=True ,是否随机打乱顺序
"""
def split_batch(en_ids, cn_ids, batch_size, shuffle=True):
"""
划分批次
`shuffle=True`表示对各批次顺序随机打乱
"""
# 每隔batch_size取一个索引作为后续batch的起始索引
idx_list = np.arange(0, len(en_ids), batch_size) #idx_list = [0,2]
# 起始索引随机打乱
if shuffle:
np.random.shuffle(idx_list) #idx_list = [2,0] 随机打乱顺序
# 存放所有批次的语句索引
batch_indexs = []
for idx in idx_list: #idx_list = [2, 0]
# 起始索引最大的批次可能发生越界,要限定其索引
batch_indexs.append(np.arange( idx, min(idx + batch_size, len(en_ids)) ))
#batch_indexs=[array([2]), array([0, 1])]
# 构建批次列表
batches = []
for batch_index in batch_indexs:
# 按当前批次的样本索引采样
batch_en = [en_ids[index] for index in batch_index]
#第一轮batch_en =[[2, 9, 10, 11, 12, 13, 14, 15, 3]] ,第二轮batch_en =[[2, 16, 17, 18, 4, 3], [2, 5, 6, 7, 8, 4, 3]]
batch_cn = [cn_ids[index] for index in batch_index]
#第一轮batch_en =[[2, 5, 14, 5, 15, 16, 17, 18, 19, 20, 21, 3]] ,第二轮batch_en =[[2, 22, 23, 24, 25, 26, 4, 3], [2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3]]
# 对当前批次中所有语句填充、对齐长度
# 维度为:batch_size * 当前批次中语句的最大长度
batch_cn = seq_padding(batch_cn)
# 第一批次batch_cn =[[2, 5, 14, 5, 15, 16, 17, 18, 19, 20, 21, 3]] ,第二批次batch_en =[[2, 22, 23, 24, 25, 26, 4, 3, 0, 0, 0], [2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3]]
batch_en = seq_padding(batch_en)
#第一批次batch_en =[[2, 9, 10, 11, 12, 13, 14, 15, 3]] ,第二批次batch_en =[[2, 16, 17, 18, 4, 3 ,0], [2, 5, 6, 7, 8, 4, 3]]
# 将当前批次添加到批次列表
# Batch类用于实现注意力掩码
batche= Batch(batch_en, batch_cn) #实例化Batch类
batches.append(batche) #添加到列表中
"""另一种写法:batches.append(Batch(batch_en, batch_cn)) """
return batches
"""
查看 batches里的内容:
for batch in batches:
print("Input Sequence (src):", batch.src)
print("Target Sequence (trg):", batch.trg)
print("Source Mask:", batch.src_mask)
print("Target Mask:", batch.trg_mask)
print("Target Label:", batch.trg_y)
print("Number of Tokens in Target:", batch.ntokens)
查看第一批次输出:
Input Sequence (src): tensor([[ 2, 9, 10, 11, 12, 13, 14, 15, 3]])
Target Sequence (trg): tensor([[ 2, 5, 14, 5, 15, 16, 17, 18, 19, 20, 21]])
Source Mask: tensor([[[True, True, True, True, True, True, True, True, True]]])
Target Mask: tensor([[[ True, False, False, False, False, False, False, False, False, False,
False],
[ True, True, False, False, False, False, False, False, False, False,
False],
[ True, True, True, False, False, False, False, False, False, False,
False],
[ True, True, True, True, False, False, False, False, False, False,
False],
[ True, True, True, True, True, False, False, False, False, False,
False],
[ True, True, True, True, True, True, False, False, False, False,
False],
[ True, True, True, True, True, True, True, False, False, False,
False],
[ True, True, True, True, True, True, True, True, False, False,
False],
[ True, True, True, True, True, True, True, True, True, False,
False],
[ True, True, True, True, True, True, True, True, True, True,
False],
[ True, True, True, True, True, True, True, True, True, True,
True]]])
Target Label: tensor([[ 5, 14, 5, 15, 16, 17, 18, 19, 20, 21, 3]])
Number of Tokens in Target: tensor(11)
"""
关联代码
(1)seq_padding() 函数:获取所有索引列表的最大长度,如果其余列表小于该长度则填充0。
"""
输入:
X = [[2, 8, 5, 6], [2, 9, 3, 4, 11, 12, 5, 6], [2, 10, 12, 5, 6]]
"""
PAD=0 #填充元素
def seq_padding(X, padding=PAD):
"""
按批次(batch)对数据填充、长度对齐
"""
# 计算该批次各条样本语句长度
Length = [len(x) for x in X]
# 获取该批次样本中语句长度最大值
MaxLength= max(Length )
# 遍历该批次样本,如果语句长度小于最大长度,则用padding填充
return np.array([
np.concatenate([x, [padding] * (MaxLength - len(x))]) if len(x) < MaxLength else x for x in X
])
"""---------------------写法二: """
def seq_padding(sentences, padding=PAD):
"""
按批次(batch)对数据填充、长度对齐
"""
# 计算该批次各条样本语句长度
Length = [len(x) for x in X]
# 获取该批次样本中语句长度最大值
MaxLength = max(Length)
# 遍历该批次样本,如果语句长度小于最大长度,则用padding填充
padded_X = []
for x in X:
if len(x) < MaxLength:
padded_seq = np.concatenate([x, [padding] * (ML - len(x))])
else:
padded_seq = x
padded_X.append(padded_seq)
return np.array(padded_X)
print(seq_padding(X))
"""
输出:
[[ 2 8 5 6 0 0 0 0], [ 2 9 3 4 11 12 5 6], [ 2 10 12 5 6 0 0 0]]
"""
(2)Batch类
该类含有四个成员:
self.src :需要输入,经过填充后的batch_en(英文单词在字典的索引)
self.src_mask:生成batch_en的掩码
self.trg:需要输入,经过填充后的batch_cn(中文单词在字典的索引)
self.trg_mask:生成batch_cn的掩码
"""
输入:
batch_en =[[2, 16, 17, 18, 4, 3 ,0], [2, 5, 6, 7, 8, 4, 3]]
batch_cn =[[2, 22, 23, 24, 25, 26, 4, 3, 0, 0, 0], [2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3]]
Batch(batch_en ,batch_cn)
"""
PAD=0
class Batch:
"""
批次类
1. 输入序列(源)
2. 输出序列(目标)
3. 构造掩码
"""
def __init__(self, src, trg=None, pad=PAD):
# 将src、trg转为tensor格式,将数据放到设备上并规范成整数类型
src = torch.from_numpy(src).to(DEVICE).long()
#src =tensor([[ 2, 16, 17, 18, 4, 3, 0],[ 2, 5, 6, 7, 8, 4, 3]])
trg = torch.from_numpy(trg).to(DEVICE).long()
#trg =tensor([[ 2, 22, 23, 24, 25, 26, 4, 3, 0, 0, 0], [ 2, 6, 7, 8, 9, 10, 11, 12, 13, 4, 3]])
self.src = src
# self.src= tensor([[ 2, 16, 17, 18, 4, 3, 0],[ 2, 5, 6, 7, 8, 4, 3]])
# (src != pad):这部分代码会生成一个与输入序列 src 形状相同的布尔张量,其中真实单词的位置为 True,填充部分的位置为 False。并在seq length前面增加一维,形成维度为 1×seq length 的矩阵
self.src_mask = (src != pad).unsqueeze(-2)
"""self.src_mask=tensor([[[ True, True, True, True, True, True, False]],
[[ True, True, True, True, True, True, True]]])"""
# self.src_mask.shape= torch.Size([2, 1, 7])
# 如果输出目标不为空,则需要对解码器使用的目标语句进行掩码
if trg is not None:
# 解码器使用的目标输入部分
self.trg = trg[:, : -1] # 去除最后一列
# self.trg=tensor([[ 2, 22, 23, 24, 25, 26, 4, 3, 0, 0],[ 2, 6, 7, 8, 9, 10, 11, 12, 13, 4]])
# 解码器训练时应预测输出的目标结果
self.trg_y = trg[:, 1:] #去除第一列的
#self.trg_y=tensor([[22, 23, 24, 25, 26, 4, 3, 0, 0, 0],[ 6, 7, 8, 9, 10, 11, 12, 13, 4, 3]])
# 将目标输入部分进行注意力掩码
self.trg_mask = self.make_std_mask(self.trg, pad)
#生成一个大小为self.trg.size(-1)的掩码矩阵,下三角为True,上三角为False
"""
self.trg_mask=
tensor([[[ True, False, False, False, False, False, False, False, False, False],
[ True, True, False, False, False, False, False, False, False, False],
[ True, True, True, False, False, False, False, False, False, False],
[ True, True, True, True, False, False, False, False, False, False],
[ True, True, True, True, True, False, False, False, False, False],
[ True, True, True, True, True, True, False, False, False, False],
[ True, True, True, True, True, True, True, False, False, False],
[ True, True, True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, True, True, False, False]],
[[ True, False, False, False, False, False, False, False, False, False],
[ True, True, False, False, False, False, False, False, False, False],
[ True, True, True, False, False, False, False, False, False, False],
[ True, True, True, True, False, False, False, False, False, False],
[ True, True, True, True, True, False, False, False, False, False],
[ True, True, True, True, True, True, False, False, False, False],
[ True, True, True, True, True, True, True, False, False, False],
[ True, True, True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, True, True, True, False],
[ True, True, True, True, True, True, True, True, True, True]]])
"""
# 将应输出的目标结果中真实的词数进行统计
self.ntokens = (self.trg_y != pad).data.sum()
#self.ntokens=tensor(17)
# 掩码操作
#这个操作的目的是在训练解码器时,确保解码器在预测当前时间步的词时只能依赖之前的词,而不能依赖未来的词
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
#这部分代码会生成一个与目标序列 tgt 形状相同的布尔张量,其中真实单词的位置为 True,填充部分的位置为 False。并在倒数第二维度上添加一个新维度。
#tgt_mask =tensor([[[True, True, True, True, True, True, True, True, True, True, True]]])
tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
#subsequent_mask(tgt.size(-1)):生成一个大小为tgt.size(-1)的下三角形的矩阵,上三角部分为0,下三角部分和对角线为1。
#Variable(...).type_as(tgt_mask.data):将生成的下三角形矩阵转换为与目标序列掩码相同的数据类型和设备类型。
#(tgt_mask & ...): 对上面生成的下三角形矩阵与目标序列掩码进行逻辑与操作,得到最终的目标序列掩码。
return tgt_mask
(3)subsequent_mask( ) 函数:生成上三角(不含对角线)为1,下三角为0的掩码矩阵。
def subsequent_mask(size):
attn_shape = (1, size, size)
#attn_shape =(1, 11, 11)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
#np.ones(attn_shape) 会生成一个形状为 attn_shape 的全为1的矩阵。
#np.triu() 函数将这个矩阵转换为上三角矩阵。
#参数 k 控制了主对角线以上的偏移量。当 k=0 时,生成的是包含主对角线在内的上三角矩阵;当 k=1 时,生成的是主对角线以上偏移一个单位的上三角矩阵。
# 返回一个右上角(不含主对角线)为全False,左下角(含主对角线)为全True的subsequent_mask矩阵
return torch.from_numpy(subsequent_mask) == 0
#torch.from_numpy(subsequent_mask) 将 NumPy 数组 subsequent_mask 转换为 PyTorch 张量。
#然后,== 0 表示对张量中的每个元素进行逐元素比较,检查是否等于0。最终返回的是一个布尔类型的张量,其中每个元素都是与0比较的结果,即True或False。即等于0为True,等于1为False。
if __name__ == '__main__':
print(subsequent_mask(4))
"""
输出:
tensor([[[ True, False, False, False],
[ True, True, False, False],
[ True, True, True, False],
[ True, True, True, True]]])
"""
三、模型搭建
"""
解码器输出经线性变换和softmax函数映射为下一时刻预测单词的概率分布。常用于翻译模型中!
这个类的代码不是必须的。要结合实际项目定义。如果不需要则在下面Transformer类中去掉generator参数即可。
"""
class Generator(nn.Module):
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
# decode后的结果,先进入一个全连接层变为词典大小的向量
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
# 然后再进行log_softmax操作(在softmax结果上再做多一次log运算)
return F.log_softmax(self.proj(x), dim=-1)
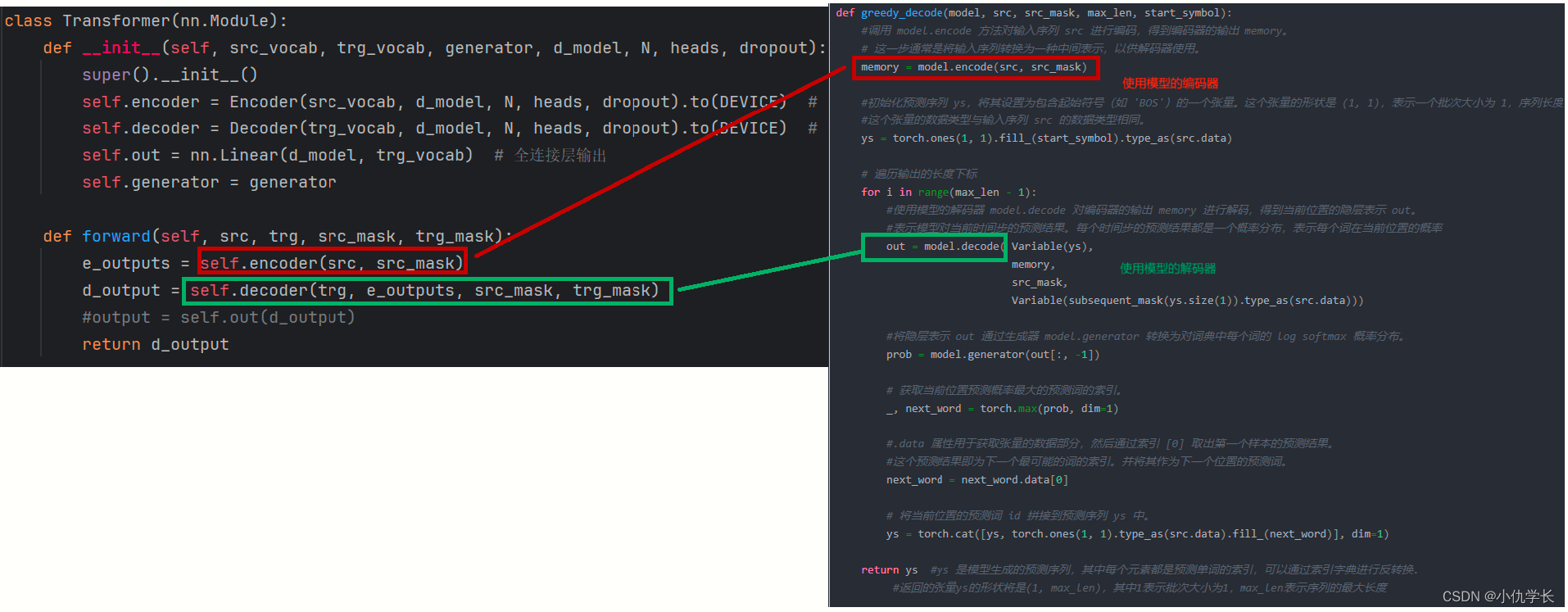
class Transformer(nn.Module):
def __init__(self, src_vocab, trg_vocab, generator, d_model, N, heads, dropout):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout).to(DEVICE) # 编码器总体
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout).to(DEVICE) # 解码器总体
self.out = nn.Linear(d_model, trg_vocab) #根据项目需要定义
self.generator = generator #根据项目需要定义
def forward(self, src, trg, src_mask, trg_mask):
e_outputs = self.encoder(src, src_mask)
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)
#output = self.out(d_output) #根据实际项目的形状进行输出
return d_output
if __name__ == '__main__':
src_vocab = len(data.en_word_dict)
tgt_vocab = len(data.cn_word_dict)
DEVICE ='cpu' #如果使用gpu,则直接修改为cuda即可。
generator = Generator(d_model=512, tgt_vocab).to(DEVICE)
model = Transformer(src_vocab, tgt_vocab, generator, d_model=512, N=6, heads=8, dropout=0.1).to(DEVICE) #定义模型。
四、设置训练参数
1. 优化器类–设置学习率,更新内部参数
class NoamOpt:
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer #实际的优化器
self._step = 0 #步长
self.warmup = warmup #预热步数
self.factor = factor #学习率的比例因子
self.model_size = model_size #模型的大小(通常是 Transformer 模型的隐藏层大小)
self._rate = 0 #学习率
def rate(self, step=None): #计算当前步数对应的学习率。
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * (self.model_size ** (-0.5) * min(step ** (-0.5), step * self.warmup ** (-1.5))) #计算学习率
def step(self):
"Update parameters and rate"
self._step += 1 #学习步长加1
rate = self.rate() #计算当前步数对应的学习率。
self._rate = rate #记录当前学习率
for p in self.optimizer.param_groups:
p['lr'] = rate #将计算出学习率设置为优化器中的学习率。
self.optimizer.step() #优化内部参数
'''定义优化器'''
D_MODEL = 256 # 输入、输出词向量维数
optimizer = NoamOpt(D_MODEL, 1, 2000, torch.optim.Adam(model.parameters(), lr=0, betas=(0.9,0.98), eps=1e-9) )
2. 将预测数据进行平滑操作。前向传播时与真实标签计算损失率并返回损失。
标签平滑是一种用于改善神经网络训练效果的技术。它的基本思想是在训练过程中,将真实的标签分布向均匀分布进行平滑,从而减少模型过度自信的倾向,使模型更加健壮和泛化能力更强。
标签平滑是一种常用的正则化技术,用于改善神经网络的训练效果和泛化能力。提高了模型在面对新的、未见过的数据时的预测能力。
作用:减少过拟合:标签平滑可以减少模型对训练数据的过度拟合,使得模型更加泛化。提高模型鲁棒性:通过减小标签的置信度,标签平滑可以使得模型对于噪声和错误的标签更具鲁棒性。
class LabelSmoothing(nn.Module):
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
#计算 KL 散度损失(Kullback-Leibler Divergence Loss)的类。KL 散度损失通常用于度量两个概率分布之间的差异。
#这里的 'sum' 表示对损失值进行求和,即将每个样本的损失值相加得到最终的损失值。
self.criterion = nn.KLDivLoss(reduction='sum') #定义损失函数
self.padding_idx = padding_idx #填充标签的标记,即使用哪个符号进行的填充,则使用哪个符号。如在上面操作中我们使用0进行填充,则这里填0。
self.confidence = 1.0 - smoothing #计算标签平滑(Label Smoothing)中的置信度参数。
self.smoothing = smoothing #平滑因子,控制标签平滑的程度。
self.size = size #输入长度。
self.true_dist = None #存储经过平滑处理后的目标概率分布。初始时将其设置为 None
def forward(self, x, target):
assert x.size(1) == self.size #如果assert 后的内容为true,则正常运行后面的代码,否则直接返回错误。
true_dist = x.data.clone()#.data属性用于获取 x 的数据部分, .clone() 方法用于创建该数据的副本。这样做的目的是在处理 x 的数据时不会影响到原始张量 x。
#填充 true_dist 张量的所有元素,使用平滑参数 self.smoothing 除以 self.size - 2 的值。
#填充操作的目的是为了对目标类别的概率分布进行平滑处理,以减少过拟合的可能性。
true_dist.fill_(self.smoothing / (self.size - 2))
#如果有一个张量 tensor,我们可以使用 scatter_(dim, index, value) 方法根据 index 中的索引,在指定的维度 dim 上将值 value 散布到 tensor 中。
#target.data.unsqueeze(1) 创建了一个新的维度,将目标张量 target 的形状从 (batch_size,) 变为 (batch_size, 1)。
#将目标类别的概率设置为较高的值,以便在训练过程中增加模型的鲁棒性。
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0 #将true_dist的位置上设置为0
"""
target.data == self.padding_idx 会生成一个布尔张量,其中 True 表示 target 张量中对应位置的元素等于 self.padding_idx,而 False 表示不等于。
然后,torch.nonzero() 函数会返回所有为 True 的元素的索引,这些索引表示了 target 张量中值为 self.padding_idx 的元素的位置。
"""
mask = torch.nonzero(target.data == self.padding_idx)#torch.nonzero()函数用于返回非零元素的索引。
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False)) #返回预测值和目标值的损失。
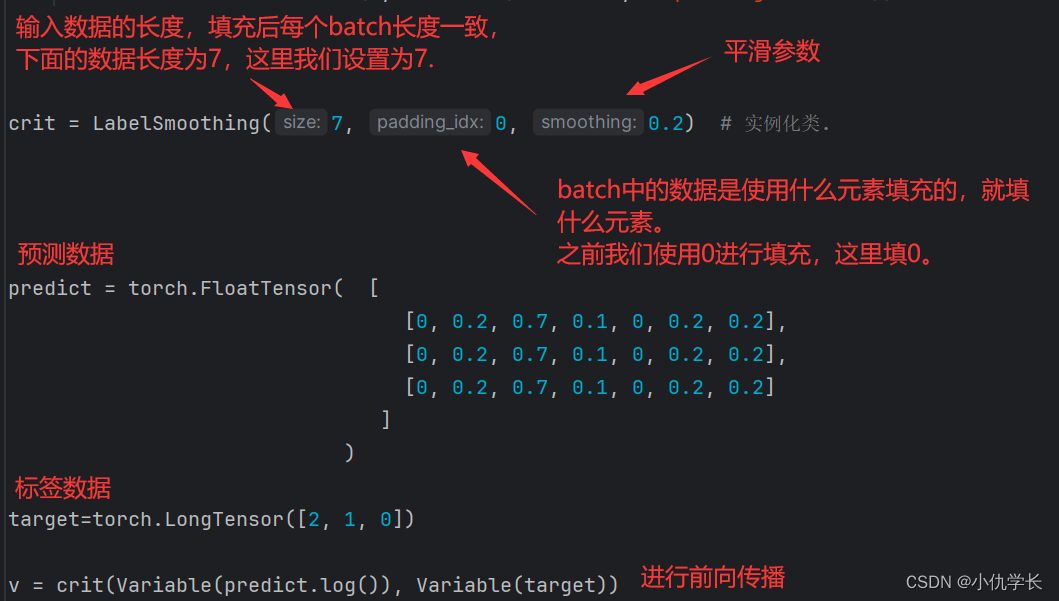
if __name__ == '__main__':
# Label smoothing的例子
crit = LabelSmoothing(5, 0, 0.4) # 实例化类。设定一个ϵ=0.4
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]])
loss = crit(Variable(predict.log()), Variable(torch.LongTensor([2, 1, 0])))
#predict.log():对predict张量中的每个元素取对数。
# Show the target distributions expected by the system.
print(crit.true_dist) #平滑的预测数据
print(loss) #损失
"""
输出:
tensor([[0.0000, 0.1333, 0.6000, 0.1333, 0.1333],
[0.0000, 0.6000, 0.1333, 0.1333, 0.1333],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]])
"""
3. 梯度反向传播,并计算新的损失值。
class SimpleLossCompute: #简单的计算损失和进行参数反向传播更新训练的函数
def __init__(self, generator, criterion, opt=None):
""" model.generator 是一个模型的一部分,通常用于将解码器的输出转换为词汇表中每个词的概率分布。
在生成序列时,解码器的输出是对每个时间步的预测结果,这些预测结果通常是一个包含每个词在当前位置的概率分布。
然后,通过model.generator,这些概率分布被转换成对应词汇表中每个词的 log softmax 概率分布。"""
self.generator = generator
self.criterion = criterion #标签平滑、损失函数类
self.opt = opt #优化器类
def __call__(self, x, y, norm):
x = self.generator(x)
loss = self.criterion( x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1) ) / norm #计算损失函数。
loss.backward()
if self.opt is not None:
self.opt.step() #调用定义优化器类里的step方法,更新内部参数。
self.opt.optimizer.zero_grad() #清理上一轮滞留的梯度
return loss.data.item() * norm.float() #计算损失值乘以归一化因子的结果,得到一个新的数值。
if __name__ == '__main__':
TRAIN_FILE = 'nmt/en-cn/train.txt' # 训练集
DEV_FILE = "nmt/en-cn/dev.txt" # 验证集
D_MODEL = 256 # 输入、输出词向量维数
data = PrepareData(TRAIN_FILE, DEV_FILE)
tgt_vocab = len(data.cn_word_dict)
criterion = LabelSmoothing(tgt_vocab, padding_idx = 0, smoothing= 0.0) #标签平滑,返回损失值
optimizer = NoamOpt(D_MODEL, 1, 2000, torch.optim.Adam(model.parameters(), lr=0, betas=(0.9,0.98), eps=1e-9)) #定义优化器
loss=SimpleLossCompute(model.generator, criterion, optimizer)
五、训练网络
"""返回所有训练数据的平均损失"""
def run_epoch(data, model, loss_compute, epoch):
start = time.time() #记录当前时间
total_tokens = 0.
total_loss = 0.
tokens = 0.
for i, batch in enumerate(data): #获得batch块及其索引
out = model(batch.src, batch.trg, batch.src_mask, batch.trg_mask) #计算预测值
loss = loss_compute(out, batch.trg_y, batch.ntokens) #当前batch的损失。
total_loss += loss #计算所有batch的总体损失。
total_tokens += batch.ntokens #batch.ntokens:每个batch里有多少个组数据。这里记录所有batch里样本的总数。
tokens += batch.ntokens #这里记录50个(下面i%50)batch里样本的数量。
if i % 50 == 1:
elapsed = time.time() - start #计算出50个batch训练的时间
print("Epoch %d Batch: %d Loss: %f Tokens per Sec: %fs" % (epoch, i - 1, loss / batch.ntokens, (tokens.float() / elapsed / 1000.)))
start = time.time() #更新当前时间
tokens = 0 #将50个batch的样本数清零。
return total_loss / total_tokens #返回平均损失。
def train(data, model, criterion, optimizer):
"""
训练并保存模型
"""
# 初始化模型在dev集上的最优Loss为一个较大值
best_dev_loss = 1e5
for epoch in range(EPOCHS):
"""module.train()是PyTorch中用于将神经网络模型设置为训练模式的方法。
当调用此方法时,模型内部的一些层(例如Dropout层和BatchNormalization层)将启用训练时特定的行为,例如启用随机失活(Dropout)和批量归一化(Batch Normalization)。
在训练神经网络时,通常会在每个训练迭代中使用module.train()来确保模型处于训练模式。
这样可以保证在前向传播和反向传播过程中,模型的行为是符合预期的,并且所有需要更新的参数都会被更新。
在模型训练完成后,如果要对模型进行评估或者使用模型进行推断(inference),
通常会使用module.eval()将模型设置为评估模式,这会关闭一些特定于训练的行为,例如关闭随机失活。"""
model.train() #module.train()用于启用模型的训练模式
run_epoch(data.train_data, model, SimpleLossCompute(model.generator, criterion, optimizer), epoch)
# 在dev集上进行loss评估
print('>>>>> Evaluate')
model.eval()
dev_loss = run_epoch(data.dev_data, model, SimpleLossCompute(model.generator, criterion, None), epoch)
print('<<<<< Evaluate loss: %f' % dev_loss)
# 如果当前epoch的模型在dev集上的loss优于之前记录的最优loss则保存当前模型,并更新最优loss值
if dev_loss < best_dev_loss:
torch.save(model.state_dict(), SAVE_FILE)
best_dev_loss = dev_loss
print('****** Save model done... ******')
print()
if __name__ == '__main__':
TRAIN_FILE = 'nmt/en-cn/train.txt' # 训练集
DEV_FILE = "nmt/en-cn/dev.txt" # 验证集
SAVE_FILE = 'save/model.pt' # 模型保存路径
D_MODEL = 256 # 输入、输出词向量维数
PAD = 0 # padding占位符的索引
UNK = 1 # 未登录词标识符的索引
EPOCHS = 20 # 训练轮数
data = PrepareData(TRAIN_FILE, DEV_FILE)
tgt_vocab = len(data.cn_word_dict)
print(">>>>>>> start train")
train_start = time.time() #记录开始时的当前时间
criterion = LabelSmoothing(tgt_vocab, padding_idx = 0, smoothing= 0.0) #定义平滑预测数据,返回loss。
optimizer = NoamOpt(D_MODEL, 1, 2000, torch.optim.Adam(model.parameters(), lr=0, betas=(0.9,0.98), eps=1e-9)) #定义优化器
train(data, model, criterion, optimizer)
print(f"<<<<<<< finished train, cost {time.time()-train_start:.4f} seconds")#打印训练耗时
六、使用模型编码器、解码器翻译
作用:用在于生成目标序列,例如翻译任务中将源语言句子翻译成目标语言句子。
工作原理:在每个时间步上,选择具有最高预测概率的词作为下一个预测词。这意味着在每个时间步上,模型只考虑当前时刻的最佳预测,而不考虑后续时刻的预测。这种策略具有计算效率高、实现简单等优点,因此被广泛应用于序列生成任务中。
"""功能:输入英文的索引列表,预测出对应的中文的索引列表。然后通过中文字典,将预测的中文索引列表根据索引号转为对应的中文。"""
def greedy_decode(model, src, src_mask, max_len, start_symbol):
#调用 model.encode 方法对输入序列 src 进行编码,得到编码器的输出 memory。
# 这一步通常是将输入序列转换为一种中间表示,以供解码器使用。
memory = model.encode(src, src_mask)
#初始化预测序列 ys,将其设置为包含起始符号(如 'BOS')的一个张量。这个张量的形状是 (1, 1),表示一个批次大小为 1,序列长度为 1 的张量。
#这个张量的数据类型与输入序列 src 的数据类型相同。
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
# 遍历输出的长度下标
for i in range(max_len - 1):
#使用模型的解码器 model.decode 对编码器的输出 memory 进行解码,得到当前位置的隐层表示 out。
#表示模型对当前时间步的预测结果。每个时间步的预测结果都是一个概率分布,表示每个词在当前位置的概率
out = model.decode( Variable(ys),
memory,
src_mask,
Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
#将隐层表示 out 通过模型的生成器 model.generator 转换为对词典中每个词的 log softmax 概率分布。
prob = model.generator(out[:, -1])
# 获取当前位置预测概率最大的预测词的索引。
_, next_word = torch.max(prob, dim=1)
#.data 属性用于获取张量的数据部分,然后通过索引 [0] 取出第一个样本的预测结果。
#这个预测结果即为下一个最可能的词的索引。并将其作为下一个位置的预测词。
next_word = next_word.data[0]
# 将当前位置的预测词 id 拼接到预测序列 ys 中。
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys #ys 是模型生成的预测序列,其中每个元素都是预测单词的索引,可以通过索引字典进行反转换.
#返回的张量ys的形状将是(1, max_len),其中1表示批次大小为1,max_len表示序列的最大长度
if __name__ == '__main__':
TRAIN_FILE = 'nmt/en-cn/train.txt' # 训练集
DEV_FILE = "nmt/en-cn/dev.txt" # 验证集
data = PrepareData(TRAIN_FILE, DEV_FILE)
max_len= 60 # 语句最大长度
#注意:这里的src必须是英文的列表,因为我们要用英文翻译中文!!
src = torch.from_numpy(np.array(data.dev_en[0])).long().to(DEVICE) #data.dev_en[0] 假设为[2, 1227, 1120, 4, 3]
src_mask = (src != 0).unsqueeze(-2) # (src != 0) 将生成一个布尔张量,其形状与 src 张量相同,其中非零位置为 True,零填充位置为 False。且在倒数第二个维度上添加一个维度。
start_symbol= data.cn_word_dict["BOS"] # start_symbol =2
predict_list= greedy_decode(model, src, src_mask, max_len, start_symbol)
print(predict_list)
"""
predict_list = tensor([[ 2, 261, 30, 4, 3, 256, 4, 3, 4, 3, 4, 3, 4, 3,
4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 3, 4,
3, 3, 4, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 4,
3, 4, 3, 4]])
应为max_len=60,所以生成的predict_list长度为60。
中文字典:cn_dict= {'BOS': 2, 'EOS': 3, '。': 4, '要': 5, '任': 6, '何': 7, '人': 8, '都': 9, '可': 10, '以': 11, '做': 12, '到': 13, '不': 14, '再': 15, '來': 16, '一': 17, '塊': 18, '蛋': 19, '糕': 20, '?': 21, '她': 22, '嫁': 23, '给': 24, '了': 25, '他': 26, 'PAD': 0, 'UNK': 1}
我们可以将预测的中文索引号在字典中进行替换为对应的中文,当替换的中文为'EOS'时结束。这样我们就顺利替换。
"""
七、测试网络
# data.en_index_dict: {2: 'BOS', 3: 'EOS', 4: '.', 5: 'i', 6: 'the', 7: 'you', 8: 'to', 9: 'a', 10: '?',。....}
# data.cn_index_dict: {2: 'BOS', 3: 'EOS', 4: '。', 5: '我', 6: '的', 7: '了', 8: '你', 9: '他', 10: '一', 11: '不'
# data.dev_en: [[2, 5, 41, 1, 4, 3], [2, 5, 1, 1, 4, 3], [2, 5, 37, 1, 4, 3], [2, 19, 100, 105, 4, 3]
# data.dev_cn: [[2, 5, 1273, 7, 4, 3], [2, 5, 93, 7, 924, 34, 1, 4, 3], [2, 5, 61, 153, 694, 479, 4, 3], [2, 15, 47, 51, 48, 4, 3]
MAX_LENGTH = 60 # 语句最大长度
def evaluate(data, model):
"""
在data上用训练好的模型进行预测,打印模型翻译结果
"""
# 梯度清零
with torch.no_grad(): #不返回梯度
# 在data的英文数据长度上遍历下标
for i in range(len(data.dev_en)):
# 打印待翻译的英文语句
en_sent = " ".join([data.en_index_dict[w] for w in data.dev_en[i]])
print("\n" + en_sent)
# 打印对应的中文语句答案
cn_sent = " ".join([data.cn_index_dict[w] for w in data.dev_cn[i]])
print("".join(cn_sent))
# src为dev_en的一句话。将当前以单词索引表示的英文语句数据转为tensor,并放如DEVICE中
src = torch.from_numpy(np.array(data.dev_en[i])).long().to(DEVICE) #编码一句话
# 在最前面增加一维
src = src.unsqueeze(0)
# 设置attention mask
#(src != 0) 将生成一个布尔张量,其形状与 src 张量相同,其中非零位置为 True,零填充位置为 False。
#且在倒数第二个维度上添加一个维度。
src_mask = (src != 0).unsqueeze(-2)
# 用训练好的模型进行decode预测,out为预测单词的索引序列。
out = greedy_decode(model, src, src_mask, max_len=MAX_LENGTH, start_symbol=data.cn_word_dict["BOS"])
# 初始化一个用于存放模型翻译结果语句单词的列表
translation = []
# 遍历翻译输出字符的下标(注意:开始符"BOS"的索引0不遍历)
for j in range(1, out.size(1)): #out的形状为(1, max_len),out.size(1)也就是out序列的长度。
# 获取当前下标的输出字符
sym = data.cn_index_dict[out[0, j].item()] #out是1行out.size(1)列的元素。out[0, j].item() 获取解码输出张量中第 j 列的元素,即预测单词的索引。并使用 data.cn_index_dict 将其转换为对应的中文字符。
# 如果输出字符不为'EOS'终止符,则添加到当前语句的翻译结果列表
if sym != 'EOS':
translation.append(sym)
# 否则终止遍历
else:
break
# 打印模型翻译输出的中文语句结果
print("translation: %s" % " ".join(translation))
if __name__ == '__main__':
# 预测
# 加载模型
SAVE_FILE = 'save/model.pt' # 之前训练号的模型以及保存到该路径
model.load_state_dict(torch.load(SAVE_FILE)) #加载该路径下的模型
# 开始预测
print(">>>>>>> start evaluate")
evaluate_start = time.time()
evaluate(data, model)
八、预测效果
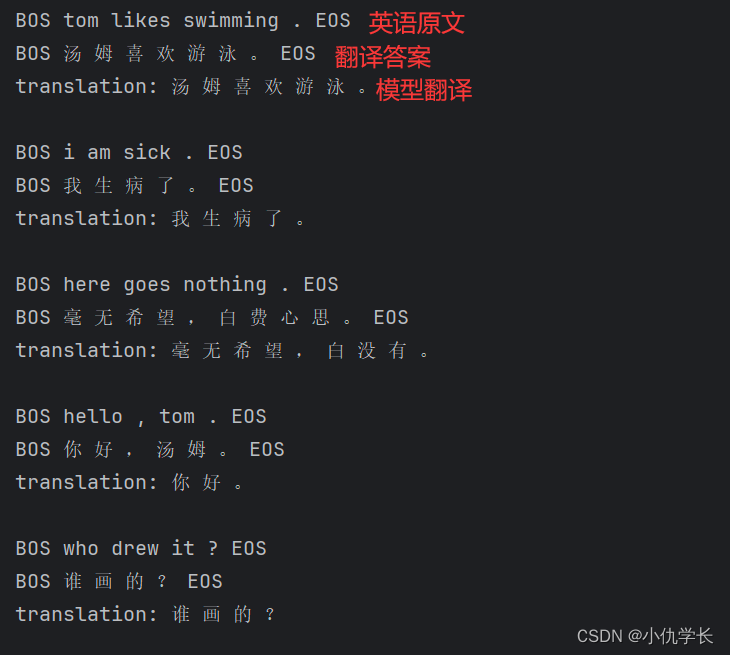
我们可以看到翻译效果还是不错的,虽然也有翻译出错的地方。总体效果较好!本文到此结束,有任何问题可以咨询。
















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









