







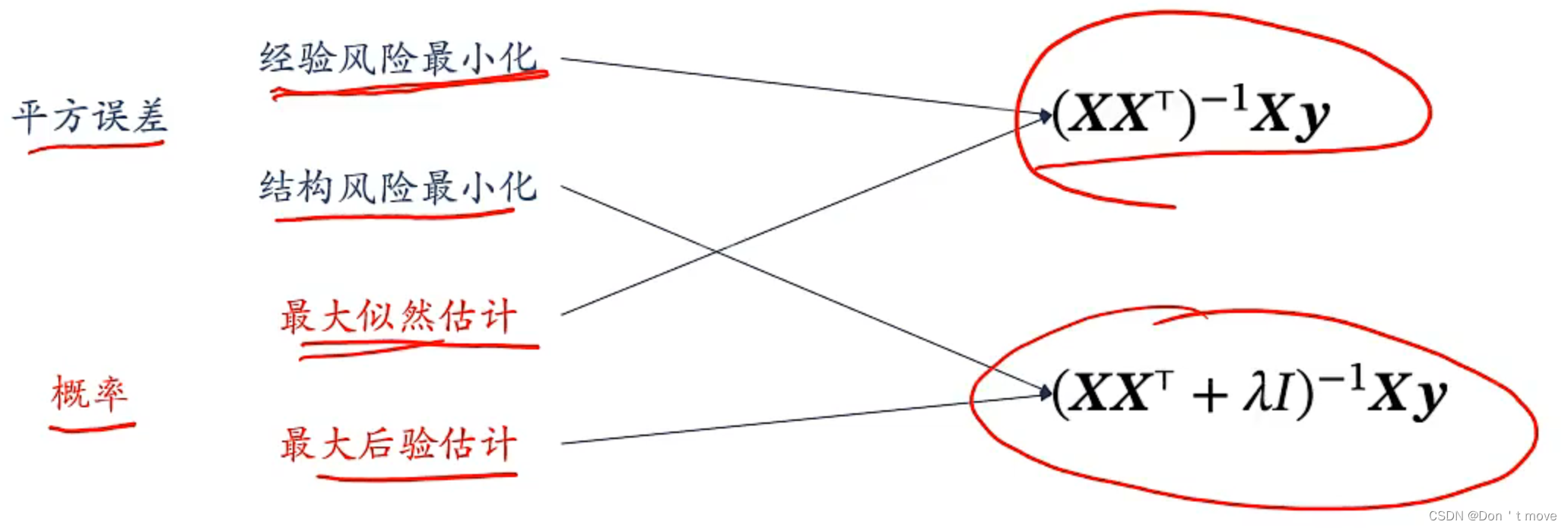
从概率角度来看线性回归
从机器学习的角度看,线性回归需要通过一个函数建模
x
,
y
x,y
x,y之间的关系;而从概率的角度看,则是要表示出在给定
x
x
x下随机变量
y
y
y的条件概率。
但通常
y
y
y是一个定值,为了计算
y
y
y在给定
x
x
x下的条件概率
p
(
y
∣
x
)
p(y|x)
p(y∣x),首先要将
y
y
y看作一个随机变量。可以先用一个函数表示出一个连续函数,在对该函数进行采样时添加一个服从均值为0方差为
σ
2
\sigma^2
σ2的噪声
ϵ
\epsilon
ϵ,最后得到连续随机变量
y
y
y的概率密度函数:
y
=
f
(
x
,
w
)
+
ϵ
,
ϵ
∈
(
0
,
σ
2
)
y=f(x,w)+\epsilon, \ \ \epsilon\in(0,\sigma^2)
y=f(x,w)+ϵ, ϵ∈(0,σ2)
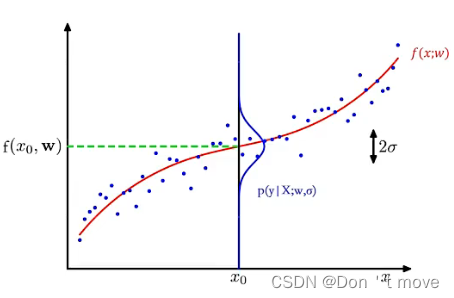
对线性回归来说,
f
(
x
,
w
)
=
w
T
x
f(x,w)=w^Tx
f(x,w)=wTx,于是
y
=
w
T
x
+
ϵ
y=w^Tx+\epsilon
y=wTx+ϵ,移项得
ϵ
=
y
−
w
T
x
\epsilon=y-w^Tx
ϵ=y−wTx,由于
ϵ
\epsilon
ϵ服从高斯分布,它的概率分布函数为:
p
(
ϵ
;
0
,
σ
2
)
=
1
2
π
σ
exp
(
−
(
ϵ
−
0
)
2
2
σ
2
)
=
1
2
π
σ
exp
(
−
(
ϵ
)
2
2
σ
2
)
p(\epsilon;0,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp{(-\frac{(\epsilon-0)^2}{2\sigma^2})}=\frac{1}{\sqrt{2\pi}\sigma}\exp{(-\frac{(\epsilon)^2}{2\sigma^2})}
p(ϵ;0,σ2)=2πσ1exp(−2σ2(ϵ−0)2)=2πσ1exp(−2σ2(ϵ)2)
将
ϵ
=
y
−
w
T
x
\epsilon=y-w^Tx
ϵ=y−wTx带入上式1可得给定
x
x
x下
y
y
y的条件概率:
p
(
y
∣
x
;
w
,
σ
)
=
N
(
y
;
w
T
x
,
σ
2
)
=
1
2
π
σ
exp
(
−
(
y
−
w
T
x
)
2
2
σ
2
)
p(y|x;w,\sigma)=\mathcal{N}(y;w^Tx,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp{(-\frac{(y-w^Tx)^2}{2\sigma^2})}
p(y∣x;w,σ)=N(y;wTx,σ2)=2πσ1exp(−2σ2(y−wTx)2)
这样也可以说
y
y
y是满足均值为
w
T
x
w^Tx
wTx,方差为
σ
2
\sigma^2
σ2的高斯分布,即
y
∈
N
(
w
T
x
,
σ
2
)
y\in\mathcal{N}(w^Tx, \sigma^2)
y∈N(wTx,σ2)。由此得出待优化模型。
似然函数(Likehood)
对于
p
(
x
;
w
)
p(x;w)
p(x;w)来说,概率是指在参数
w
w
w固定的情况下,随机变量
x
x
x的概率分布,即将随机变量
x
x
x看作自变量。而与概率相反,似然指已知随机变量
x
x
x的情况下,不同参数
w
w
w的取值对随机变量
x
x
x取值分布的影响,即将参数
w
w
w看作自变量。
对于线性回归,参数
w
w
w在训练集
D
D
D上的似然函数为:
p
(
y
∣
X
;
w
,
σ
)
=
∏
n
=
1
N
p
(
y
(
n
)
∣
x
(
n
)
;
w
,
σ
)
=
∏
n
=
1
N
N
(
y
(
n
)
;
w
T
x
(
n
)
,
σ
2
)
p(y|X;w,\sigma)=\prod_{n=1}^Np(y^{(n)}|x^{(n)};w,\sigma)=\prod_{n=1}^N\mathcal{N}(y^{(n)};w^Tx^{(n)},\sigma^2)
p(y∣X;w,σ)=n=1∏Np(y(n)∣x(n);w,σ)=n=1∏NN(y(n);wTx(n),σ2)
要特别注意其中的自变量是
w
w
w。此外,
y
=
[
y
(
1
)
⋮
y
(
n
)
]
y=\begin{bmatrix}y^{(1)}\\\vdots\\y^{(n)}\end{bmatrix}
y=
y(1)⋮y(n)
,
X
=
[
x
(
1
)
x
(
2
)
⋯
x
(
n
)
]
X=\begin{bmatrix}x^{(1)}&x^{(2)}&\cdots&x^{(n)}\end{bmatrix}
X=[x(1)x(2)⋯x(n)] ,由于
y
y
y和
X
X
X独立同分布2(这里是默认
X
X
X也服从高斯分布),因此整体的似然函数可以分解为每个样本似然函数的连乘。
最大似然估计(Maximum Likelihood Estimate,MLE)
有了似然函数之后,需要通过一个准则来优化似然函数中的参数
w
w
w,使得似然函数最大,这个过程就是最大似然估计,即找到一组参数
w
w
w使得似然函数
p
(
y
∣
X
;
w
,
σ
)
p(y|X;w,\sigma)
p(y∣X;w,σ)最大。
同时,对于指数型的似然函数(
e
e
e的n次方,即
exp
\exp
exp),通常还会在计算偏导数时加上
log
\log
log(这里的
log
\log
log只是表明是对数函数,不单独指以某个值为底数)转换成对数型的似然函数,转换成对数函数之后,在求偏导数时就能将连乘(
∏
\prod
∏)转换为连加(
∑
\sum
∑),方便下一步计算。同时,由于
exp
(
x
)
\exp(x)
exp(x)和
ln
x
\ln^x
lnx都单调递增,所以二者的复合仍单调递增(同增异减),函数单调性不变,因此极值点不变。
∂
log
p
(
y
∣
X
;
w
,
σ
)
∂
w
=
∂
∂
w
log
(
p
(
y
(
1
)
∣
x
(
1
)
;
w
,
σ
)
⋅
p
(
y
(
1
)
∣
x
(
2
)
;
w
,
σ
)
⋯
p
(
y
(
N
)
∣
x
(
N
)
;
w
,
σ
)
)
=
∂
∂
w
(
log
p
(
y
(
1
)
∣
x
(
1
)
;
w
,
σ
)
+
log
p
(
y
(
1
)
∣
x
(
2
)
;
w
,
σ
)
+
⋯
+
log
p
(
y
(
N
)
∣
x
(
N
)
;
w
,
σ
)
)
)
(假设以
e
为底求导,其他可以参考导数表)
=
1
p
(
y
(
1
)
∣
x
(
1
)
;
w
,
σ
)
∂
p
(
y
(
1
)
∣
x
(
1
)
;
w
,
σ
)
∂
w
+
⋯
+
1
p
(
y
(
N
)
∣
x
(
N
)
;
w
,
σ
)
∂
p
(
y
(
N
)
∣
x
(
N
)
;
w
,
σ
)
∂
w
=
∑
n
=
1
N
1
p
(
y
(
n
)
∣
x
(
n
)
;
w
,
σ
)
∂
p
(
y
(
n
)
∣
x
(
n
)
;
w
,
σ
)
∂
w
=
2
π
σ
1
2
π
σ
∑
n
=
1
N
1
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
∂
∂
w
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
=
−
∑
n
=
1
N
1
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
∂
∂
w
(
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
=
−
∑
n
=
1
N
1
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
(
−
2
(
x
(
n
)
)
T
(
y
(
n
)
−
w
T
x
(
n
)
)
2
σ
2
)
=
∑
n
=
1
N
1
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
(
(
x
(
n
)
)
T
(
y
(
n
)
−
w
T
x
(
n
)
)
σ
2
)
=
1
σ
∑
n
=
1
N
1
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
(
x
(
n
)
)
T
(
y
(
n
)
−
w
T
x
(
n
)
)
=
1
σ
2
∑
n
=
1
N
(
x
(
n
)
)
T
(
y
(
n
)
−
w
T
x
(
n
)
)
=
1
σ
2
X
(
y
−
X
T
w
)
\begin{aligned} \frac{\partial\ \log\ p(y|X;w,\sigma)}{\partial w} &=\frac{\partial}{\partial w}\log{(p(y^{(1)}|x^{(1)};w,\sigma)\cdot p(y^{(1)}|x^{(2)};w,\sigma)\cdots p(y^{(N)}|x^{(N)};w,\sigma))} \\ &=\frac{\partial}{\partial w}(\log\ p(y^{(1)}|x^{(1)};w,\sigma)+\log\ p(y^{(1)}|x^{(2)};w,\sigma)+\cdots+\log\ p(y^{(N)}|x^{(N)};w,\sigma))) \\ &(假设以e为底求导,其他可以参考导数表)\\ &=\frac{1}{p(y^{(1)}|x^{(1)};w,\sigma)}\frac{\partial p(y^{(1)}|x^{(1)};w,\sigma)}{\partial w}+\cdots+\frac{1}{p(y^{(N)}|x^{(N)};w,\sigma)}\frac{\partial p(y^{(N)}|x^{(N)};w,\sigma)}{\partial w}\\ &=\sum_{n=1}^{N}\frac{1}{p(y^{(n)}|x^{(n)};w,\sigma)}\frac{\partial p(y^{(n)}|x^{(n)};w,\sigma)}{\partial w}\\ &={\sqrt{2\pi}\sigma}\frac{1}{\sqrt{2\pi}\sigma}\sum_{n=1}^{N}\frac{1}{\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}}\frac{\partial}{\partial w}\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}\\ &=-\sum_{n=1}^{N}\frac{1}{\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}}\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}\frac{\partial}{\partial w}(\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})\\ &=-\sum_{n=1}^{N}\frac{1}{\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}}\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}(\frac{-2(x^{(n)})^T(y^{(n)}-w^Tx^{(n)})}{2\sigma^2})\\ &=\sum_{n=1}^{N}\frac{1}{\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}}\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}(\frac{(x^{(n)})^T(y^{(n)}-w^Tx^{(n)})}{\sigma^2})\\ &=\frac{1}{\sigma}\sum_{n=1}^{N}\frac{1}{\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}}\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2})}(x^{(n)})^T(y^{(n)}-w^Tx^{(n)})\\ &=\frac{1}{\sigma^2}\sum_{n=1}^{N}(x^{(n)})^T(y^{(n)}-w^Tx^{(n)})\\ &=\frac{1}{\sigma^2}X(y-X^Tw) \end{aligned}
∂w∂ log p(y∣X;w,σ)=∂w∂log(p(y(1)∣x(1);w,σ)⋅p(y(1)∣x(2);w,σ)⋯p(y(N)∣x(N);w,σ))=∂w∂(log p(y(1)∣x(1);w,σ)+log p(y(1)∣x(2);w,σ)+⋯+log p(y(N)∣x(N);w,σ)))(假设以e为底求导,其他可以参考导数表)=p(y(1)∣x(1);w,σ)1∂w∂p(y(1)∣x(1);w,σ)+⋯+p(y(N)∣x(N);w,σ)1∂w∂p(y(N)∣x(N);w,σ)=n=1∑Np(y(n)∣x(n);w,σ)1∂w∂p(y(n)∣x(n);w,σ)=2πσ2πσ1n=1∑Nexp(−2σ2(y(n)−wTx(n))2)1∂w∂exp(−2σ2(y(n)−wTx(n))2)=−n=1∑Nexp(−2σ2(y(n)−wTx(n))2)1exp(−2σ2(y(n)−wTx(n))2)∂w∂(2σ2(y(n)−wTx(n))2)=−n=1∑Nexp(−2σ2(y(n)−wTx(n))2)1exp(−2σ2(y(n)−wTx(n))2)(2σ2−2(x(n))T(y(n)−wTx(n)))=n=1∑Nexp(−2σ2(y(n)−wTx(n))2)1exp(−2σ2(y(n)−wTx(n))2)(σ2(x(n))T(y(n)−wTx(n)))=σ1n=1∑Nexp(−2σ2(y(n)−wTx(n))2)1exp(−2σ2(y(n)−wTx(n))2)(x(n))T(y(n)−wTx(n))=σ21n=1∑N(x(n))T(y(n)−wTx(n))=σ21X(y−XTw)
算到这里可以看出,啊其实不用这么麻烦,直接用
p
(
y
∣
X
;
w
,
σ
)
p(y|X;w,\sigma)
p(y∣X;w,σ)算就行,不用拆开,但是我已经算出来了,那就这样吧。令上式为0
1
p
(
y
∣
X
;
w
,
σ
)
=
0
1
σ
2
X
(
y
−
X
T
w
)
=
0
X
y
−
X
X
T
w
=
0
X
X
T
w
=
X
y
w
=
(
X
X
T
)
−
1
X
y
w
=
(
X
T
)
−
1
y
\begin{aligned} \frac{1}{p(y|X;w,\sigma)}&=0\\ \frac{1}{\sigma^2}X(y-X^Tw)&=0\\ Xy-XX^Tw&=0\\ XX^Tw&=Xy\\ w&=(XX^T)^{-1}Xy\\ w&=(X^T)^{-1}y \end{aligned}
p(y∣X;w,σ)1σ21X(y−XTw)Xy−XXTwXXTwww=0=0=0=Xy=(XXT)−1Xy=(XT)−1y
由此可见最大似然估计的解与经验风险最小化ERM的解相同
从贝叶斯的角度来看线性回归
从贝叶斯的视角来看,需要将可能影响结果的因素作为随机变量添加到计算当中,对于回归问题来说,就是需要将参数
w
w
w也看作随机变量而不是一个给定的参数,将对
w
w
w的估计变成对
w
w
w分布的估计,目标是求在给定观测数据
(
x
,
y
)
(x,y)
(x,y)的条件下
w
w
w的条件概率
p
(
w
∣
x
,
y
)
p(w|x,y)
p(w∣x,y)。这种已知观测数据,由观测数据得到的分布叫做后验分布3;然后,还有先验分布,就是在没有观测数据支持的情况下,直接根据经验给出分布,即
p
(
w
)
p(w)
p(w);最后还有之前提到的似然估计,就是在已知
w
w
w的情况下来估计观测数据
(
x
,
y
)
(x,y)
(x,y)的概率
p
(
x
,
y
∣
w
)
p(x,y|w)
p(x,y∣w)。后验、先验、似然是贝叶斯问题中三个相似的概念,三者都要将回归问题中的
w
w
w作为随机变量。
在回归问题中,为了求解
w
w
w,先验分布、后验分布、似然估计分别表示为
| 先验分布 | 后验分布 | 似然估计 |
|---|---|---|
| p ( w ) p(w) p(w) | p ( w ∣ X , y ) p(w\mid X,y) p(w∣X,y) | p ( y ∣ X , w ) p(y\mid X,w) p(y∣X,w) |
接下来,假设三个随机变量都服从以
v
v
v为均值、
σ
\sigma
σ为方差的分布,根据条件概率公式可得
p
(
w
∣
X
,
y
;
v
,
σ
)
=
p
(
w
,
X
,
y
;
v
,
σ
)
p
(
X
,
y
;
v
,
σ
)
p(w\mid X,y;v,\sigma)=\frac{p(w,X,y;v,\sigma)}{p(X,y;v,\sigma)}
p(w∣X,y;v,σ)=p(X,y;v,σ)p(w,X,y;v,σ)
由概率的乘积的定义可知,
w
,
X
,
y
w,X,y
w,X,y同时发生的概率也就是
p
(
w
,
X
,
y
)
=
p
(
w
)
p
(
X
,
y
∣
w
)
=
p
(
w
)
p
(
X
∣
w
)
p
(
y
∣
X
,
w
)
p(w,X,y)=p(w)p(X,y\mid w) =p(w)p(X\mid w)p(y\mid X,w)
p(w,X,y)=p(w)p(X,y∣w)=p(w)p(X∣w)p(y∣X,w),然后由于在机器学习问题中
X
X
X的取值与
w
w
w无关,所以
p
(
X
∣
w
)
=
p
(
X
)
p(X\mid w)=p(X)
p(X∣w)=p(X),因此
p
(
w
∣
X
,
y
;
v
,
σ
)
=
p
(
w
;
v
,
σ
)
p
(
X
;
v
,
σ
)
p
(
y
∣
X
,
w
;
v
,
σ
)
p
(
X
,
y
;
v
,
σ
)
=
p
(
w
;
v
,
σ
)
p
(
X
;
v
,
σ
)
p
(
y
∣
X
,
w
;
v
,
σ
)
p
(
X
;
v
,
σ
)
p
(
y
∣
X
;
v
,
σ
)
=
p
(
w
;
v
,
σ
)
p
(
y
∣
X
,
w
;
v
,
σ
)
p
(
y
∣
X
;
v
,
σ
)
\begin{aligned} p(w\mid X,y;v,\sigma) &=\frac{p(w;v,\sigma)p(X;v,\sigma)p(y\mid X,w;v,\sigma)}{p(X,y;v,\sigma)}\\ &=\frac{p(w;v,\sigma)p(X;v,\sigma)p(y\mid X,w;v,\sigma)}{p(X;v,\sigma)p(y\mid X;v,\sigma)}\\ &=\frac{p(w;v,\sigma)p(y\mid X,w;v,\sigma)}{p(y\mid X;v,\sigma)}\\ \end{aligned}
p(w∣X,y;v,σ)=p(X,y;v,σ)p(w;v,σ)p(X;v,σ)p(y∣X,w;v,σ)=p(X;v,σ)p(y∣X;v,σ)p(w;v,σ)p(X;v,σ)p(y∣X,w;v,σ)=p(y∣X;v,σ)p(w;v,σ)p(y∣X,w;v,σ)
也可以套贝叶斯公式4得到
p
(
w
∣
X
,
y
)
=
p
(
w
)
p
(
X
,
y
∣
w
)
∑
w
p
(
w
)
p
(
X
,
y
∣
w
)
=
p
(
w
)
p
(
X
∣
w
)
p
(
y
∣
X
,
w
)
∑
w
p
(
w
)
p
(
X
∣
w
)
p
(
y
∣
X
,
w
)
=
p
(
w
)
p
(
X
)
p
(
y
∣
X
,
w
)
∑
w
p
(
w
)
p
(
X
)
p
(
y
∣
X
,
w
)
=
p
(
w
)
p
(
y
∣
X
,
w
)
∑
w
p
(
w
∣
X
)
p
(
y
∣
X
,
w
)
=
p
(
w
)
p
(
y
∣
X
,
w
)
∑
w
p
(
w
,
y
∣
X
)
\begin{aligned} p(w\mid X,y) &=\frac{p(w)p(X,y\mid w)}{\sum_wp(w)p(X,y\mid w)}\\ &=\frac{p(w)p(X\mid w)p(y\mid X,w)}{\sum_wp(w)p(X\mid w)p(y\mid X,w)}\\ &=\frac{p(w)p(X)p(y\mid X,w)}{\sum_wp(w)p(X)p(y\mid X,w)}\\ &=\frac{p(w)p(y\mid X,w)}{\sum_wp(w\mid X)p(y\mid X,w)}\\ &=\frac{p(w)p(y\mid X,w)}{\sum_wp(w,y\mid X)} \end{aligned}
p(w∣X,y)=∑wp(w)p(X,y∣w)p(w)p(X,y∣w)=∑wp(w)p(X∣w)p(y∣X,w)p(w)p(X∣w)p(y∣X,w)=∑wp(w)p(X)p(y∣X,w)p(w)p(X)p(y∣X,w)=∑wp(w∣X)p(y∣X,w)p(w)p(y∣X,w)=∑wp(w,y∣X)p(w)p(y∣X,w)
在实际应用中,通常只关注与之前提到过的后验、先验和似然,从上式可以看出后验分布和先验分布与似然估计的乘积成正比,记作
p
(
w
∣
X
,
y
)
∝
p
(
w
)
p
(
y
∣
X
,
w
)
p(w\mid X,y)\propto p(w)p(y\mid X,w)
p(w∣X,y)∝p(w)p(y∣X,w)。
同样的为了方便计算,将后验分布转换为对数形式计算
log
p
(
w
∣
X
,
y
;
v
,
σ
)
∝
log
(
p
(
w
;
v
,
σ
)
p
(
y
∣
X
,
w
;
v
,
σ
)
)
∝
log
p
(
w
;
v
,
σ
)
+
log
p
(
y
∣
X
,
w
;
v
,
σ
)
\begin{aligned} \log{p(w\mid X,y;v,\sigma)} &\propto\log{(p(w;v,\sigma)p(y\mid X,w;v,\sigma))}\\ &\propto\log{p(w;v,\sigma)}+\log{p(y\mid X,w;v,\sigma)} \end{aligned}
logp(w∣X,y;v,σ)∝log(p(w;v,σ)p(y∣X,w;v,σ))∝logp(w;v,σ)+logp(y∣X,w;v,σ)
假设(先验,所以假设)
w
w
w取值服从以0为均值、方差为
v
2
I
v^2I
v2I(
I
I
I为单位矩阵)的高斯分布,则
p
(
w
;
v
,
σ
)
=
N
(
w
;
0
,
v
2
I
)
=
1
2
π
v
∑
n
=
1
D
exp
(
−
(
w
(
n
)
)
2
2
v
2
)
log
p
(
w
;
v
,
σ
)
=
∑
n
=
1
D
(
log
exp
(
−
(
w
(
n
)
)
2
2
v
2
)
−
1
2
log
2
π
v
2
)
=
∑
n
=
1
D
(
−
(
w
(
n
)
)
2
2
v
2
−
1
2
log
2
π
v
2
)
=
−
1
2
v
2
w
T
w
−
D
2
log
2
π
v
2
\begin{aligned} p(w;v,\sigma) &=\mathcal{N}(w;0,v^2I)\\ &=\frac{1}{\sqrt{2\pi}v}\sum_{n=1}^{D}\exp{(-\frac{(w^{(n)})^2}{2v^2})}\\ \log{p(w;v,\sigma)} &=\sum_{n=1}^D(\log\exp(-\frac{(w^{(n)})^2}{2v^2})-\frac{1}{2}\log2\pi v^2)\\ &=\sum_{n=1}^D(-\frac{(w^{(n)})^2}{2v^2}-\frac{1}{2}\log2\pi v^2)\\ &=-\frac{1}{2v^2}w^Tw-\frac{D}{2}\log2\pi v^2 \end{aligned}
p(w;v,σ)logp(w;v,σ)=N(w;0,v2I)=2πv1n=1∑Dexp(−2v2(w(n))2)=n=1∑D(logexp(−2v2(w(n))2)−21log2πv2)=n=1∑D(−2v2(w(n))2−21log2πv2)=−2v21wTw−2Dlog2πv2
同时,前面在从概率视角看的时候提到过,
y
y
y是服从
N
(
y
;
w
T
x
,
σ
2
)
\mathcal{N}(y;w^Tx,\sigma^2)
N(y;wTx,σ2)的高斯分布(似然),则
p
(
y
∣
X
,
w
;
v
,
σ
)
=
∏
n
=
1
N
N
(
y
(
n
)
;
w
T
x
(
n
)
,
σ
2
)
log
p
(
y
∣
X
,
w
;
v
,
σ
)
=
∑
n
=
1
N
log
(
1
2
π
σ
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
)
=
∑
n
=
1
N
(
log
exp
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
)
−
1
2
log
2
π
σ
2
)
=
∑
n
=
1
N
(
−
(
y
(
n
)
−
w
T
x
(
n
)
)
2
2
σ
2
−
1
2
log
2
π
σ
2
)
=
−
1
2
σ
2
∥
y
−
X
T
w
∥
2
−
N
2
log
2
π
σ
2
\begin{aligned} p(y\mid X,w;v,\sigma) &=\prod_{n=1}^N\mathcal{N}(y^{(n)};w^Tx^{(n)},\sigma^2)\\ \log{p(y\mid X,w;v,\sigma)} &=\sum_{n=1}^N\log(\frac{1}{\sqrt{2\pi}\sigma}\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2}}))\\ &=\sum_{n=1}^N(\log\exp{(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2}})-\frac{1}{2}\log2\pi\sigma^2)\\ &=\sum_{n=1}^N(-\frac{(y^{(n)}-w^Tx^{(n)})^2}{2\sigma^2}-\frac{1}{2}\log2\pi\sigma^2)\\ &=-\frac{1}{2\sigma^2}\parallel y-X^Tw\parallel^2-\frac{N}{2}\log2\pi\sigma^2 \end{aligned}
p(y∣X,w;v,σ)logp(y∣X,w;v,σ)=n=1∏NN(y(n);wTx(n),σ2)=n=1∑Nlog(2πσ1exp(−2σ2(y(n)−wTx(n))2))=n=1∑N(logexp(−2σ2(y(n)−wTx(n))2)−21log2πσ2)=n=1∑N(−2σ2(y(n)−wTx(n))2−21log2πσ2)=−2σ21∥y−XTw∥2−2Nlog2πσ2
代入上面关系式
log
p
(
w
;
v
,
σ
)
+
log
p
(
y
∣
X
,
w
;
v
,
σ
)
=
−
1
2
v
2
w
T
w
−
D
2
log
2
π
v
2
−
1
2
σ
2
∥
y
−
X
T
w
∥
2
−
N
2
log
2
π
σ
2
=
−
1
2
σ
2
∥
y
−
X
T
w
∥
2
−
1
2
v
2
w
T
w
−
C
∝
−
1
2
σ
2
∥
y
−
X
T
w
∥
2
−
1
2
v
2
w
T
w
令
λ
=
σ
2
v
2
,则
v
2
=
σ
2
λ
原式
∝
−
1
2
σ
2
∥
y
−
X
T
w
∥
2
−
λ
2
σ
2
w
T
w
=
−
1
σ
2
(
1
2
∥
y
−
X
T
w
∥
2
+
λ
2
w
T
w
)
∝
1
2
∥
y
−
X
T
w
∥
2
+
λ
2
w
T
w
\begin{aligned} &\ \ \ \ \log{p(w;v,\sigma)}+\log{p(y\mid X,w;v,\sigma)}\\ &=-\frac{1}{2v^2}w^Tw-\frac{D}{2}\log2\pi v^2-\frac{1}{2\sigma^2}\parallel y-X^Tw\parallel^2-\frac{N}{2}\log2\pi\sigma^2\\ &=-\frac{1}{2\sigma^2}\parallel y-X^Tw\parallel^2-\frac{1}{2v^2}w^Tw-C\\ &\propto-\frac{1}{2\sigma^2}\parallel y-X^Tw\parallel^2-\frac{1}{2v^2}w^Tw\\ &令\lambda=\frac{\sigma^2}{v^2},则v^2=\frac{\sigma^2}{\lambda}\\ 原式&\propto-\frac{1}{2\sigma^2}\parallel y-X^Tw\parallel^2-\frac{\lambda}{2\sigma^2}w^Tw\\ &=-\frac{1}{\sigma^2}(\frac{1}{2}\parallel y-X^Tw\parallel^2+\frac{\lambda}{2}w^Tw)\\ &\propto\frac{1}{2}\parallel y-X^Tw\parallel^2+\frac{\lambda}{2}w^Tw \end{aligned}
原式 logp(w;v,σ)+logp(y∣X,w;v,σ)=−2v21wTw−2Dlog2πv2−2σ21∥y−XTw∥2−2Nlog2πσ2=−2σ21∥y−XTw∥2−2v21wTw−C∝−2σ21∥y−XTw∥2−2v21wTw令λ=v2σ2,则v2=λσ2∝−2σ21∥y−XTw∥2−2σ2λwTw=−σ21(21∥y−XTw∥2+2λwTw)∝21∥y−XTw∥2+2λwTw
这里需要解释一下为什么在乘了负号之后仍然成正比:因为本身最优化问题就是求解函数的极值,从极大值变成极小值对于函数来说没有什么影响,所以虽然严格意义上乘以负号之后确实与原函数成反比,但对于最优化问题来说二者是成正比的,其实也可以说对于概率的最优化问题来说,函数乘以任意常数后仍然成正比。
算到这里可以看出实际上贝叶斯回归的待优化函数与带正则化项的结构风险函数是一样的,因此可以说结构风险函数与后验分布成正比,记作
R
^
(
w
)
∝
−
log
p
(
w
)
\hat{R}(w)\propto-\log{p(w)}
R^(w)∝−logp(w)(带不带负号不影响)
有了后验分布,可以通过后验分布得到模型的期望
y
=
E
w
∼
p
(
w
∣
X
,
y
)
[
f
(
X
,
y
,
w
)
]
=
∫
R
f
(
X
,
y
,
w
)
p
(
w
∣
X
,
y
)
d
w
\begin{aligned} y &=\mathbb{E}_{w\sim p(w\mid X,y)}[f(X,y,w)]\\ &=\int_{\mathbb{R}}f(X,y,w)p(w\mid X,y)dw \end{aligned}
y=Ew∼p(w∣X,y)[f(X,y,w)]=∫Rf(X,y,w)p(w∣X,y)dw
这种方法直接通过
w
w
w的后验分布计算得到模型的期望,整个过程中虽然
w
w
w的值都是固定不变的,但每次都需要通过积分去计算期望,无疑加大了计算量。因此,更为可行的方法还是需要计算出参数
w
w
w的期望,在贝叶斯估计中可以用点估计的方法来完成这个操作。
所谓点估计,就是估计出一个实际的点而不是分布,对于机器学习来说,也就是需要通过后验分布来估计出一个最优的参数
w
w
w取值,从而避免直接使用后验分布进行计算,这个过程叫做最大后验估计(Maximum A Posterior Estimation,MAP)
w
M
A
P
=
arg
max
w
p
(
y
∣
X
,
w
;
σ
)
p
(
w
;
v
)
w^{MAP}=\mathop{{\arg\max}}_w\ p(y\mid X,w;\sigma)p(w;v)
wMAP=argmaxw p(y∣X,w;σ)p(w;v)
∂
∂
w
log
(
p
(
y
∣
X
,
w
;
σ
)
p
(
w
;
v
)
)
=
∂
∂
w
(
log
p
(
y
∣
X
,
w
;
σ
)
+
log
p
(
w
;
v
)
)
=
∂
∂
w
(
−
1
2
σ
2
∥
y
−
X
T
w
∥
2
−
N
2
log
2
π
σ
2
−
1
2
v
2
w
T
w
−
D
2
log
2
π
v
2
)
=
∂
∂
w
(
−
1
2
σ
2
(
y
−
X
T
w
)
T
(
y
−
X
T
w
)
−
N
2
log
2
π
σ
2
−
1
2
v
2
w
T
w
−
D
2
log
2
π
v
2
)
=
−
1
σ
2
X
(
y
−
X
T
w
)
−
1
v
2
w
\begin{aligned} &\ \ \ \ \ \frac{\partial}{\partial w}\log (p(y\mid X,w;\sigma)p(w;v))\\ &=\frac{\partial}{\partial w}(\log{p(y\mid X,w;\sigma)}+\log{p(w;v)})\\ &=\frac{\partial}{\partial w}(-\frac{1}{2\sigma^2}\parallel y-X^Tw\parallel^2-\frac{N}{2}\log2\pi\sigma^2-\frac{1}{2v^2}w^Tw-\frac{D}{2}\log2\pi v^2)\\ &=\frac{\partial}{\partial w}(-\frac{1}{2\sigma^2}(y-X^Tw)^T(y-X^Tw)-\frac{N}{2}\log2\pi\sigma^2-\frac{1}{2v^2}w^Tw-\frac{D}{2}\log2\pi v^2)\\ &=-\frac{1}{\sigma^2}X(y-X^Tw)-\frac{1}{v^2}w \end{aligned}
∂w∂log(p(y∣X,w;σ)p(w;v))=∂w∂(logp(y∣X,w;σ)+logp(w;v))=∂w∂(−2σ21∥y−XTw∥2−2Nlog2πσ2−2v21wTw−2Dlog2πv2)=∂w∂(−2σ21(y−XTw)T(y−XTw)−2Nlog2πσ2−2v21wTw−2Dlog2πv2)=−σ21X(y−XTw)−v21w
−
1
σ
2
X
(
y
−
X
T
w
)
−
1
v
2
w
=
0
−
1
σ
2
X
y
+
1
σ
2
X
X
T
w
−
1
v
2
w
=
0
(
1
σ
2
X
X
T
−
1
v
2
)
w
=
1
σ
2
X
y
(
X
X
T
−
σ
2
v
2
)
w
=
X
y
w
=
(
X
X
T
−
σ
2
v
2
)
−
1
X
y
\begin{aligned} -\frac{1}{\sigma^2}X(y-X^Tw)-\frac{1}{v^2}w&=0\\ -\frac{1}{\sigma^2}Xy+\frac{1}{\sigma^2}XX^Tw-\frac{1}{v^2}w&=0\\ (\frac{1}{\sigma^2}XX^T-\frac{1}{v^2})w&=\frac{1}{\sigma^2}Xy\\ (XX^T-\frac{\sigma^2}{v^2})w&=Xy\\ w&=(XX^T-\frac{\sigma^2}{v^2})^{-1}Xy \end{aligned}
−σ21X(y−XTw)−v21w−σ21Xy+σ21XXTw−v21w(σ21XXT−v21)w(XXT−v2σ2)ww=0=0=σ21Xy=Xy=(XXT−v2σ2)−1Xy
即
w
M
A
P
=
(
X
X
T
−
σ
2
v
2
)
−
1
X
y
w^{MAP}=(XX^T-\frac{\sigma^2}{v^2})^{-1}Xy
wMAP=(XXT−v2σ2)−1Xy(视频里错了,这里有个算的一样的5),也就是说最大后验估计的结果与结构风险最小化SRM结果一致。
















 947
947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











