







前言
Deepsort之所以可以大量避免IDSwitch,是因为Deepsort算法中特征提取网络可以将目标检测框中的特征提取出来并保存,在目标被遮挡后又从新出现后,利用前后的特征对比可以将遮挡的后又出现的目标和遮挡之前的追踪的目标重新找到,大大减少了目标在遮挡后,追踪失败的可能。
一、数据集简介
Market-1501 数据集在清华大学校园中采集,夏天拍摄,在 2015 年构建并公开。它包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄到的 1501 个行人、32668 个检测到的行人矩形框。每个行人至少由2个摄像头捕获到,并且在一个摄像头中可能具有多张图像。训练集有 751 人,包含 12,936 张图像,平均每个人有 17.2 张训练数据;测试集有 750 人,包含 19,732 张图像,平均每个人有 26.3 张测试数据。3368 张查询图像的行人检测矩形框是人工绘制的,而 gallery 中的行人检测矩形框则是使用DPM检测器检测得到的。
该数据集提供的固定数量的训练集和测试集均可以在single-shot或multi-shot测试设置下使用。
目录结构
Market-1501-v15.09.15
├── bounding_box_test
├── 0000_c1s1_000151_01.jpg
├── 0000_c1s1_000376_03.jpg
├── 0000_c1s1_001051_02.jpg
├── bounding_box_train
├── 0002_c1s1_000451_03.jpg
├── 0002_c1s1_000551_01.jpg
├── 0002_c1s1_000801_01.jpg
├── gt_bbox
├── 0001_c1s1_001051_00.jpg
├── 0001_c1s1_009376_00.jpg
├── 0001_c2s1_001976_00.jpg
├── gt_query
├── 0001_c1s1_001051_00_good.mat
├── 0001_c1s1_001051_00_junk.mat
├── query
├── 0001_c1s1_001051_00.jpg
├── 0001_c2s1_000301_00.jpg
├── 0001_c3s1_000551_00.jpg
└── readme.txt
目录介绍
(1) “bounding_box_test”——用于测试集的 750 人,包含 19,732 张图像,前缀为 0000 表示在提取这 750 人的过程中DPM检测错的图(可能与query是同一个人),-1 表示检测出来其他人的图(不在这 750 人中)
(2) “bounding_box_train”——用于训练集的 751 人,包含 12,936 张图像
(3) “query”——为 750 人在每个摄像头中随机选择一张图像作为query,因此一个人的query最多有 6 个,共有 3,368 张图像
(4) “gt_query”——matlab格式,用于判断一个query的哪些图片是好的匹配(同一个人不同摄像头的图像)和不好的匹配(同一个人同一个摄像头的图像或非同一个人的图像)
(5) “gt_bbox”——手工标注的bounding box,用于判断DPM检测的bounding box是不是一个好的box
命名规则
以 0001_c1s1_000151_01.jpg 为例
1) 0001 表示每个人的标签编号,从0001到1501;
2) c1 表示第一个摄像头(camera1),共有6个摄像头;
3) s1 表示第一个录像片段(sequece1),每个摄像机都有数个录像段;
4) 000151 表示 c1s1 的第000151帧图片,视频帧率25fps;
5) 01 表示 c1s1_001051 这一帧上的第1个检测框,由于采用DPM检测器,对于每一帧上的行人可能会框出好几个bbox。00 表示手工标注框
二、跟踪模型介绍
特征提取的模型有很多,可以替换特征提取模型网络。
下述给出的是 deep_sort/deep/model.py 里面的模型代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, c_in, c_out, is_downsample=False):
super(BasicBlock, self).__init__()
self.is_downsample = is_downsample
if is_downsample:
self.conv1 = nn.Conv2d(
c_in, c_out, 3, stride=2, padding=1, bias=False)
else:
self.conv1 = nn.Conv2d(
c_in, c_out, 3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(c_out)
self.relu = nn.ReLU(True)
self.conv2 = nn.Conv2d(c_out, c_out, 3, stride=1,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(c_out)
if is_downsample:
self.downsample = nn.Sequential(
nn.Conv2d(c_in, c_out, 1, stride=2, bias=False),
nn.BatchNorm2d(c_out)
)
elif c_in != c_out:
self.downsample = nn.Sequential(
nn.Conv2d(c_in, c_out, 1, stride=1, bias=False),
nn.BatchNorm2d(c_out)
)
self.is_downsample = True
def forward(self, x):
y = self.conv1(x)
y = self.bn1(y)
y = self.relu(y)
y = self.conv2(y)
y = self.bn2(y)
if self.is_downsample:
x = self.downsample(x)
return F.relu(x.add(y), True)
def make_layers(c_in, c_out, repeat_times, is_downsample=False):
blocks = []
for i in range(repeat_times):
if i == 0:
blocks += [BasicBlock(c_in, c_out, is_downsample=is_downsample), ]
else:
blocks += [BasicBlock(c_out, c_out), ]
return nn.Sequential(*blocks)
class Net(nn.Module):
def __init__(self, num_classes=751, reid=False):
super(Net, self).__init__()
# 3 128 64
self.conv = nn.Sequential(
nn.Conv2d(3, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# nn.Conv2d(32,32,3,stride=1,padding=1),
# nn.BatchNorm2d(32),
# nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, padding=1),
)
# 32 64 32
self.layer1 = make_layers(64, 64, 2, False)
# 32 64 32
self.layer2 = make_layers(64, 128, 2, True)
# 64 32 16
self.layer3 = make_layers(128, 256, 2, True)
# 128 16 8
self.layer4 = make_layers(256, 512, 2, True)
# 256 8 4
self.avgpool = nn.AvgPool2d((8, 4), 1)
# 256 1 1
self.reid = reid
self.classifier = nn.Sequential(
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, num_classes),
)
def forward(self, x):
x = self.conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
# B x 128
if self.reid:
x = x.div(x.norm(p=2, dim=1, keepdim=True))
return x
# classifier
x = self.classifier(x)
return x
if __name__ == '__main__':
net = Net()
x = torch.randn(4, 3, 128, 64)
y = net(x)
import ipdb
ipdb.set_trace()三、数据集处理
splitDataset.py
用于存放训练的图片
# -*- coding:utf-8 -*-
# @author: 牧锦程
# @微信公众号: AI算法与电子竞赛
# @Email: m21z50c71@163.com
# @VX:fylaicai
import os
from shutil import copyfile
# You only need to change this line to your dataset download path
download_path = 'Market-1501-v15.09.15'
if not os.path.isdir(download_path):
print('please change the download_path')
save_path = 'pytorch'
if not os.path.isdir(save_path):
os.mkdir(save_path)
# ------------------- query ----------------------
query_path = download_path + '/query'
query_save_path = save_path + '/query'
print("process: ", query_path)
if not os.path.isdir(query_save_path):
os.mkdir(query_save_path)
for root, dirs, files in os.walk(query_path, topdown=True):
for name in files:
if not name[-3:] == 'jpg':
continue
ID = name.split('_')
src_path = query_path + '/' + name
dst_path = query_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
# ----------------- multi-query ------------------------
query_path = download_path + '/gt_bbox'
print("process: ", query_path)
# for dukemtmc-reid, we do not need multi-query
if os.path.isdir(query_path):
query_save_path = save_path + '/multi-query'
if not os.path.isdir(query_save_path):
os.mkdir(query_save_path)
for root, dirs, files in os.walk(query_path, topdown=True):
for name in files:
if not name[-3:] == 'jpg':
continue
ID = name.split('_')
src_path = query_path + '/' + name
dst_path = query_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
# ------------------- gallery ----------------------
gallery_path = download_path + '/bounding_box_test'
gallery_save_path = save_path + '/gallery'
print("process: ", gallery_path)
if not os.path.isdir(gallery_save_path):
os.mkdir(gallery_save_path)
for root, dirs, files in os.walk(gallery_path, topdown=True):
for name in files:
if not name[-3:] == 'jpg':
continue
ID = name.split('_')
src_path = gallery_path + '/' + name
dst_path = gallery_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
# ------------------ train ---------------------
train_path = download_path + '/bounding_box_train'
train_save_path = save_path + '/train'
val_save_path = save_path + '/test'
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
os.mkdir(val_save_path)
print("process: ", train_path)
for root, dirs, files in os.walk(train_path, topdown=True):
for name in files:
if not name[-3:] == 'jpg':
continue
ID = name.split('_')
src_path = train_path + '/' + name
dst_path = train_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
# first image is used as val image
dst_path = val_save_path + '/' + ID[0]
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)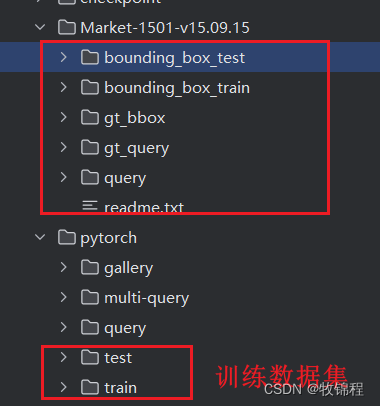
四、模型训练
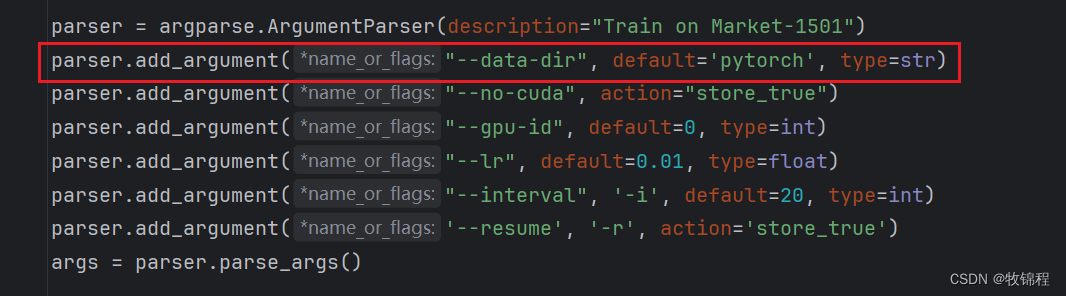
修改数据集路径
修改 data-dir 参数为自己的数据集路径
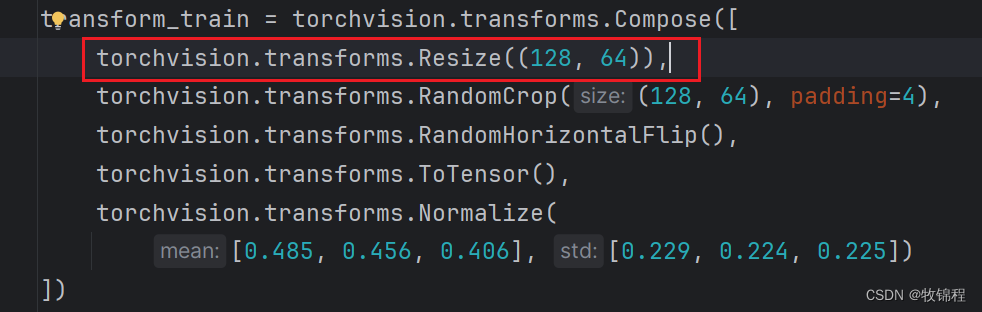
修改数据增强
增加一个尺寸修改
修改类别数量
代码中通过dataloader来获取,因此可以不进行修改
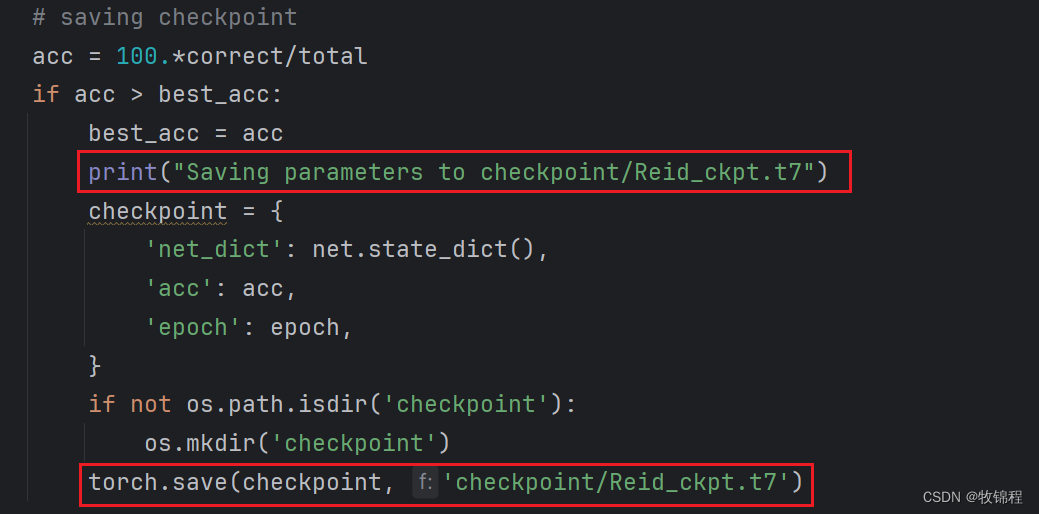
num_classes = max(len(trainloader.dataset.classes), len(testloader.dataset.classes))修改保存模型名称
这里的修改是为例与原始的模型进行区分,可以做对比
训练结果
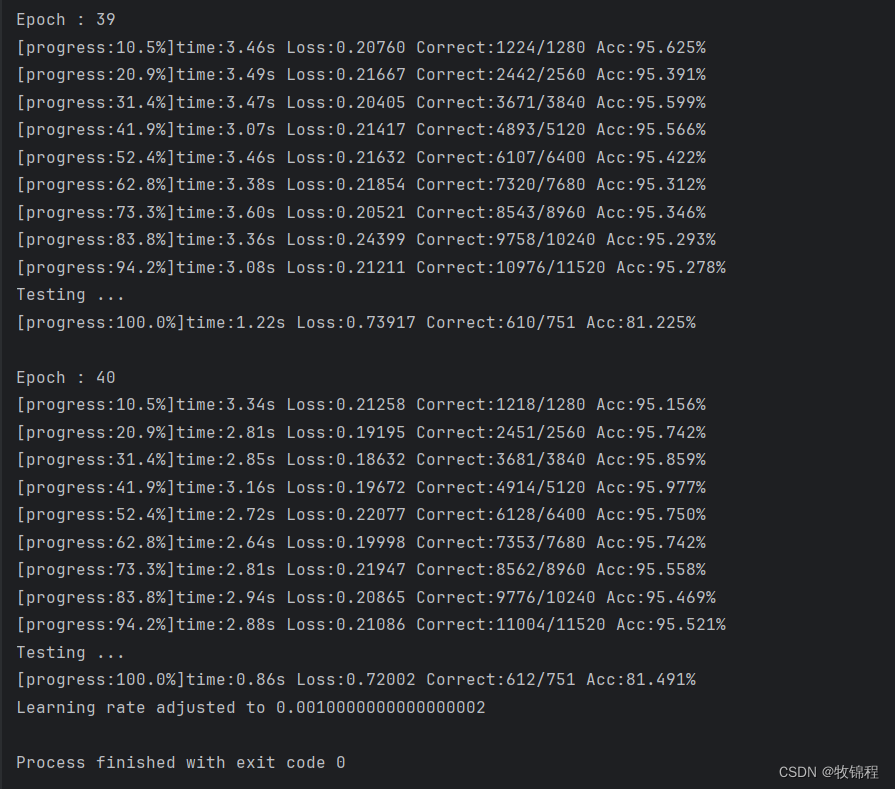
查看精度
先运行test.py,生成 features.pth

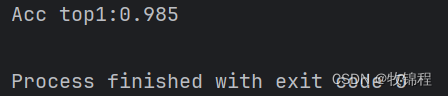
 在运行 evaluate.py,得到如下精度:
在运行 evaluate.py,得到如下精度:
五、链接作者
欢迎关注我的公众号:@AI算法与电子竞赛
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!
















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











